标签:ESS max gecko 成功 回滚 code efi 个人 模板文件
"
基于终端指令的持久化存储
前提:保证爬虫文件中的parse方法的返回值为可迭代数据类型(通常为list/dict)。
该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化存储。
执行如下命令进行持久化存储:
scrapy crawl 应用名称 -o xx.文件格式
其支持的文件格式有:‘json‘, ‘jsonlines‘, ‘jl‘, ‘csv‘, ‘xml‘, ‘marshal‘, ‘pickle‘
基于管道的持久化存储
Scrapy框架为我们提供了高效、便捷的持久化操作功能,我们直接使用即可。
在使用之前,我们先来认识下这两个文件:
- items.py:数据结构模板文件,用于定义数据属性。
- pipelines.py:管道文件,接收数据(items),进行持久化操作。
---------------------------↓
持久化流程:
- 应用文件爬取到数据后,将数据封装到items对象中。
- 使用yield关键字将items对象提交给pipelines管道进行持久化操作。
- 在管道文件中的类中的process_item方法接收爬虫文件提交过来的item对象,
然后编写持久化存储的代码将item对象中存储的数据进行持久化存储。
注意:
- 在settings.py配置文件中开启管道配置的字典:ITEM_PIPELINES
- 在items.py数据结构模板文件中定义好要持久化的字段
---------------------------↑
示例
下面将爬取你的CSDN博客中所有文章和URL的对应关系,并进行持久化存储。
第一步,我们先写好应用文件blog.py:import scrapy from Test.items import TestItem class BlogSpider(scrapy.Spider): name = 'blog' # 应用名称 start_urls = ['https://blog.csdn.net/qq_41964425/article/list/1'] # 起始url page = 1 # 用于计算页码数 max_page = 7 # 你的CSDN博客一共有多少页博文 url = 'https://blog.csdn.net/qq_41964425/article/list/%d' # 用于定位页码的url def parse(self, response): """ 访问起始url页面并获取结果后的回调函数 一般情况下,你写了多少个起始url,此方法就会被调用多少次 :param response: 向起始URL发送请求后,获取的响应对象 :return: 此方法的返回值必须为 可迭代对象(通常为list/dict) 或 None """ # 定位到当期页面中所有博文的链接(a标签) a_list = response.xpath('//div[@class="article-list"]/div/h4/a') # type: list # 每个人的博客,每一页的都有这篇文章,你打开网页源码看看就知道了 a_list.pop(0) # 帝都的凛冬 https://blog.csdn.net/yoyo_liyy/article/details/82762601 # 开始解析处理博客数据 for a in a_list: # 准备一个item对象 item = TestItem() # 保存数据 item['title'] = a.xpath('.//text()')[-1].extract().strip() # 获取文章标题 item['url'] = a.xpath('.//@href').extract_first() # 获取文章url # 下面将解析到的数据存储到item对象中 # 最后,将itme对象提交给管道进行持久化存储 yield item # 开始爬取所有页面 if self.page < self.max_page: self.page += 1 current_page = format(self.url % self.page) # 当前的要爬取的url页面 # 手动发送请求 yield scrapy.Request(url=current_page, callback=self.parse) # callback用于指定回调函数,即指定解析的方法 # 1.如果页面内容与起始url的内容一致,可使用同一个解析方法(self.parse) # 2.如果页面的内容不一致,需手动创建新的解析方法,可见下面 def dem(self, response): """ 2.如果页面的内容不一致,需手动创建新的解析方法 注意:解析方法必须接收response对象 """ pass第二步,在数据结构模板文件items.py中准备好要保存的字段:
import scrapy class TestItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() # 文章标题 url = scrapy.Field() # 文章url第三步,在管道文件pipelines.py中写持久化的逻辑:
class TestPipeline(object): def process_item(self, item, spider): """应用文件每提交一次item,该方法就会被调用一次""" # 保存数据到文件 self.fp.write(item['title'] + '\t' + item['url'] + '\n') # 你一定要注意: # 此方法一定要返回itme对象,用于传递给后面的(优先级低的)管道类中的此方法 # 关于优先级的高低,可在settings.py文件中的ITEM_PIPELINES字典中定义 return item # 重写父类方法,用于打开文件 def open_spider(self, spider): """此方法在运行应用时被执行,注意:只会被执行一次""" print('开始爬取') self.fp = open('text.txt', 'w', encoding='utf-8') # 重写父类方法,用于关闭文件 def close_spider(self, spider): """此方法结束应用时被执行,注意:只会被执行一次""" print('爬取结束') self.fp.close()第四步,在配置文件settings.py中打开如下配置项:
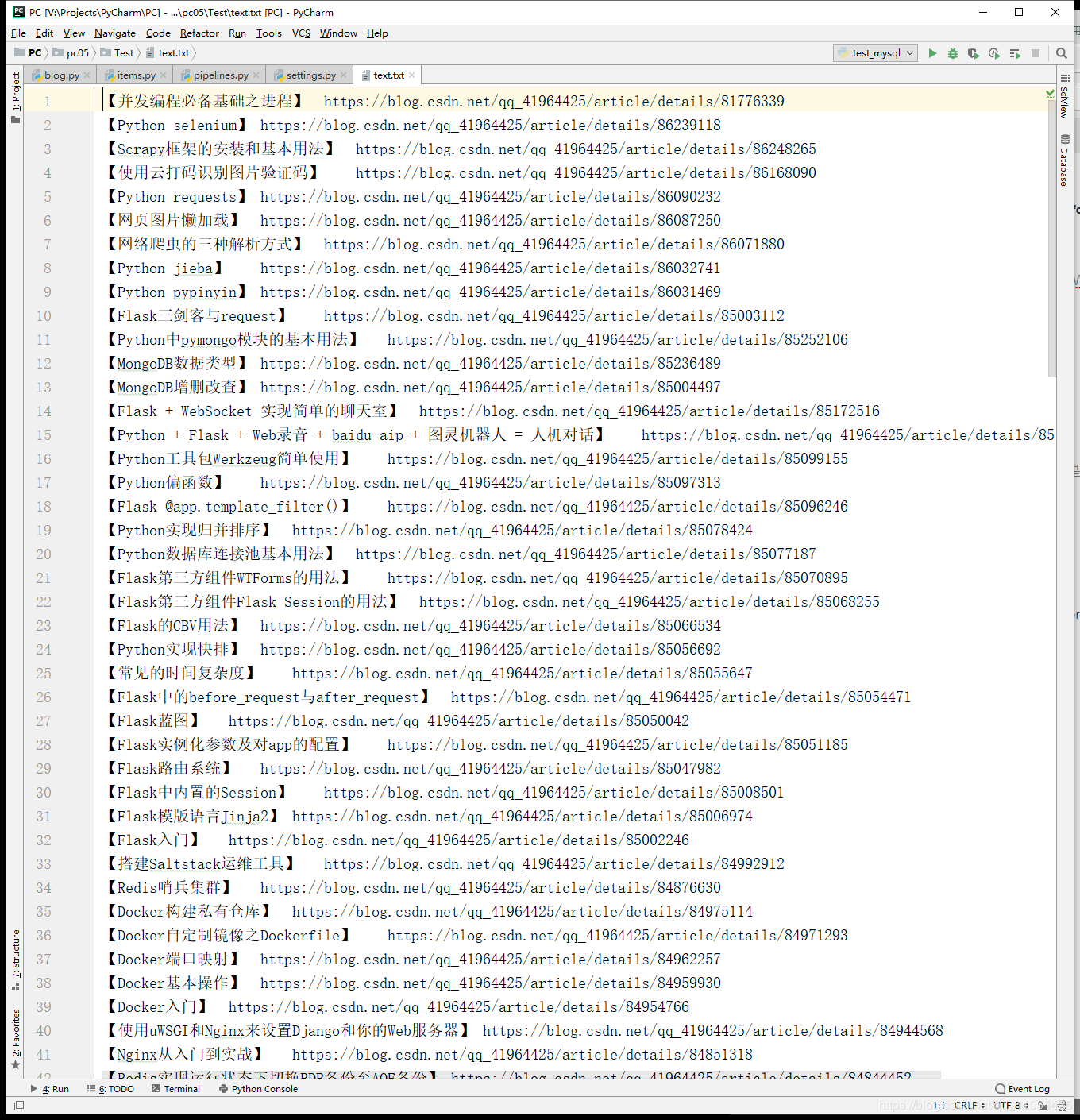
# 伪装请求载体身份(User-Agent) USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # 是否遵守robots协议 ROBOTSTXT_OBEY = False # 开启管道 ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是优先级,数值越小优先级越高,优先级高的先执行 # 自定义的管道类添加到此字典时才会被调用 }第五步,在终端输入执行命令:scrapy crawl blog,执行成功后,我们打开文件来看看:
怎么样,是不是像下面这样。
哈哈哈。
不慌,我们不仅可以将数据持久化到文件,还可以将数据持久化到数据库中(比如下面的MySQL、Redis)。
---------------------------------------↓
持久化存储到 MySQL# pipelines.py文件 import pymysql # 自定义管道类,用于将数据写入MySQL # 注意了: # 自定义的管道类需要在settings.py文件中的ITEM_PIPELINES字典中注册后才会被调用 # 而调用的顺序取决于注册时指定的优先级 class TestPipeLineByMySQL(object): # 重写父类方法,用于建立MySQL链接,并创建一个游标 def open_spider(self, spider): """此方法在运行应用时被执行,注意:只会被执行一次""" self.conn = pymysql.connect( host='localhost', port=3306, user='zyk', password='user@zyk', db='blog', # 指定你要使用的数据库 charset='utf8', # 指定数据库的编码 ) # 建立MySQL链接 self.cursor = self.conn.cursor() # 创建游标 # 本人实测:这里并发使用同一个游标没有出现问题 def process_item(self, item, spider): sql = 'insert into info(title, url) values (%s, %s)' # 要执行的sql语句 # 开始执行事务 try: self.cursor.execute(sql, (item['title'], item['url'])) # 增 self.conn.commit() # 提交 except Exception as e: print(e) self.conn.rollback() # 回滚 return item # 你一定要注意: # 此方法一定要返回itme对象,用于传递给后面的(优先级低的)管道类中的此方法 # 关于优先级的高低,可在settings.py文件中的ITEM_PIPELINES字典中定义 # 重写父类方法,用于关闭MySQL链接 def close_spider(self, spider): """此方法在结束应用时被执行,注意:只会被执行一次""" self.cursor.close() self.conn.close()写完后别忘了在配置文件settings.py中添加此管道类:
ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是优先级,数值越小优先级越高,优先级高的先执行 'Test.pipelines.TestPipeLineByMySQL': 400, # 自定义的管道类添加到此字典时才会被调用 }
---------------------------------------↓
持久化存储到 Redis# pipelines.py文件 import redis import json # 自定义管道类,用于将数据写入Redis # 注意了: # 自定义的管道类需要在settings.py文件中的ITEM_PIPELINES字典中注册后才会被调用 # 而调用的顺序取决于注册时指定的优先级 class TestPipelineByRedis(object): # 重写父类方法,用于创建Redis连接实例 def open_spider(self, spider): """此方法在运行应用时被执行,注意:只会被执行一次""" # 创建Redis连接实例 self.conn = redis.Redis(host='localhost', port=6379, password='', decode_responses=True, db=15) # decode_responses=True 写入的键值对中的value为字符串类型,否则为字节类型 # db=15 表示使用第15个数据库 def process_item(self, item, spider): dct = { 'title': item['title'], 'url': item['url'] } # 将数据持久化至Redis self.conn.lpush('blog_info', json.dumps(dct, ensure_ascii=False)) # ensure_ascii=False 这样可使取数据时显示的为中文 return item # 你一定要注意: # 此方法一定要返回itme对象,用于传递给后面的(优先级低的)管道类中的此方法 # 关于优先级的高低,可在settings.py文件中的ITEM_PIPELINES字典中定义跟上面一样,在配置文件settings.py中添加此管道类:
ITEM_PIPELINES = { 'Test.pipelines.TestPipeline': 300, # 300表示的是优先级,数值越小优先级越高,优先级高的先执行 'Test.pipelines.TestPipelineByMySQL': 400, # 自定义的管道类添加到此字典时才会被调用 'Test.pipelines.TestPipelineByRedis': 500, # 自定义的管道类添加到此字典时才会被调用 }在Redis中查询持久化的数据:
lrange blog_info 0 -1
"
标签:ESS max gecko 成功 回滚 code efi 个人 模板文件
原文地址:https://www.cnblogs.com/bbb001/p/11373909.html