标签:pre 集中 切分 下界 故障处理 优缺点 mst 架构 分区
Hadoop生态圈中有了Hive,Hive可以像关系型数据库那样操作数据,那么为什么还要有HBase?
首先HBase是一个非关系型数据库,是用于存储数据的,Hive是用于处理数据的。
Hive操作数据时虽然可以像关系型数据库那样操作,但Hive只是一个操作工具,而非一个针对大批量数据存储的解决方案。
我们先来看看HBase是什么,在去做做比较,这样大家就清晰多了。
HBase是谷歌的BigTable论文的开源实现,也有很多不同,BigTable使用GFS作为文件存储系统,HBase是使用HDFS作为存储系统(可配置),依然是熟知的Apache下的产品。
HBase是一个高可靠、高性能、面向列的可伸缩分布式非关系型分布式存储系统,志在在廉价的PC上搭建起一个存储结构化和非结构化数据并处理大批量数据服务器集群,说白了就是把配置低的PC组成集群来处理成万上亿的数据。
HBase可以分为两种角色,一种是存储系统,一种是作为数据处理模型的MapReduce框架。
|
HBase |
HDFS |
|
分布式存储提供文件系统 |
提供表状(逻辑化)的面向列的数据存储 |
|
针对存储大尺寸文件进行优化,不需要针对HDFS上的文件进行随机读写 |
针对表状的数据随机读取进行优化 |
|
直接使用文件 |
Key-Value操作数据 |
|
数据模型不灵活 |
灵活的数据模型 |
|
文件系统和处理框架 |
表状存储,支持MapReduce,依赖HDFS |
|
一次写,多次读 |
多次读,多次写 |
行数据库:
id name age
1 aaa 22
2 bbb 23
3 ccc 21
列数据库:
id 1 2 3
name aaa bbb ccc
age 22 23 21
说明:列式数据库就是把行数据库的列转为行。
行数据库的数据是具有行连续性(id-name-age)。
列数据库是把拆成列连续性(id)(name)(age)
行数据是连续性的,是由不同的列组成的,会存在不同的列数据类型不一致,在搜索时,要把不同类型的数据做各种处理在进行组合,如果有某一列的数据是空数据也是要处理连接起来。
列数据库就是列连续性,只要对列的数据做处理就可以了,而且数据类型、内容等各种方面基本都一样,压缩率也高,空数据是不会给计算的。
说白了就是行数据库把数据都连在一起了,列数据库就是拆开,各自管各自的,如果从分散的数据怎么寻找回在行数据库的数据链呢?(思考)
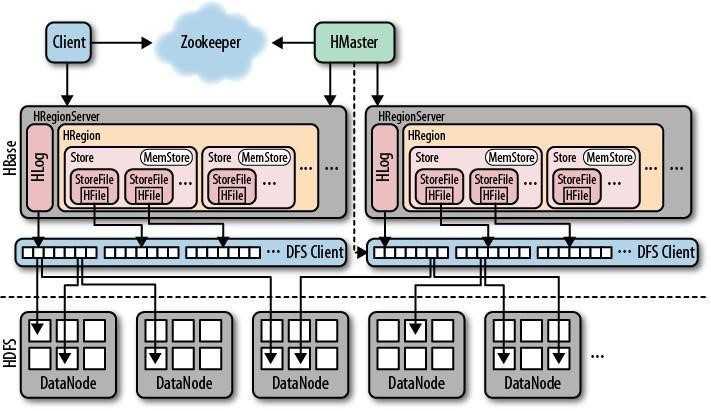
监控RegionServer
处理RegionServer故障转移
处理元数据变更
负责region在RegionServer的分配或移除
在空闲时间进行数据负载均衡
通过Zookeeper发布位置
管理用户对表的增删改查
负责存储HBase的实际数据
处理分配到的HRegion
刷新缓存到HDFS
维护HLog
执行压缩
处理HRegion分片(默认一个HRegionServer一个HRegion)
当对HBase读写数据的时候,数据不是直接写入到磁盘的,会在内存保留一段时间,(默认为内存40%/64MB),数据会先写到HLog文件中,然后在写入到内存,在系统出现故障的时候,数据可以通过这个日志文件重建。
这是磁盘上保存原始数据的实际的物理文件,是实际存储的文件
HFile存储在Store中,一个Store对应一个HBase表中的一个列族
用来保存当前的数据操作,是在内存中的,所以当数据保存在WAL中,HRegionServer会在内存中存储键值对。
HBase表中的分片,就是干操作、调度、存储元数据等工作,HBase表会根据RowKey值被切分成不同的Region存储在HRegionServer中,在一个RegionServer中可以有多个不同的HRegion。
存储所有的HRegion的寻址信息
监控HRegionServer上下线
通知
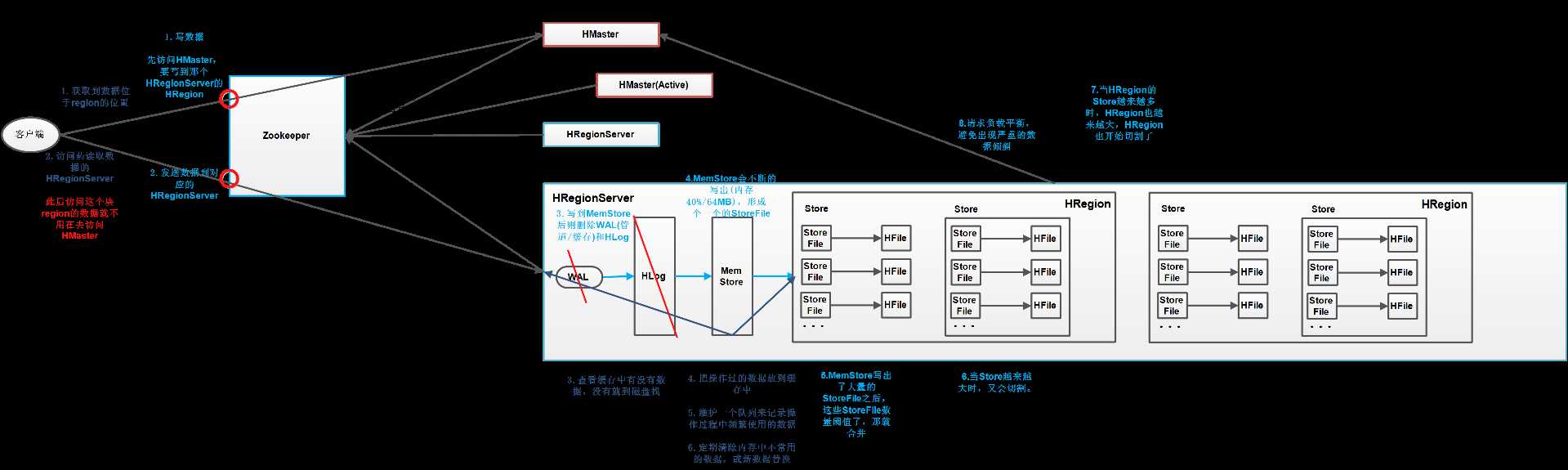
HBase运行在HDFS上,所以HBase中的数据以副本的形式存储,数据也是分布式存放,从而数据就得到了保障,另外HMaster和RegionServer也是多副本的。
HBase的表是由分布在多个RegionServer中的region组成的,这些RegionServer又分布在不同的DataNode上,如果一个region增长到了一个阈值,为了负载均衡和减少IO,HBase可以自动或手动干预的将region切分为更小的region。
HBase也要运行在其他的分布式文件系统上,但和HDFS结合也是非常方便。
HBase采用log-structured merge-tree作为内部数据存储架构,这种架构会周期性的将小文件合并成大文件,以减少磁盘IO同时减少NameNode压力。
HBase内建支持MapReduce框架,更加方便快速,并行的处理数据。
HBase提供原生的JavaAPI支持。
HBase支持横向扩展,如果有服务器硬件性能出现了瓶颈,不需要停掉现有集群提升硬件,直接在正在运行的集群添加新的机器节点即可,而且的RegionServer一旦建立完毕,集群会自动重新分配。
HBase是面向列存储的,每个列都单独存储,所以HBase中的列是连续存储的。
HBase提供了交互性命令行工具来进行创建表、添加数据、扫描数据、删除等操作和管理操作。
|
RDBMS |
HBase |
|
以表的形式存在 |
以region(翻译:地区、范围)的形式 |
|
支持FAT/NTFS/EXT/文件系统 |
支持HDFS文件系统(可配置,主要以HDFS为主) |
|
使用Commit Log存储日志 |
使用WAL(预写入日志)存储日志 |
|
参考系统是坐标系统 |
参考系统是Zookeeper |
|
主键 |
行建(rowkey) |
|
支持分区 |
支持分片 |
|
使用行、列、单元格 |
使用行、列、单元格 |
|
RDBMS |
HBase |
|
支持向上扩展 |
支持横向扩展 |
|
支持SQL |
使用API和MapReduce来访问HDFS |
|
面向行和每一行都是一个连续单元 |
面向列,每个列都是一个连续的单元 |
|
数据总量依赖服务器配置 |
数据总量不依赖具体某台机器 |
|
具有ACID |
不支持ACID |
|
支持事务, |
不支持事务 |
|
适合结构化数据 |
适合结构化和非结构化数据 |
|
传统关系型数据库一般是中心化 |
一般是分布式 |
|
支持join |
不支持join(性能差) |
传统数据库:数据量大时无法存储,且没有很好的备份机制,数据量达到一定数量开始变得缓慢,数据量很多就无法支撑了。
HBase:横向扩展的特性可以使得HBase随着数据量增多要通过节点扩展,数据存储在HDFS,备份机制健全,通过Zookeeper查找数据访问速度快。
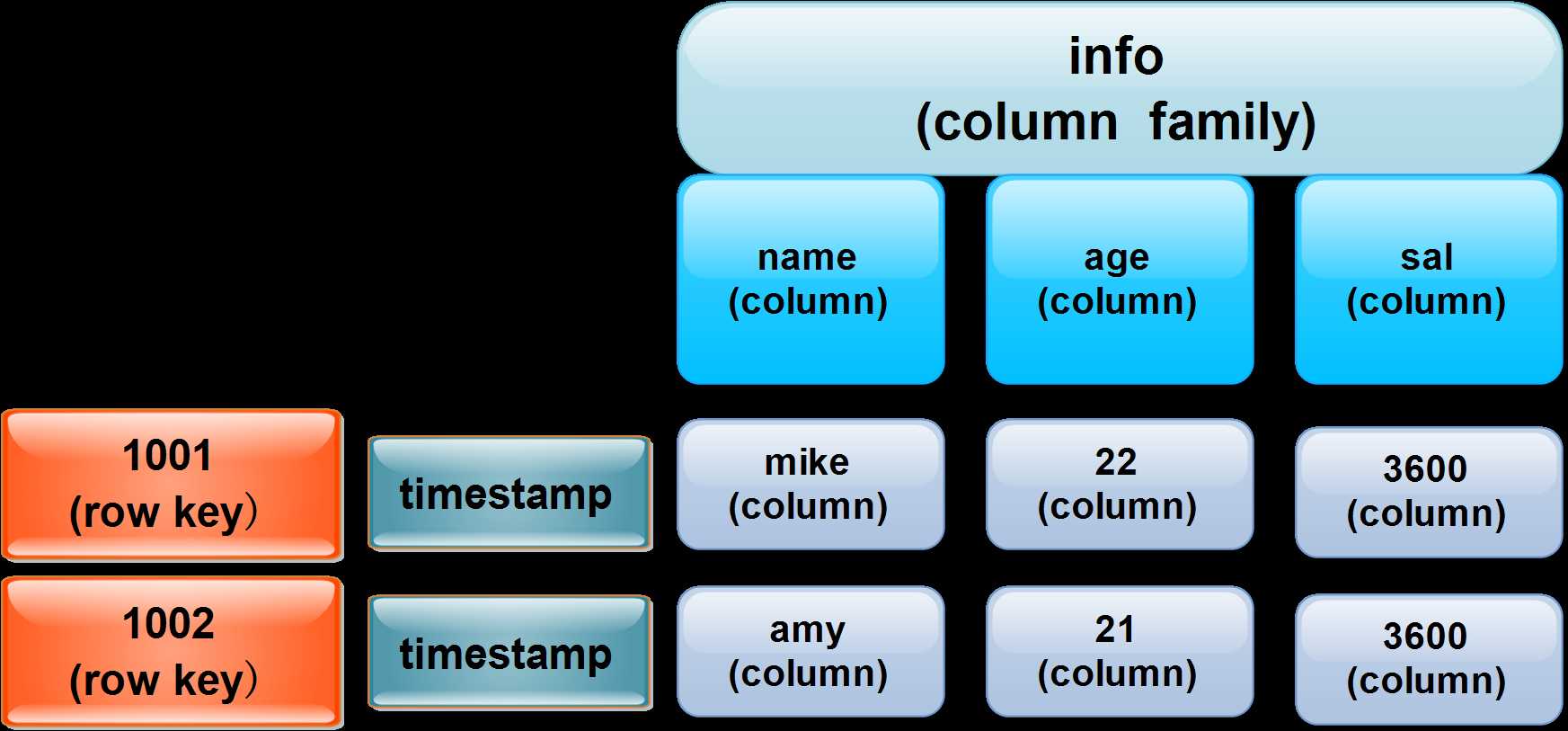
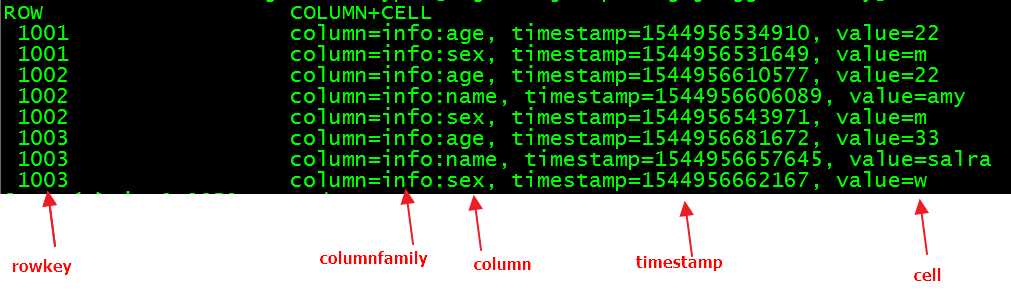
HBase是由row key、timstamp、column family、column、cell组成的。
row key:确定唯一的一行。
timstamp:时间戳
column family:由多个column组成。
column:就是列(字段)。
cell:就是数据(值)。
方便高效的压缩数据(如果是关系型数据库压缩的话,不同列是不同数据类型,会比较慢,压缩质量也不客观)(HBase一列一列的压缩,每一列都是相近的内容)
支持快速数据检索
管理和配置简单
支持横向扩展,所以非常容易扩展,聚合查询性能也是比较高(count)
高效的分区,提供自动分区机制
对join以及多表合并数据的查询性能不好
更新过程中有大量写入和删除操作,需要频繁的合并和分裂,降低存储效率
对关系模型支持不好,分区和索引设计比较困难
数据很多列,而且包含很多空字段
数据包含了不定数量的列
需要维护数据的版本
需要很高的横向扩展性
需要大量压缩数据(牺牲CPU,提高传输速度)
需要大量读写IO
小结:数据量不大(几个G、几十G),经常join操作以及关系型数据库的某些特性(事务),是不需要使用HBase,如果有几十E列的数据,同时每秒会有上万次的读写操作,可以考虑使用HBase。
|
Hive |
HBase |
|
数据仓库,在MySQL(其他)里存储HDFS中的文件数据意义和关系,从而去操作。 |
数据库,面向列的非关系型数据库,用于存储结构化和非结构化数据,不适合做关联查询(join等) |
|
用于数据分析和清洗,适用于离线的数据分析和清洗,延迟较高,写MapReduce很麻烦。 |
延迟低,接入在线业务使用,面对企业大量的数据,HBase可以直接进行大量数据存储,同时提供高效的数据访问速度。 |
|
基于HDFS、MapReduce,数据依然是在HDFS,编写的HQL会转换为MapReduce代码。 |
还是HDFS,数据持久化存储体现形式是HFile,存放于DataNode中,被HRegionServer以HRegion方式管理。 |
Hive可以理解为就是一款工具,操作底层文件内容的工具,对混乱的数据进行优化、清洗等操作,可能是没有清洗的数据,可能只是知道数据在文件内的数据分隔符且数据有点脏乱等等,这样的数据肯定不能拿来用,Hive就是干这种苦活、累活的,这种苦活,累活的要求又要别人细心一点,尽量清洗到位,能不需要时间么?所以用于离线。
HBase就是将数据进行存储,无论这个数据是关系型还是非关系型的数据,其实就是用户自己定义好的数据,大部分可以拿来用的,和Hive的对比就类似,Hive就是干数据整理的工作的,HBase就是干把书放到书架的工作,这个书架可能大,可能小,书架里的格子亦是如此。
进入Shell客户端:$ bin/hbase shell
帮助文档:hbase(main):001:0> help
所有表:hbase(main):001:0> list
创建表:hbase(main):001:0> describe ‘ people‘
创建表(多列族):hbase(main):001:0> create ‘ people ‘,{NAME => ‘f1‘},{NAME => ‘f2‘}
创建表(分区,RowKey):hbase(main):001:0> create ‘people‘,‘info‘,‘partition1‘,split => [‘1000‘,‘2000‘,‘3000‘,‘4000‘,‘5000‘]
查看表结构:hbase(main):001:0> describe ‘ people‘
添加数据:hbase(main):001:0> put ‘ people‘,‘1001‘,‘info:name‘,‘mike‘
查看表数据:hbase(main):001:0> scan ‘people‘
scan ‘people‘,{STARTROW => ‘1001‘,STOPROW >= ‘1007‘}
更新数据:hbase(main):001:0> put ‘people‘,‘1001‘,‘info:name‘,‘mike2‘
查看指定行数据:hbase(main):001:0> get ‘people‘,‘1001‘,‘info:name‘
根据rowkey删除所有数据:hbase(main):001:0> deleteall ‘people‘,‘1001‘
删除指定列数据:hbase(main):001:0> delete ‘people‘,‘1001‘,‘info:name‘
清除表(删了在建):hbase(main):001:0> truncate ‘people‘
表是否可用:hbase(main):001:0> is_enabled ‘people‘
表设为可用:hbase(main):001:0> enable ‘people‘
表是否不可用:hbase(main):001:0> is_disabled ‘people‘
表设为不可用:hbase(main):001:0> disable ‘people‘
删除表(disable状态才能删除):hbase(main):001:0> drop ‘people‘
聚合查询(rowkey数量):hbase(main):001:0> count ‘people‘
表是否存在:hbase(main):001:0> exists ‘people‘
添加列族:hbase(main):001:0> alter ‘ people ‘,NAME => ‘F3‘,VERSION => 2
删除列族:hbase(main):001:0> alter ‘ people ‘,‘delete‘ => ‘F3‘
当前用户:hbase(main):001:0> whami
服务器状态:hbase(main):001:0> status ‘192.168.1.1‘
BulkLoad会将tsv/csv格式文件变成HFile文件,然后在进行数据导入,这样就避免了HBase在进行业务操作时,有大量的数据导入,造成集群压力过大,提升了Job运行速度,并降低了Job执行时间。
每个HRegionServer都有一个协处理器进程,所有HRegion都包含对谢处理器实现的引用,可以通过HRegionServer的类路径加载,也可以通过HDFS类加载器加载,协处理器的设计是为了方便开发者自定义的向HBase中添加额外的功能,协处理器可以用来做客户端的操作,比如region分裂、合并,与客户端创建、读取、删除、更新等等。
Coprocessor:提供region生命周期管理,打开、关闭、分裂、合并等等
RegionServer:对表修改操作的监控,get、put、scan等等。
Endpoint:region端执行任意函数的功能(列聚集函数等)
上界:默认版本上界是3,也就是一个row可以保留3个副本(基于时间戳插入),这个值一般都不会超过100,如果cell中存储的数据版本号超过设定的(3),再次插入最新的值会把最老的覆盖。
下界:默认下界版本为0,就是金庸,row版本使用的最小数目是与生存时间(Time To Live)相结合的,且我们根据实际需求可以有0或更多版本,使用0,就只有一个版本的值写入cell。
高痩:少量列,大量的行,如果使用ID进行查询,会跳过行,不利于原子性,但是具有更好的扩展。
短宽:大量的列,少量的行,具有更好的原子性,扩展性不如高痩。
为了增加数据的读写效率,以及更好的负载均衡,集群容灾调度region,优化Map数量等原因,所以分区。
HBase的分区是根据rowkey分区,而rowkey存在临界值,一般我们会从数据集中抽取样本,来决定什么样的rowkey是符合业务的。
一般RowKey的设计有三种:
1、生成随机数、hash、散列值
2、字符串反转
3、字符串拼接
标签:pre 集中 切分 下界 故障处理 优缺点 mst 架构 分区
原文地址:https://www.cnblogs.com/-levi/p/11380578.html