标签:obs nbsp 测试数据 增加 它的 16px ima rand 学习任务
//2019.08.19
#机器学习集成学习
1、集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常广泛。
集成学习(ensemble learning)本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等,可以说所有的机器学习领域都可以看到集成学习的身影。
生活中其实也普遍存在集成学习的方法,比如买东西找不同的人进行推荐,病情诊断进行多专家会诊等,考虑各方面的意见进行最终的综合的决策,这样得到的结果可能会更加的全面和准确。
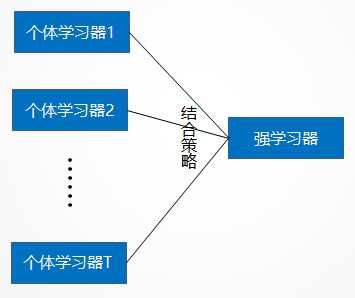
下图概括了集成学习的思想。对于训练集数据,我们通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的。

2、集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
3、sklearn中也提供了集成学习的接口voting classifier。
4、对于集成学习的算法,里面有一个参数voting,它是指集成学习的投票原则,一般具有两种计算原则:
(1)hard voting :少数服从多数的原则,人人投票平等没有差异;

(2)soft voting:具有权重的算法服从原则,不同的算法模型根据其专业性选取不同的权重
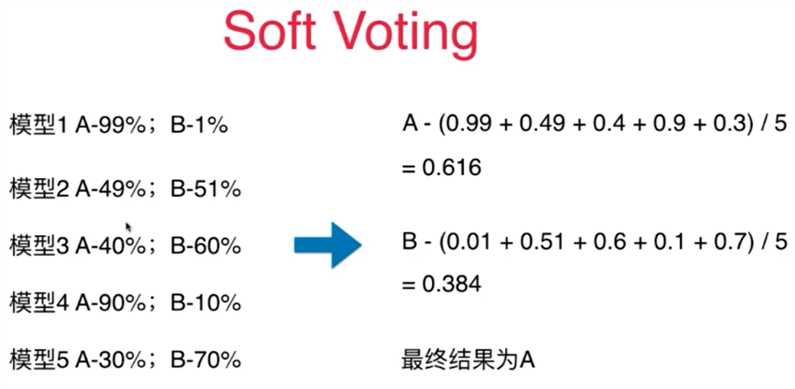
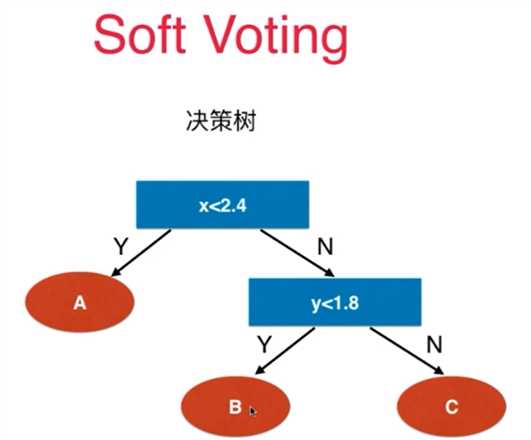
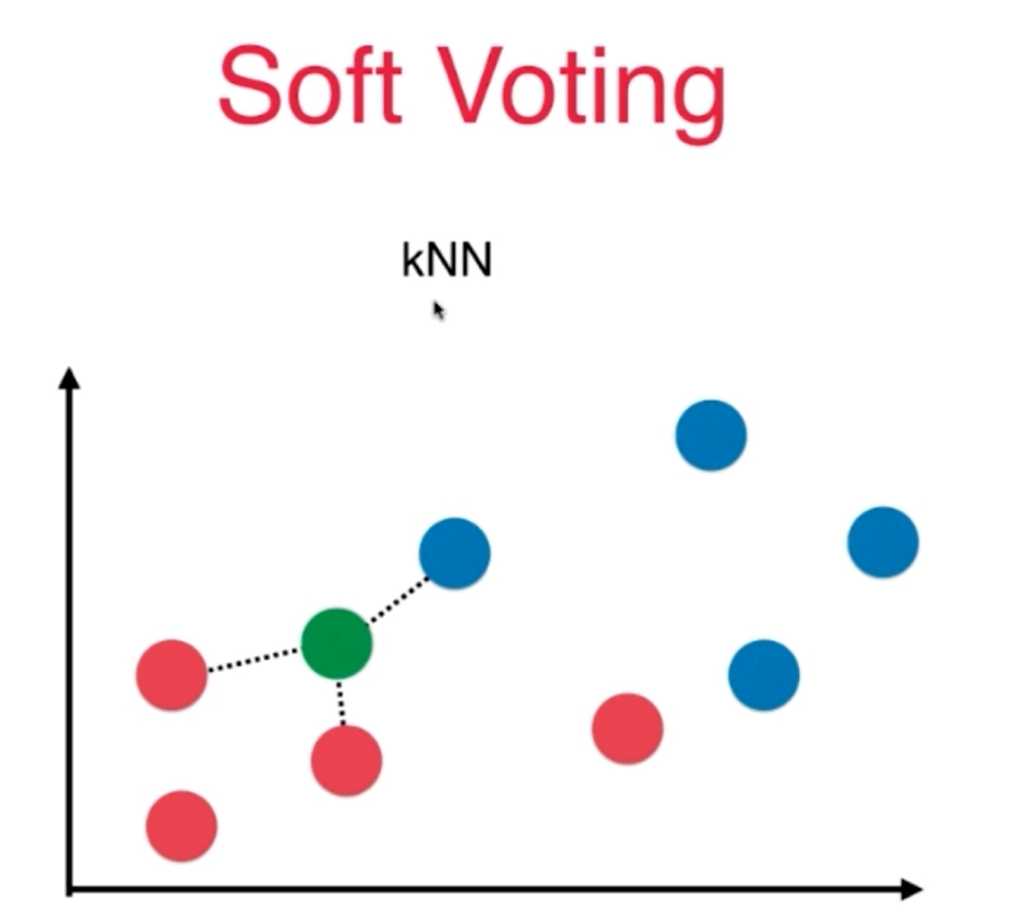
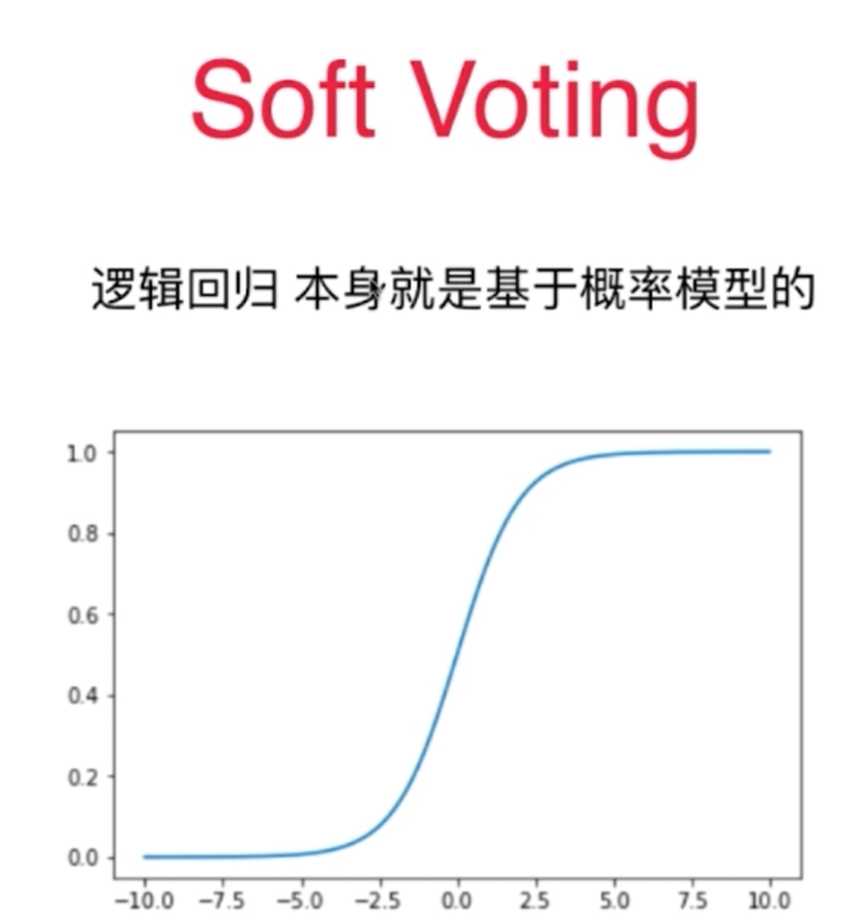
5、softvotiing的投票原则必须保证算法具有预测概率的性质:SVC(probability=True)、kNN,逻辑回归,决策树等
6、集成学习的准确度很大程度上取决于所建立的子模型的数量,子模型的数目越多,集成学习的准确度也将越高;而不同的子模型一定要存在一定的差异。对于子模型之间的差异如何创建,主要有两种思路:
(1)增加机器学习的算法数目
(2)每个机器学习算法只看模型的一部分数据。


其中,就第一种思路来讲,对于机器学习算法,其数目是有限的,远远达不到我们所期望达到的数目,所以一般辅助使用,而第二种思路是目前集成学习的主要思路,对于相同的机器学习算法使用同样的基础数据集,但是每个子模型只看其中数据的一部分数据,这样同一种机器学习算法也会训练出来很多种子模型,当然这样也因为只是选取数据一部分的原因而降低子模型算法的准确度,但是这并没有多大的关系,因为集成学习中对于子模型的概率没有太高的要求,可以达到60%以上便可,通过多个模型投票累积便可以形成非常强大准确的集成学习算法(比如500个数据样本,如果每个子模型看其中的100个样本,并且每个子模型的概率都可以达到60%,那么集成学习的理论预测概率就会到99.9%)


图
7、对于集成学习的子模型在选取数据集的部分样本数据时有两种方式:放回取样bagging(统计学中将其称为bootstrap)和pasting不放回取样。其中放回取样baging更加常用,它的随机性更加好,所以一般情况下综合效果最好。
8、sklearn中集成学习的算法,主要的超参数有:
(1)集成学习机器学习算法的种类
(2)n_estimators:创建训练子模型的数目(机器算法创建子模型数目)
(3)max_samples:每次子模型所取基础数据集的样本数目(样本数据随机)
(4)bootstrap(=True):有无放回取样
(5)n_jobs(=-1):子模型训练时所用的内核数目,主要用来提高运算效率
(6)max_features:每次从样本中随机取的最大特征数目(特征随机)
(7)bootstrap_features(=True):选取特征时有无放回
(8)oob_score=True:对于37%从来取不到的数据可以进行自我模型验证
9、对于有放回的取样Bagging式的机器学习算法在生成子模型的训练过程中大概会有37%的样本数据从来都不会在子模型中取上,将其称为OUT-OF-Bagging,因此可以直接首先将其作为测试数据集进行验证,需要在定义集成学习的时候将out_score=true。另外,对于bagging的方式可以使得训练子模型的过程进行并行化,提高计算训练的效率。

10、对于集成学习的做子模型的差异还可以从数据样本的特征中进行随机取样,这样随机性也会更加提高,使得子模型的差异更大一些,总体的准确度将更好。
11、对于数据样本的集成学习,子模型的建立可以在基础数据集选取上既从特征上随机,又从数据样本上随机,这样综合效果将达到最好,将其称为random patches。
标签:obs nbsp 测试数据 增加 它的 16px ima rand 学习任务
原文地址:https://www.cnblogs.com/Yanjy-OnlyOne/p/11380474.html