标签:上启 初始 dir ali inf table limit 服务器 com
搭建一个3机器的集群,即zookeeper要安装在3台主机中,每台主机要安装好jdk。
1.上传zookeeper文件并解压
2.修改环境变量
vi /etc/profile
添加内容:
|
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5 export PATH=$PATH:$ZOOKEEPER_HOME/bin |
重新编译文件:
source /etc/profile
注意:3台zookeeper都需要修改
3.修改zookeeper的配置文件
cd zookeeper-3.4.5/conf
cp zoo_sample.cfg zoo.cfg # 拷贝一份zoo_sample.cfg,命名为zoo.cfg
vi zoo.cfg
zoo.cfg文件的内容如下:
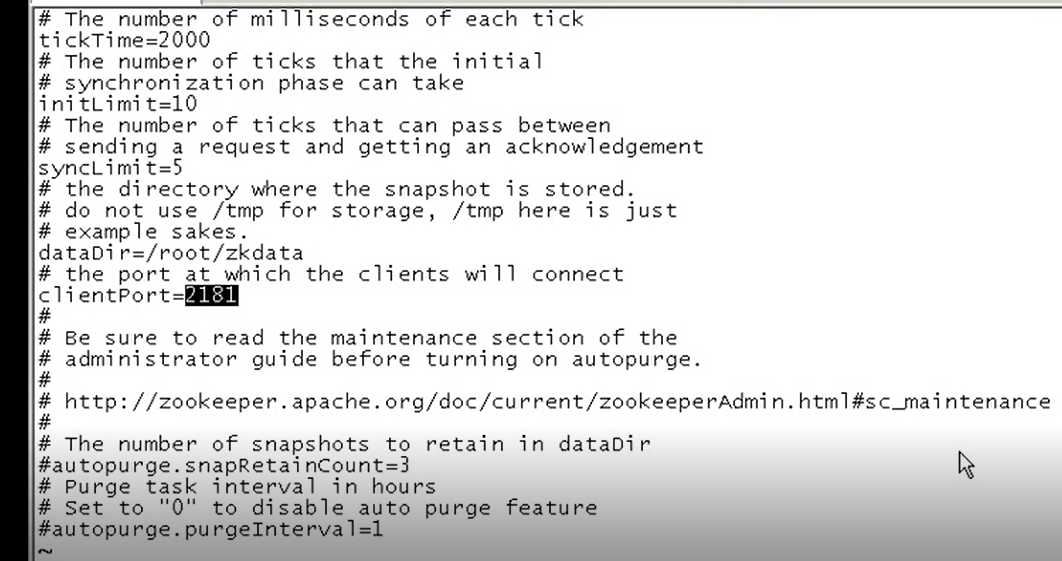
tickTime:心跳检测的周期 initLimit:初始化花费多少个心跳时间
syncLimit:发出请求到获取响应间的最大时差,若超出该时差就认为请求没有得到对方的响应,对方可能挂了
dataDir:数据目录,保存数据 clientPort:客户端访问zookeeper的端口
添加内容:
|
dataDir=/home/hadoop/zookeeper-3.4.5/data dataLogDir=/home/hadoop/zookeeper-3.4.5/log server.1=slave1:2888:3888 (server.服务器id=主机名/主机ip地址:心跳端口:数据端口) server.2=slave2:2888:3888 server.3=slave3:2888:3888 # 2888:leader和follower之间通信的端口 # 3888:投票选举leader时的通信端口 |
4.创建数据目录和日志目录
cd /home/hadoop/zookeeper-3.4.5/
mkdir -m 755 data
mkdir -m 755 log
5.把id记录到数据目录中去
在3台机器的数据目录下新建myid文件,myid的文件内容为本机器作为zookeeper节点的id
对于第一台:
cd data
vi myid
添加内容
|
1 |
或者直接echo 1 > myid
其余两台类似
6.将集群下发到其他机器上
scp -r /home/hadoop/zookeeper-3.4.5 hadoop@slave2:/home/hadoop/
# 把/home/hadoop/zookeeper-3.4.5目录以hadoop的名义拷贝到slave主机的/home/hadoop目录下
scp -r /home/hadoop/zookeeper-3.4.5 hadoop@slave3:/home/hadoop/
7.关闭防火墙
集群一般不会暴露给外界,故3台机器都关闭所有端口的防火墙
service iptables stop
8.在所有机器上启动zookeeper
进入zookeeper-3.4.5/bin
zkServer.sh start
9.查看集群状态
(1)jps(查看进程)
(2)zkServer.sh status(查看集群状态,主从信息,首先进入到zookeeper-3.4.5/bin,如果集群不能正常运行,会在此命令下有错误提示)
标签:上启 初始 dir ali inf table limit 服务器 com
原文地址:https://www.cnblogs.com/paradis/p/11373908.html