标签:创建索引 bar doc 创建 姓名 方法 自己的 问题 ESS
为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了,因此我们需要一个中文分词器来用于搜索和使用。
我们可以从官方github上下载该插件,我们下载对应于我们使用的es的版本的ik,并且我们能够看到具体的安装步骤,可以有两种安装方法。
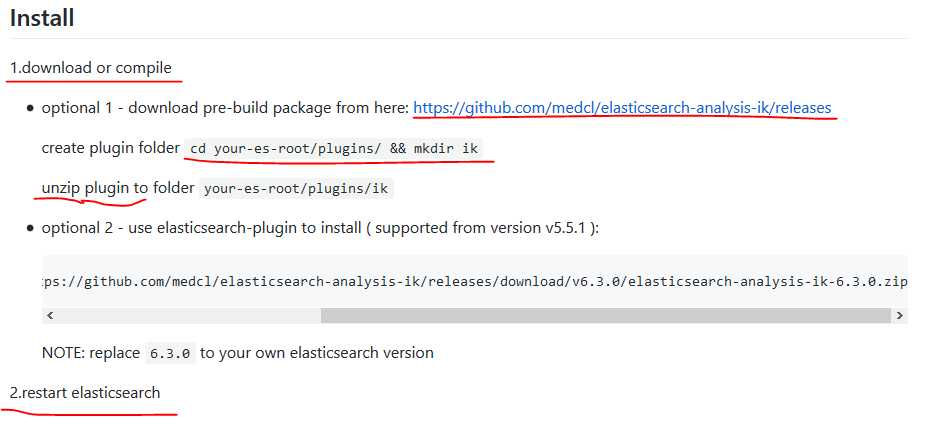
这里我们选择第一种方式:
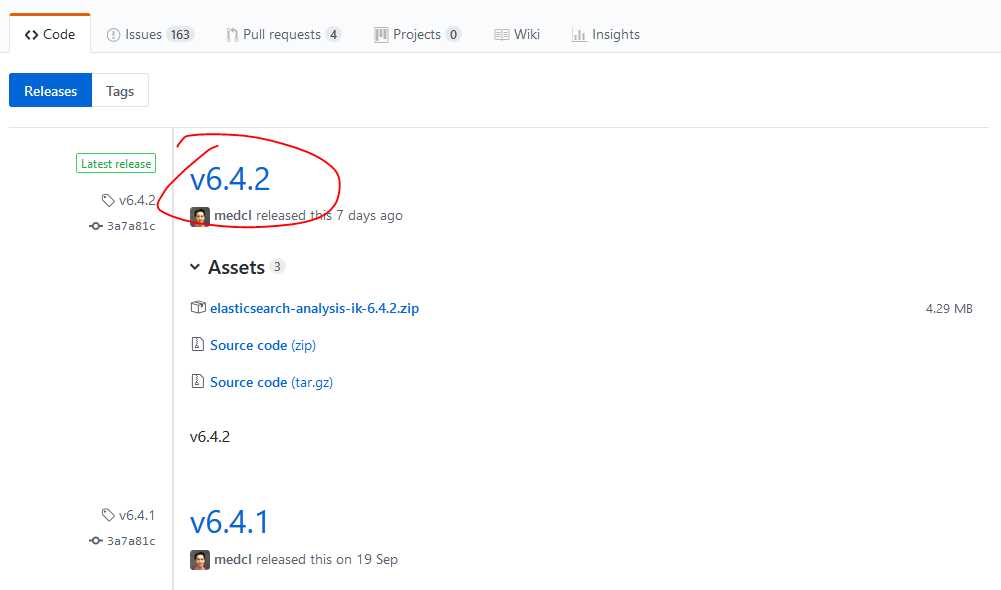
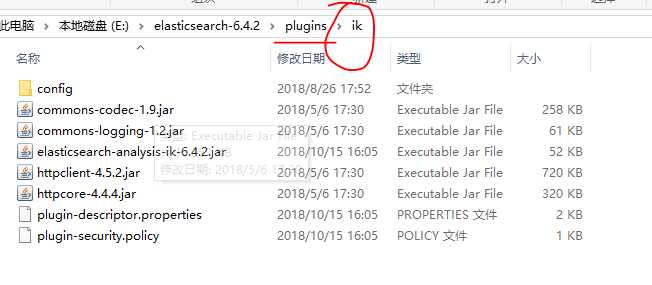
重启es,我们就可以使用ik这个中文分词器了。
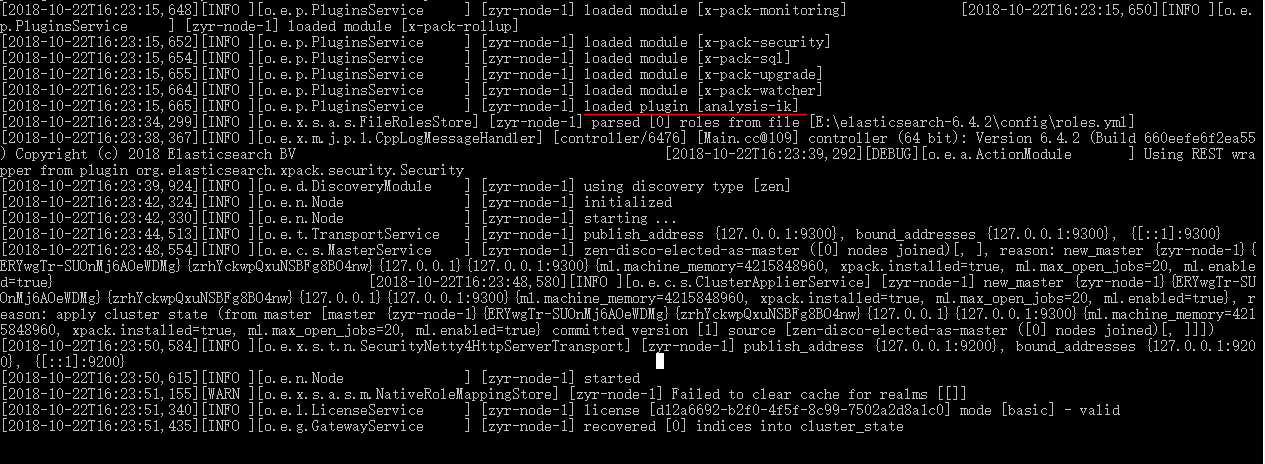
既然我们要使用ik中文分词器,那么就必须先在index数据库之中插入一些中文,然后再来索引一下这些中文的单词,就能看出是否成功了。
创建数据库:
使用kibana: PUT /lsx_index
使用curl: curl -XPUT http://localhost:9200/lsx_index
使用ik创建映射:

curl -XPOST http://localhost:9200/lsx_index/zyr_fulltext/_mapping -H ‘Content-Type:application/json‘ -d‘
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}‘
如果使用kibana,那么应该是:
1 POST /lsx_index/zyr_fulltext/_mapping
2 {
3 "properties": {
4 "content": {
5 "type": "text",
6 "analyzer": "ik_max_word",
7 "search_analyzer": "ik_max_word"
8 }
9 }
10 }
ElasticSearch 的分词器称为analyzer。analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词。ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
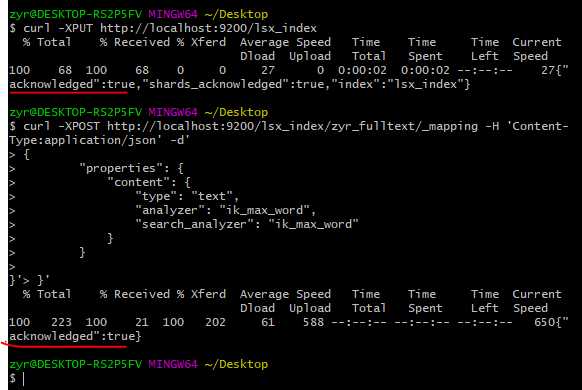
插入一些数据(文档):
大家注意,我们在插入数据的时候,如果使用git插入中文,则会出现如下错误,其实根本原因是我们使用的shell的字符集编码的问题,因此我们建议使用kibana来试一下:
{"error":{"root_cause":[{"type":"mapper_parsing_exception","reason":"failed to parse [content]"}],"type":"mapper_parsing_exception",
"reason":"failed to parse [content]","caused_by":{"type":"json_parse_exception","reason":"Invalid UTF-8 middle byte 0xc0\n at
[Source: org.elasticsearch.common.bytes.BytesReference$MarkSupportingStreamInputWrapper@29464944; line: 2, column: 15]"}},"status":400}

或者我们下载curl的其他curl工具,但是也是收效甚微:

当我们使用kibana的时候,一切都是那样的自然:
PUT /lsx_index/zyr_fulltext/1?pretty
{
"content":"这是一个测试文档"
}
PUT /lsx_index/zyr_fulltext/2?pretty
{
"content":"可以了解一些测试方面的东西"
}
PUT /lsx_index/zyr_fulltext/3?pretty
{
"content":"关于分词方面的测试"
}
PUT /lsx_index/zyr_fulltext/4?pretty
{
"content":"如果你想了解更多的内容"
}
PUT /lsx_index/zyr_fulltext/5?pretty
{
"content":"可以查看我的博客"
}
PUT /lsx_index/zyr_fulltext/6?pretty
{
"content":"我是朱彦荣"
}
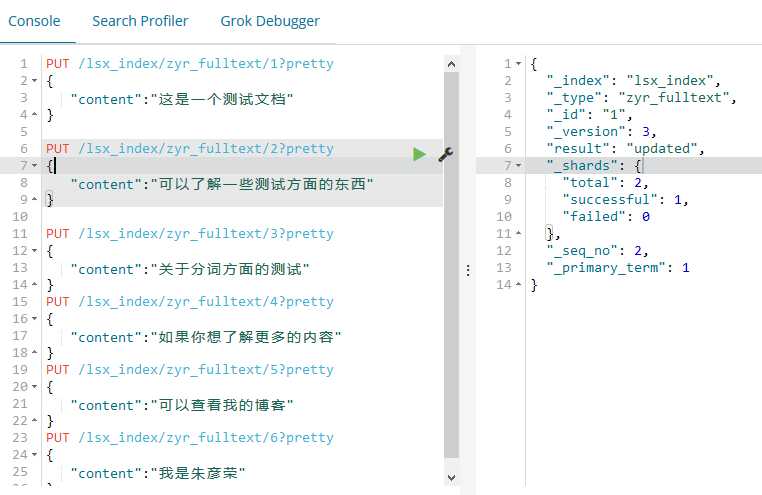
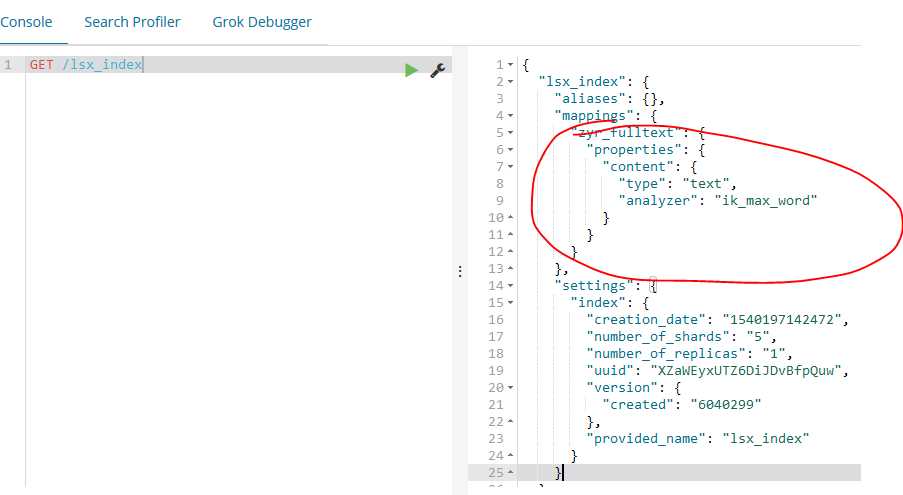
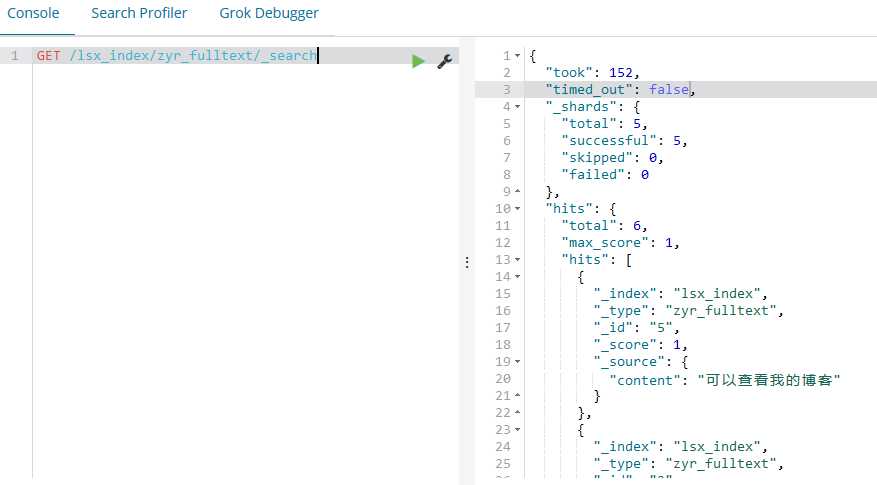
下面我们还是分词查询:
POST /lsx_index/zyr_fulltext/_search
{
"query" : {
"match" : { "content" : "关于分词方面的测试,朱彦荣" }
},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
结果如下:

{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 3.3319345,
"hits": [
{
"_index": "lsx_index",
"_type": "zyr_fulltext",
"_id": "6",
"_score": 3.3319345,
"_source": {
"content": "我是朱彦荣"
},
"highlight": {
"content": [
"我是<tag1>朱</tag1><tag1>彦</tag1><tag1>荣</tag1>"
]
}
},
{
"_index": "lsx_index",
"_type": "zyr_fulltext",
"_id": "2",
"_score": 2.634553,
"_source": {
"content": "可以了解一些测试方面的东西"
},
"highlight": {
"content": [
"可以了解一些<tag1>测试</tag1><tag1>方面</tag1><tag1>的</tag1>东西"
]
}
},
{
"_index": "lsx_index",
"_type": "zyr_fulltext",
"_id": "3",
"_score": 1.4384104,
"_source": {
"content": "关于分词方面的测试"
},
"highlight": {
"content": [
"<tag1>关于</tag1><tag1>分词</tag1><tag1>方面</tag1><tag1>的</tag1><tag1>测试</tag1>"
]
}
},
{
"_index": "lsx_index",
"_type": "zyr_fulltext",
"_id": "1",
"_score": 0.2876821,
"_source": {
"content": "这是一个测试文档"
},
"highlight": {
"content": [
"这是一个<tag1>测试</tag1>文档"
]
}
}
]
}
}
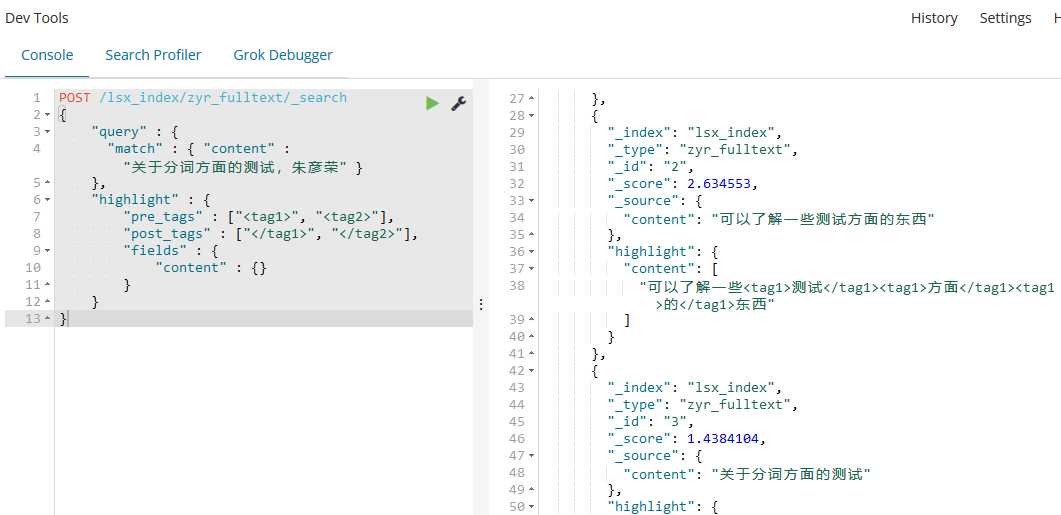
由此可以看到分词的强大功能了。
如果我们仔细查看插件的目录,就可以看到有很多的预先设定的配置,比如停止词等等。
我们看一下IKAnalyzer.cfg.xml这个文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
扩展词理所当然是我们自己常用的,但是又不被广泛认可的词,比如我们的姓名等,下面是停止词的一些理解:
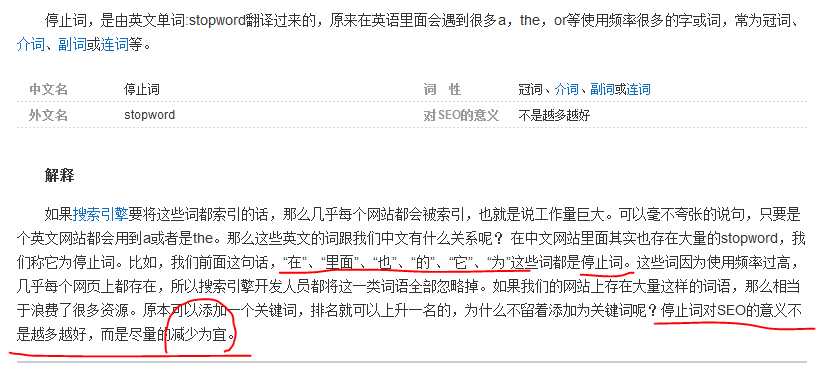
可以看到我们可以增加一些配置在我们的文件之中,比如我们新建一个文件,这个文件之中加入我们的分词,然后重新启动es,再次查询这个词,就能发现系统不会将这些词分隔开了。这里我们需要注意,系统会默认将文件前面的目录补全,我们如果是在config目录下面新建的文件词典,那么直接在配置之中写入文件名即可。

下面我们重新建立一个索引,走一下这个过程,整个过程如下:
1 #创建索引
2 PUT /zyr_lsx_index
3
4 #创建映射
5 POST /zyr_lsx_index/zyr_lsx_fulltext/_mapping
6 {
7 "properties": {
8 "detail_test": {
9 "type": "text",
10 "analyzer": "ik_max_word",
11 "search_analyzer": "ik_max_word"
12 }
13 }
14 }
15
16 #插入数据
17 PUT /zyr_lsx_index/zyr_lsx_fulltext/1?pretty
18 {
19 "detail_test":"这是一个测试文档"
20 }
21
22 PUT /zyr_lsx_index/zyr_lsx_fulltext/2?pretty
23 {
24 "detail_test":"可以了解一些测试方面的东西"
25 }
26
27 PUT /zyr_lsx_index/zyr_lsx_fulltext/3?pretty
28 {
29 "detail_test":"关于分词方面的测试"
30 }
31 PUT /zyr_lsx_index/zyr_lsx_fulltext/4?pretty
32 {
33 "detail_test":"如果你想了解更多的内容"
34 }
35 PUT /zyr_lsx_index/zyr_lsx_fulltext/5?pretty
36 {
37 "detail_test":"可以查看我的博客"
38 }
39 PUT /zyr_lsx_index/zyr_lsx_fulltext/6?pretty
40 {
41 "detail_test":"我是朱彦荣"
42 }
43
44
45 #搜索测试
46 POST /zyr_lsx_index/zyr_lsx_fulltext/_search
47 {
48 "query" : {
49 "match" : { "detail_test" : "朱彦荣" }
50 },
51 "highlight" : {
52 "pre_tags" : ["<tag1>", "<tag2>"],
53 "post_tags" : ["</tag1>", "</tag2>"],
54 "fields" : {
55 "detail_test" : {}
56 }
57 }
58 }
同时我们对ik的配置文件进行修改:
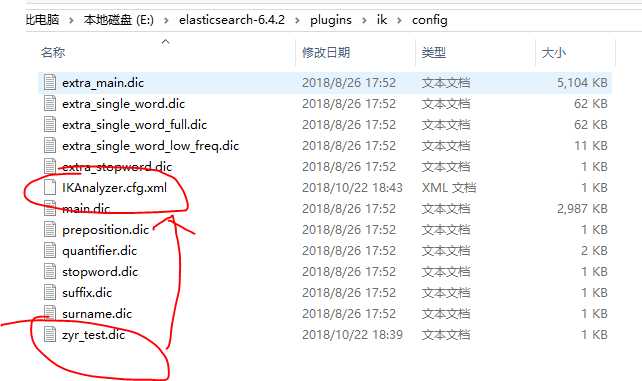
IKAnalyzer.cfg.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> 3 <properties> 4 <comment>IK Analyzer 扩展配置</comment> 5 <!--用户可以在这里配置自己的扩展字典 --> 6 <entry key="ext_dict">zyr_test.dic</entry> 7 <!--用户可以在这里配置自己的扩展停止词字典--> 8 <entry key="ext_stopwords"></entry> 9 <!--用户可以在这里配置远程扩展字典 --> 10 <!-- <entry key="remote_ext_dict">words_location</entry> --> 11 <!--用户可以在这里配置远程扩展停止词字典--> 12 <!-- <entry key="remote_ext_stopwords">words_location</entry> --> 13 </properties>
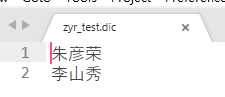
重启es,将上面的代码执行一遍,然后就会发现,我们自己定义的扩展词已经生效了,不会再被分割成一个个的字了,至此,我们对ik有了更深的理解,其次,我们还可以通过远程的方式来更新我们的词库,这样,我们就能理解搜狗输入法的一些记忆功能了。
其实我们也能看到我们的文件被加载了:

最终的结果:
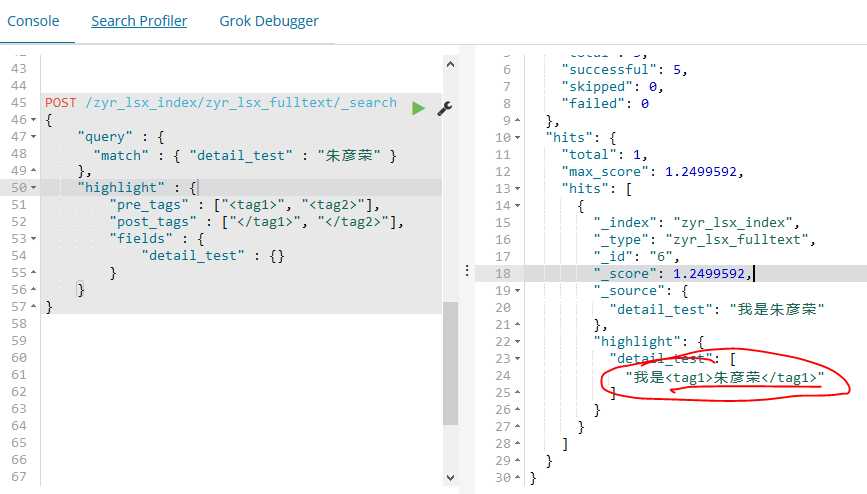
通过我们对ik的学习,我们更加深刻的理解了es的强大功能,以及如何使用插件扩展的方法,为我们以后自建搜索引擎提供了工具。
标签:创建索引 bar doc 创建 姓名 方法 自己的 问题 ESS
原文地址:https://www.cnblogs.com/ExMan/p/11386082.html