标签:splay 存储 通过 如何 分布式 权重 dfs width mamicode
第七章 推荐系统实例
7.1 外围架构
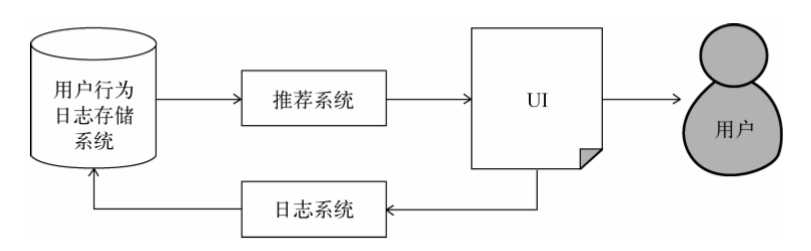
数据收集和存储
需要实时存取的数据存储在数据库和缓存中,而大规模的非实时地存取数据存储在分布式文件系统中(HDFS)中。
7.2 推荐系统架构
用户和物品的联系如下所示:
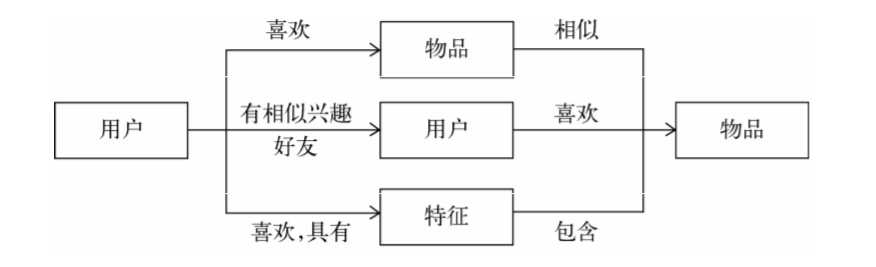
如果认为用户喜欢的物品也是一种用 户特征,或者和用户兴趣相似的其他用户也是一种用户特征,那么用户就和物品通过特征相联系。基于上述的理解我们可以把推荐系统的核心任务拆分位两个部分1
> 如何给用户生成特征
> 如何根据特征找到物品
推荐系统的需求有很多,可以根据不同的需求设计不同的推荐引擎,通过不同的推荐引擎来满足客户的需求。
7.3 推荐引擎的架构
推荐引擎使用一种或几种用户特征,按照一种推荐策略生成一种类型物品的推荐列表。一个规则引擎的概念图如下所示:
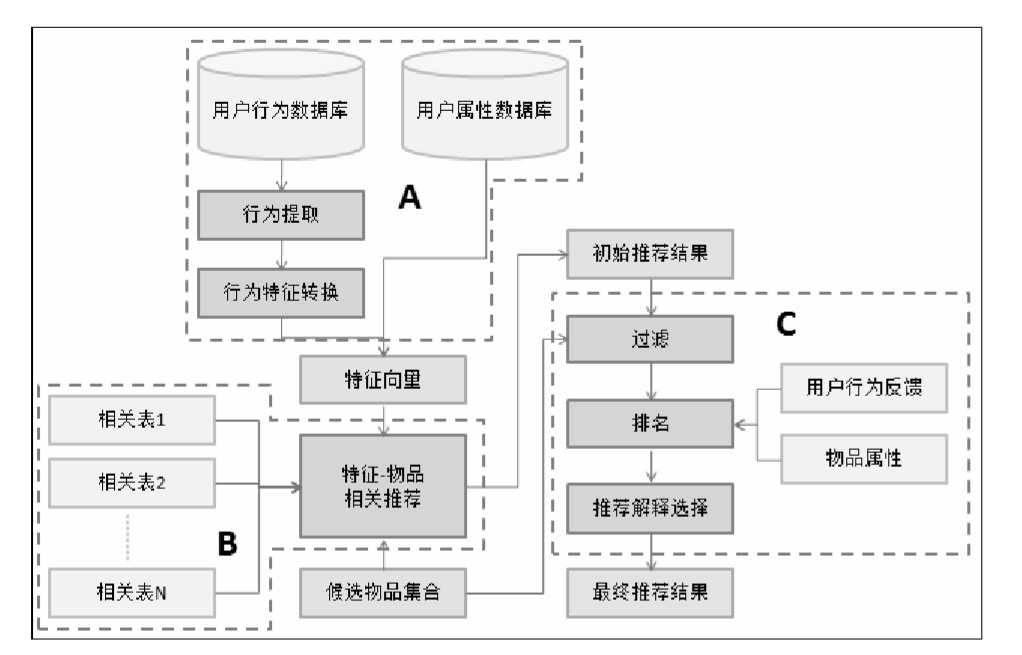
> A部分从缓存中拿到用户的行为数据,通过分析用户的行为获取特征向量
> B部分将特征向量结合特征-物品矩阵生成初始的推荐列表
> C部分对初始的列表进行处理,从而生成最终的推荐结果。
生成用户特征向量
用户的特征一般有两种:一种是注册的时候获取的,另一种是通过用户的行为计算出来的。
计算用户特征向量主要考虑:
> 用户行为的种类 一般的标准是用户付出代价越大的行为权重越大
> 用户行为产生的时间 近期行为权重大
> 用户行为次数 次数越多行为权重越大
> 物品的热门程度 对不怎么热门的物品做出的行为更具备参考价值
特征-物品相关推荐
过滤模块
通常会过滤的物品:
> 用户已经产生过行为的物品 (保证新颖性)
> 候选物品以外的物品
> 质量不合格的物品
排名模块
(1)新颖性排名
考虑对热门的物品降权:![]()
在计算$p_{ui}$的时候考虑到新颖性问题,对于![]() ,$r_{uj}$表示用户u对物品j的反馈度(可以理解为行为次数),类似的对其适当降权
,$r_{uj}$表示用户u对物品j的反馈度(可以理解为行为次数),类似的对其适当降权![]() 考虑到推荐系统是为了给用户介绍他们不熟悉的物品,那么可以假设如果用户知道了物品j,对物品j产生过行为,那么和j相似的且比j热门的物品用户应该也有比较大的概率知道,因此可以降低这种物品的权重,如下所示:
考虑到推荐系统是为了给用户介绍他们不熟悉的物品,那么可以假设如果用户知道了物品j,对物品j产生过行为,那么和j相似的且比j热门的物品用户应该也有比较大的概率知道,因此可以降低这种物品的权重,如下所示: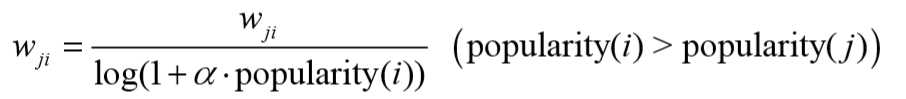
(2)多样性排名
标签:splay 存储 通过 如何 分布式 权重 dfs width mamicode
原文地址:https://www.cnblogs.com/z1141000271/p/11393479.html