标签:blog http ar 使用 sp 数据 div on 2014
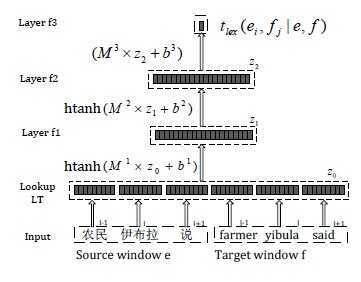
1. 论文【1】中使用了DNN的思想进行对齐,对齐所需训练数据来自HMM和IBM Model4,算上输入层一共是四层结构,见下图:
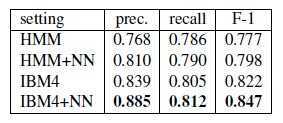
效果好于原始的HMM和IBM4,见下图:
 该思路可以用在许多地方,诸如:片段相似度、句子相似度、翻译概率、词向量等计算上。
该思路可以用在许多地方,诸如:片段相似度、句子相似度、翻译概率、词向量等计算上。待补充。。。
3. 近似代码实现(python版,使用IBM Model1 + NN):
后续补充。。。
引用:
【1】ACL‘13, Word Alignment Modeling with Context Dependent Deep Neural Network
转载请注明引用自:
http://www.cnblogs.com/breakthings/p/4049854.html
标签:blog http ar 使用 sp 数据 div on 2014
原文地址:http://www.cnblogs.com/breakthings/p/4049854.html