标签:http 安全 连续 思想 for 未来 ide 过拟合 区间
遗传算法 一次次求得最优解
进化策略 有效避免局部最优(过拟合) 并行能力计算
什么都不懂->找到规律 给你的行为打分
核心思想:同样的行为拿到高分,并避免低分的行为 分数导向性

不理解环境:从环境中得到反馈
理解环境:为现实世界建模,多出来个虚拟环境
通过过往的经验理解现实世界是怎样的,并建立一个模型来模拟现实世界的反馈 现实模拟两世界中都可以玩耍
通过想象来预判要发生的所有情况,根据想象中的情况选择最好的那种,并根据这种情况来采取下一步的策略
基于概率 Policy Gradients
通过感官分析所处的环境,直接算出下一步采取行动的概率,根据概率采取行动,每一种动作都可能被选中,只是可能性不同
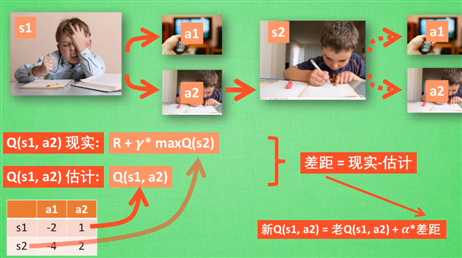
基于价值:决策部分更为肯定,毫不留情就选价值最高的 (连续的动作无能为力)Q Learning Sarsa
Actor-Critic 基于概率做出动作,并对做出的动作给出动作的价值
off-policy 不怕死

greedy 决策上的一种策略
a 学习效率 决定这次误差有多少要被学习 <1
y 未来奖励的衰减值
![]()
on-policy 在线学习 单步更新 更保守、安全
Sarsa(lambda) 更行选择的步数 衰变值
lambda 0为单步更新1为回合更新 介于0~1之间 (离宝藏越近更新力度越大)
回合更新:走的步数都是为了得到宝藏所要学习的步
直接输出动作 连续区间内选择动作
误差反相传递 增加被选的概率 奖惩
标签:http 安全 连续 思想 for 未来 ide 过拟合 区间
原文地址:https://www.cnblogs.com/zhang1422749310/p/11378735.html