标签:负载 image 行数据 hadoop2 col hadoop 访问 列表 注意
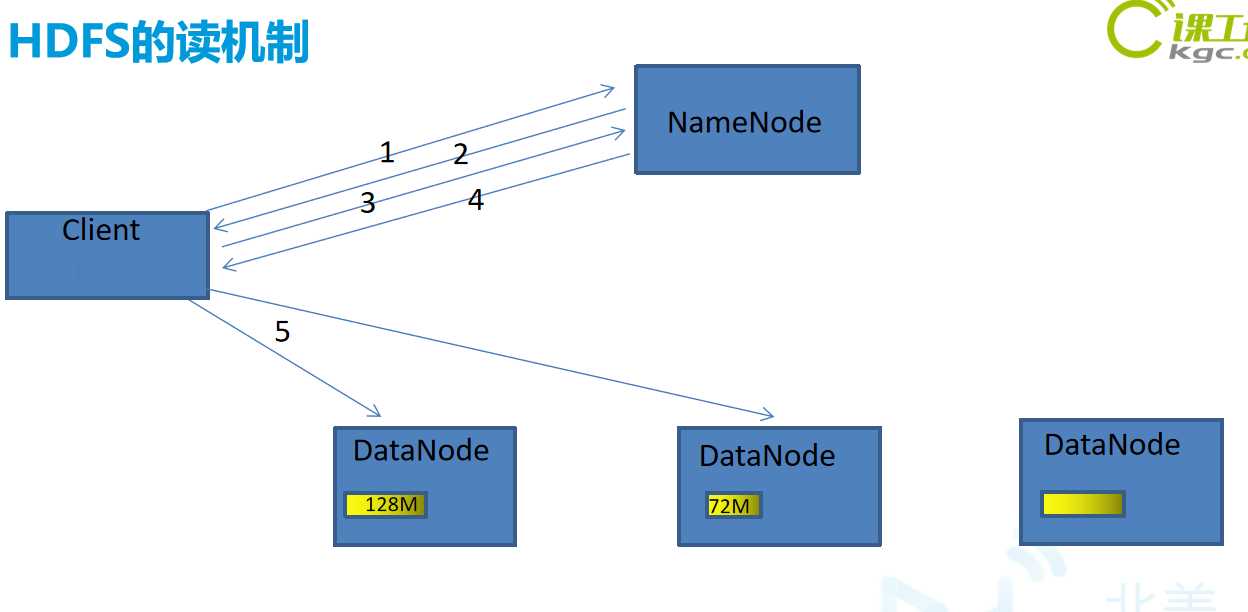
在将文件上传到hdfs之间需要分块,这个块就是block,默认为128MB(hadoop2.X),当然可以更改。通过修改core-default.xml文件修改这个值,它是最大的一个单位。
Packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传输数据的基本单位,默认是64kb。
Chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认为512B,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk的大小为516B。由此可见真实数据与校验值的比值约为128:1
注意:
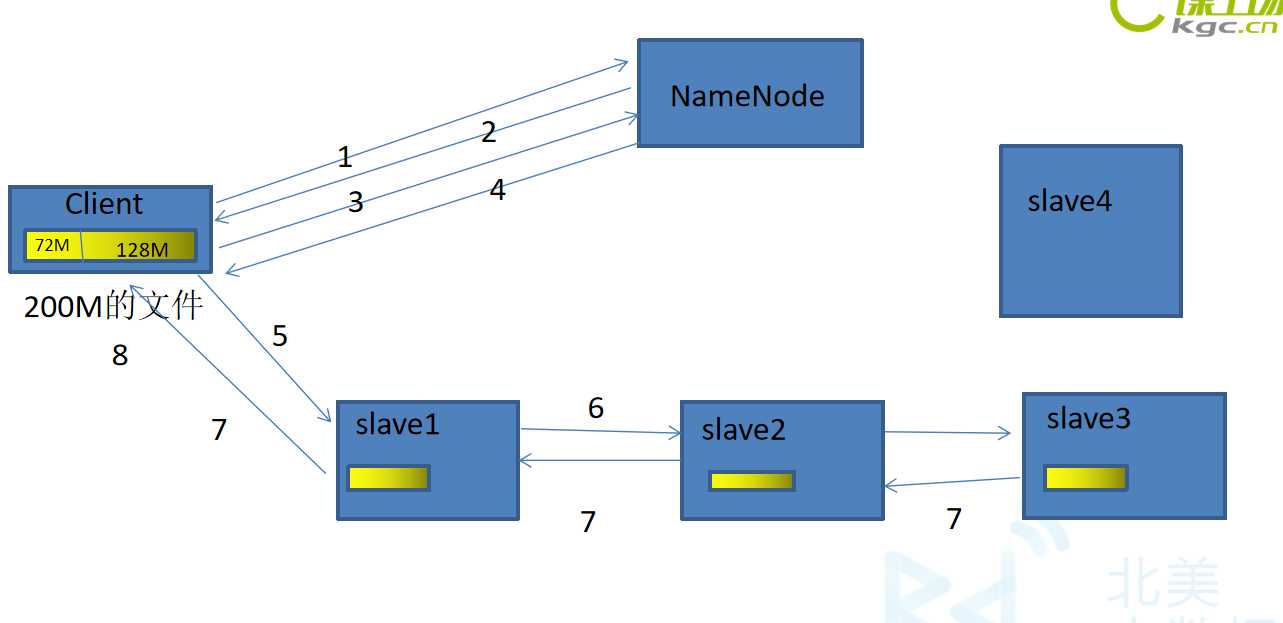
如果在传输的时候,DataNode宕机了,这个DataNode就会从这个管道中退出。剩下的DataNode继续传输。然后,等传输完成以后,NameNode会再分发出一个节点,去写成功的DataNode上复制出一份Block块,写到新的DataNode上。
标签:负载 image 行数据 hadoop2 col hadoop 访问 列表 注意
原文地址:https://www.cnblogs.com/tkzm/p/11400639.html