标签:mysql state 数据库 hrd ima line ini 没有 语句
一.output操作概览
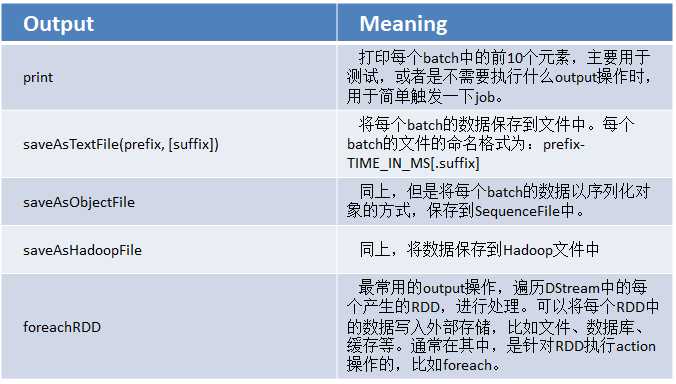
二.output操作
DStream中的所有计算,都是由output操作触发的,比如print()。如果没有任何output操作,那么,压根儿就不会执行定义的计算逻辑。
此外,即使你使用了foreachRDD output操作,也必须在里面对RDD执行action操作,才能触发对每一个batch的计算逻辑。否则,光有foreachRDD output操作,在里面没有对RDD执行action操作,也不会触发任何逻辑。
三.foreachRDD详解
通常在foreachRDD中,都会创建一个Connection,比如JDBC Connection,然后通过Connection将数据写入外部存储。
误区一:
在RDD的foreach操作外部,创建Connection
这种方式是错误的,因为它会导致Connection对象被序列化后传输到每个Task中。而这种Connection对象,实际上一般是不支持序列化的,也就无法被传输。
dstream.foreachRDD { rdd =>
val connection = createNewConnection()
rdd.foreach { record => connection.send(record)
}
}
误区二:
在RDD的foreach操作内部,创建Connection
这种方式是可以的,但是效率低下。因为它会导致对于RDD中的每一条数据,都创建一个Connection对象。而通常来说,Connection的创建,是很消耗性能的。
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
合理方式一:
使用RDD的foreachPartition操作,并且在该操作内部,创建Connection对象,这样就相当于是,为RDD的每个partition创建一个Connection对象,节省资源的多了。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
合理方式二:
自己手动封装一个静态连接池,使用RDD的foreachPartition操作,并且在该操作内部,从静态连接池中,通过静态方法,获取到一个连接,使用之后再还回去。这样的话,甚至在多个RDD的partition之间,也可以复用连接了。而且可以让连接池采取懒创建的策略,并且空闲一段时间后,将其释放掉。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection)
}
}
四.foreachRDD实战
案例:改写UpdateStateByKeyWordCount,将每次统计出来的全局的单词计数,写入一份,到MySQL数据库中。
建表语句
create table wordcount (
id integer auto_increment primary key,
updated_time timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP,
word varchar(255),
count integer
);
代码如下
package com.hzk.sparkStreaming;
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.LinkedList;
/**
* 简易版的连接池
* @author Administrator
*
*/
public class ConnectionPool {
// 静态的Connection队列
private static LinkedList<Connection> connectionQueue;
/**
* 加载驱动
*/
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* 获取连接,多线程访问并发控制
* @return
*/
public synchronized static Connection getConnection() {
try {
if(connectionQueue == null) {
connectionQueue = new LinkedList<Connection>();
for(int i = 0; i < 10; i++) {
Connection conn = DriverManager.getConnection(
"jdbc:mysql://hadoop-001:3306/baidu",
"",
"");
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return connectionQueue.poll();
}
/**
* 还回去一个连接
*/
public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
}
}
package com.hzk.sparkStreaming; import java.sql.Connection; import java.sql.Statement; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.Optional; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /** * 基于持久化机制的实时wordcount程序 * @author Administrator * */ public class PersistWordCount { public static void main(String[] args) throws InterruptedException { SparkConf conf = new SparkConf() .setMaster("local[2]") .setAppName("PersistWordCount"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5)); jssc.checkpoint("hdfs://hadoop-001:9000/wordcount_checkpoint"); JavaReceiverInputDStream<String> lines = jssc.socketTextStream("hadoop-001", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterator<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")).iterator(); } }); JavaPairDStream<String, Integer> pairs = words.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); JavaPairDStream<String, Integer> wordCounts = pairs.updateStateByKey( new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() { private static final long serialVersionUID = 1L; @Override public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception { Integer newValue = 0; if(state.isPresent()) { newValue = state.get(); } for(Integer value : values) { newValue += value; } return Optional.of(newValue); } }); // 每次得到当前所有单词的统计次数之后,将其写入mysql存储,进行持久化,以便于后续的J2EE应用程序 // 进行显示 wordCounts.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() { @Override public void call(JavaPairRDD<String, Integer> wordCountsRDD) throws Exception { // 调用RDD的foreachPartition()方法 wordCountsRDD.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() { @Override public void call(Iterator<Tuple2<String, Integer>> wordCounts) throws Exception { // 给每个partition,获取一个连接 Connection conn = ConnectionPool.getConnection(); // 遍历partition中的数据,使用一个连接,插入数据库 Tuple2<String, Integer> wordCount = null; while (wordCounts.hasNext()) { wordCount = wordCounts.next(); String sql = "insert into wordcount(word,count) " + "values(‘" + wordCount._1 + "‘," + wordCount._2 + ")"; Statement stmt = conn.createStatement(); stmt.executeUpdate(sql); } // 用完以后,将连接还回去 ConnectionPool.returnConnection(conn); } }); } }); jssc.start(); jssc.awaitTermination(); jssc.close(); } }
Spark Streaming DStream的output操作以及foreachRDD详解
标签:mysql state 数据库 hrd ima line ini 没有 语句
原文地址:https://www.cnblogs.com/Transkai/p/11385723.html