标签:组成 limit 支持 分发 机器 more 启动 temp l命令
在使用Hadoop的过程中,大家都会感觉每次都要写MR程序才能操作到HDFS的文件,太麻烦了,而且如果项目又赶,项目人员不会写MR程序,还要花费大量的时间去学,但是我是知道文件内容,是用什么分割的,分割后的每一列是什么意思,感觉好像关系型数据库。
于是有群人就有了个想法,既然我知道了这些数据分割后的每一列数据的意义,那么能不能把关系型数据库的SQL解析器搬过来呢?
并把这个解析的映射改为MR程序的映射,用户只要按照定义好的语法去写,我就给你解析成对应的MR程序去运行。
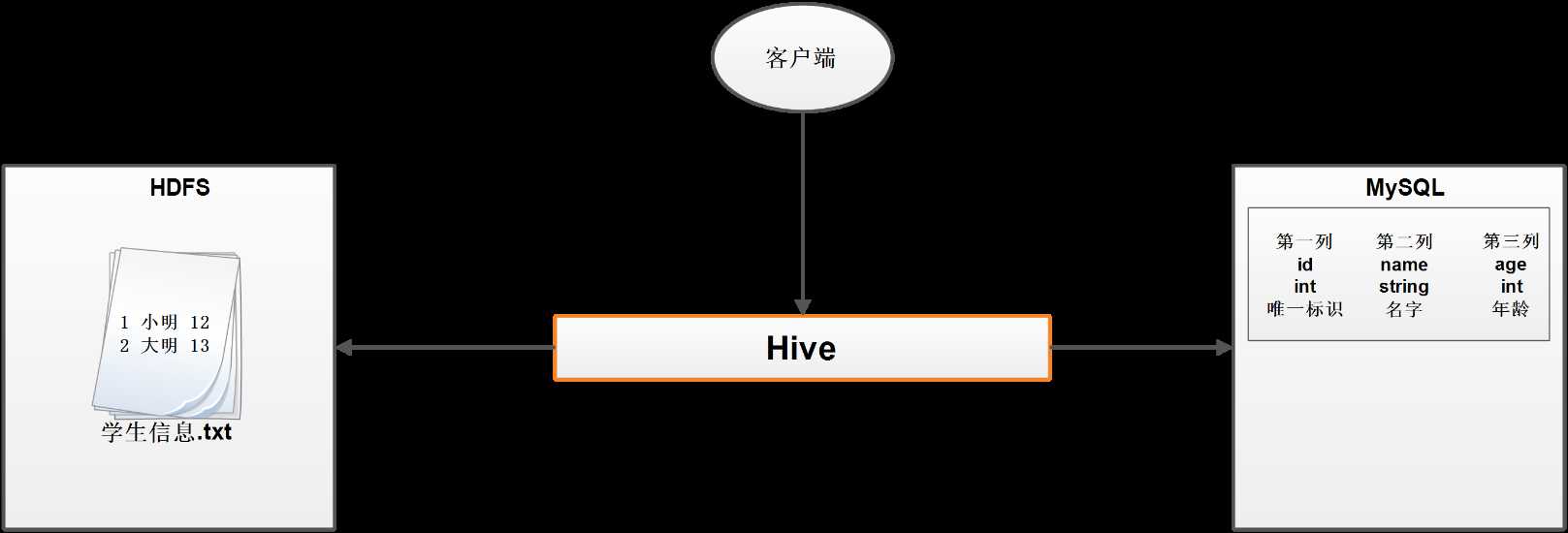
Hive是基于Hadoop的数据仓库工具,将结构化的数据映射成一张数据库表,并提供类似SQL查询功能,称为HQL,本质就是封装MR程序。
假设商店场景,数据库是存储小物品,而且还是归类好的物品,并且是库存不够的时候就可以很快的就拿到了。
数据仓库是存储了一堆的东西,包括已经过期,准备回收的商品,而且很大,并且还可以存储和数据库存储的东西,所相关的东西,比如牛奶卖出去了,这个大的牛奶盒子这些。
数据库就是存储存储定向的数据,如商品的最新信息,毕竟商品的价格每天都会变。
数据仓库存储类似历史数据或主题数据,如,订单相关的物流信息,商品的历史价格这些,而且和业务系统不一定完全一样,主要用于统计、数据分析等
元数据就是一个东西的描述信息,比如衣柜,衣柜的外观、大小、材质、容量、衣柜的哪一格存放了什么东西等等,这些就是元数据。
可扩展性:Hive可以自由的扩展集群规模,一般情况下不需要重启服务。
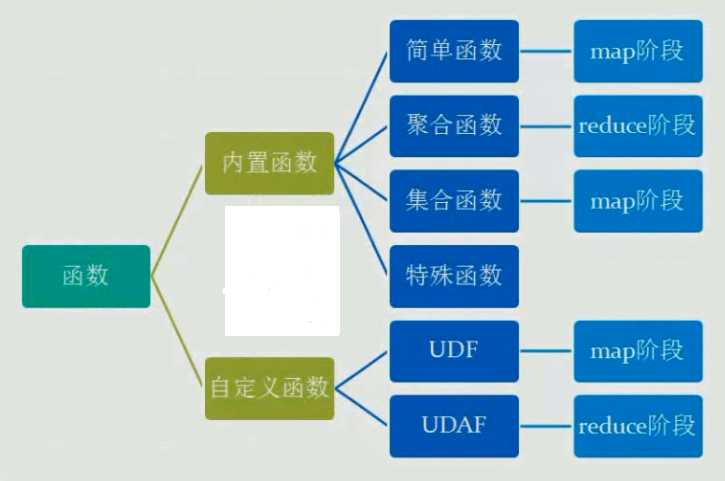
延展性:支持用户自定义函数。
容错性:节点出问题了,HQL依然可以完成。
CLI:shell命令行
JDBC/ODBC:Hive的Java实现
WebGUI:浏览器访问
Hive将元数据存储在数据库中,Hive中的元数据包括表的名称、列、分区、属性、是否是外部表、所在目录等等
解析器、编译器、优化器完成HQL查询语句到词法解析、语法解析,编译、优化、查询计划生成,查询计划是存储在HDFS,之后调用MR执行。
|
|
Hive |
传统数据库 |
|
查询语言 |
HQL |
SQL |
|
数据存储 |
HDFS |
Raw Device or LocalFS |
|
执行 |
MR |
Executor |
|
执行延迟 |
高 |
低 |
|
数据量 |
多 |
少 |
|
索引 |
0.8版本(位图索引) |
复杂 |
DB(数据库):HDFS下的/user/hive/warehouse文件夹
Table(内部表):HDFS下/user/hive/warehouse/数据库/表,表删除后对应的文件夹也删除
External Table(外部表):类似Table,就是数据存放位置可以任意指定路径,删除后,位于HDFS中的文件不会给删除。
Partition(分区):HDFS下/user/hive/warehouse/数据库/表/区。
分区是一种逻辑性和物理上的优化,以空间换取时间,把一个表的数据切分成两个进行存储,这个切分可能是按照时间做切割,后面再查询的时候,内部会根据条件去判断要到哪个文件夹去找数据。
Bucket:在HDFS中同一个表目录下根据Hash散列后的不同文件,类似10%2=0,存储到文件1,=1存储到文件2,=2存储到文件3…
bin/hive:本地客户端
bin/hive -e "select * from 库名.表名;":执行执行
bin/hive -e "use 库名;select * from表名;":直接执行
bin/hive -f 文件.hql:将复杂的hql语句放到文件内,并执行
bin/hiveserver2:开启远程服务
其他机器启动:bin/beeline
其他机器连接:!connect jdbc:hive2://hadoop-s01.levi.com:10000
cat ./hivehistory:使用过的历史HQL命令
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 简单的查询不走mapreduce -->
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
|
类型 |
支持范围 |
|
TINYINT |
1字节带符号整数,从-128到127 |
|
SMALLINT |
2字节带符号整数,从-32,768到32,767 |
|
INT/INTEGER |
4字节带符号整数,从-2,147,483,648到2,147,483,647 |
|
BIGINT |
8字节带符号整数,从-9,223,372,036,854,775,808到9,223,372,036,854,775,807 |
|
FLOAT |
4字节单精度浮点数 |
|
DOUBLE |
8字节双精度浮点数 |
|
DOUBLE |
精度 |
|
DECIMAL |
十进制数据类型在Hive 0.11.0 (Hive -2693)中引入,在Hive 0.13.0 (Hive -3976)中进行了修改。 |
|
类型 |
支持版本 |
|
TIMESTAMP |
注意:只能从Hive 0.8.0开始使用 |
|
DATE |
注意:只能从Hive 0.12.0开始使用 |
|
INTERVAL |
注意:只能从Hive 1.2.0开始使用 |
|
类型 |
支持版本 |
|
|
arrays |
ARRAY(data_type) |
注:Hive0.14允许负值和非常量表达式。 |
|
maps |
MAP(primitive_type, data_type) |
注:Hive0.14允许负值和非常量表达式。 |
|
structs |
STRUCTcol_name : data_type [COMMENT col_comment], …) |
|
|
union |
UNIONTYPE(data_type, data_type, …) |
注意:只能从Hive 0.7.0开始使用。 |
|
string |
字符串 |
|
ARRAY:ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由[‘apple‘,‘orange‘,‘mango‘]组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的
MAP:MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist[‘username‘]来得到这个用户对应的password;
STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
UNION:UNIONTYPE,他是从Hive 0.7.0开始支持的。
创建数据库:CREATE DATABASE IF NOT EXISTS levi;
设置变量临时生效:set hive.cli.print.header=false
创建表:create table if not exists test(id string,name string,sex string) row format delimited fields terminated by ‘\t‘;
创建表:create table newtb as select * from db.tname
创建表:create table newtb like db.tname
创建外部表:create external table test2(id int,name string) row format delimited fields terminated by ‘\t‘
创建表(分区):create table if not exists levi.t_partition(id string,
name string)partitioned by (date string,hour string)
row format delimited fields terminated by ‘\t‘;
创建表(分桶):create table people(id string,name string)clustered by(id) sorted by (id) into 3 buckets row format delimited fields terminated by ‘\t‘;
创建表(正则):
create table IF NOT EXISTS test (
id string,
name string
)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe‘
WITH SERDEPROPERTIES (
"input.regex" = "(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\]]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*) (\"[^ ]*\") (\"[^\"]*\") (-|[^ ]*) (\"[^ ]*\")"
)
STORED AS TEXTFILE;
查看表信息:desc formatted tbname
导入数据(本地):load data local inpath ‘/local_path/file‘ into table 表名;
导入数据(本地)(覆盖):load data local inpath ‘/local_path/file‘ overwrite into table 表名;
导入数据(HDFS):load data inpath ‘/local_path/file‘ into table 表名;
导入数据:insert into table 表名 select * from tbname;
导入数据:insert overwrite into table 表名 select * from tbname;
导入数据(分区):load data local inpath ‘/opt/module/hive-hql/1999092919‘ into table levi.t_partition partition(date=‘19990929‘,hour=‘19‘);
导出(本地):insert overwrite local directory "/opt/module/hive-hql/data_dir/"row format delimited fields terminated by ‘\t‘ select * from levi.tname;
导出(HDFS):insert overwrite directory "path/" select * from levi.tbname;
自定义UDF函数:

添加到hive的classpath:add jar /opt/lowercase.jar
添加到Hive函数列表:create temporary function 函数名 as ‘包名.类名‘
运行函数:select 函数名(name) from student;
order by:全局排序,会强行的把reducer改为一个,就算分桶了,还是查询所有数据。
sort by:数据进入reducer前完成排序,因此使用sort by排序,并设置mapred.reduce.tasks>1,则sort by保证每个reducer输出有序,不保证全局有序,就算是对每一个reduce内部数据进行排序。
distribute by:根据ditribute by指定的字段,将数据分发不同reducer,而且分发算法是hash散列算法。
cluster by:就是sort by + distribute by。
标签:组成 limit 支持 分发 机器 more 启动 temp l命令
原文地址:https://www.cnblogs.com/-levi/p/11380550.html