目录
梯度消失
梯度爆炸
参考资料
以下图的全连接神经网络为例,来演示梯度爆炸和梯度消失:

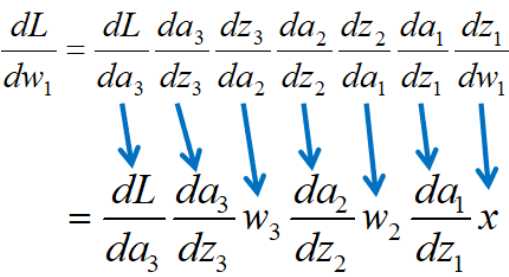
|
梯度消失 |
在模型参数w都是(-1,1)之间的数的前提下,如果激活函数选择的是sigmod(x),那么他的导函数σ’(x)的值域为(0,0.25],即如下三项的范围都是(0,0.25]
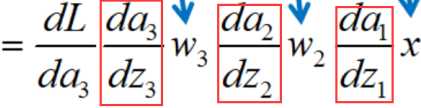
那么w1的导数会有很多(0,0.25]范围的数累乘,就会造成w1的导数很小,这就是梯度消失。梯度消失的后果就是,w1的更新就会很慢,使得神经网络的学习变得很慢。
解决方法:使用relu(x)这样的激活函数,因为他的导函数的值可以稳定在1,累乘后不会让梯度消失。
|
梯度爆炸 |
如果模型参数不是(-1,1)之间的数,比如是50,对w1求导时,就会出现很多大的数的累乘,更新参数会出现问题,无法完成网络学习
解决方法:合理的初始化模型参数
|
参考资料 |
对于梯度消失和梯度爆炸的理解
https://www.cnblogs.com/pinking/p/9418280.html
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平