标签:ddr family 小数 bash 字母 via 它的 sep 行号
在Linux系统中常见的文件处理工具中grep和sed支持基础正则表达式。选项:
- -i:查找时不区分大小写字母;
- -v:反向查找,将不符合查找条件的列都显示出来;
- -n:将输出的结果显示行号;
- -A:后面可以追加数字,为after的意思,除了列出该行外,后面的n行也列出来;
- -B:与“-A”的作用相反,它是除了该行以外,前面的n行也列出来;
示例(在命令执行后的输出结果中,标红的就是查找到的内容):
[root@localhost ~]# dmesg | grep ‘Ebtables‘ #dmesg是列出核心信息,然后过滤出 包含‘Ebtables‘ 字符的行
[ 18.440389] ‘Ebtables‘ v2.0 registered
[root@localhost ~]# dmesg | grep -n -A3 -B2 ‘Ebtables‘
#这是将过滤的内容显示行号,并且列出 ‘Ebtables‘ 该行,以及它的后面三行以及前面两行
1773-[ 7.850479] NET: Registered protocol family 40
1774-[ 18.203047] ip6_tables: (C) 2000-2006 Netfilter Core Team
1775:[ 18.440389] ‘Ebtables‘ v2.0 registered
1776-[ 18.510067] nf_conntrack version 0.5.0 (16384 buckets, 65536 max)
1777-[ 18.714192] bridge: automatic filtering via arp/ip/ip6tables has been deprecated. Update your scripts to load br_netfilter if you need this.
1778-[ 18.783253] IPv6: ADDRCONF(NETDEV_UP): ens33: link is not ready
[root@localhost ~]# grep -in ‘bash‘ /etc/passwd
#查找该文件中的“bash”字符,提示:拥有“bash”字符的都是可以登录到系统的用户。
1:root:x:0:0:root:/root:/bin/bash
43:lisi:x:1000:1000:lisi:/home/lisi:/bin/bash
[root@localhost ~]# grep -in ‘pr[io]‘ /etc/passwd “pr”后面要么是i要么是o的行
14:systemd-bus-‘pro‘xy:x:999:997:systemd Bus ‘Pro‘xy:/:/sbin/nologin
28:rtkit:x:172:172:RealtimeKit:/‘pro‘c:/sbin/nologin
41:sshd:x:74:74:‘Pri‘vilege-separated SSH:/var/empty/sshd:/sbin/nologin
[root@localhost /]# grep -n ‘^the‘ test.txt #查找文件中以the开头的行,并显示行号
4:‘the‘ tongue is boneless bu it breaks bones.12!
[root@localhost /]# grep -n ‘^[a-z]‘ test.txt #搜索文件中以小写字母开头的行
1:he was short and fat.
4:the tongue is boneless bu it breaks bones.12!
5:google is the best tools for search keyword.
8:a wood cross!
[root@localhost ~]# grep -n ^[^a-zA-Z] test.txt #搜索不以字母开头的行
11:#woood #
12:#woooooood #
[root@localhost ~]# grep -n "\.$" test.txt #搜索以.结尾的行
1:he was short and fat.
2:He was wearing a blue polo shirt with black pants.
3:The home of Football on BBC Sport online.
5:google is the best tools for search keyword.
6:The year ahead will test our political establishment to the limit.
15:Misfortunes never come alone/single.
16:I shouldn‘t have lett so tast.
[root@localhost ~]# grep -n "^$" test.txt #显示空行
10:
17:正则表达式中的特殊符号及其意义(大多数可以以另一种方式表达,这里只是做一个记录,以便日后查阅):
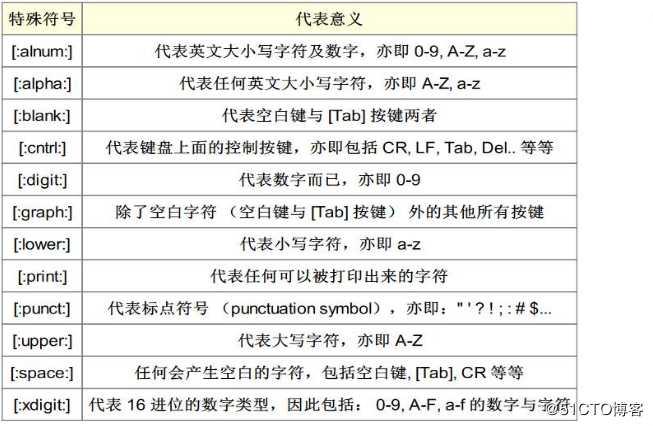
- . (小数点):代表一定有一个任意字符;
- * (星号):代表重复前一个字符,可以重复0次到无穷多的意思(0表示也可以没有前面那个字符)。
使用举例:
[root@localhost ~]# grep -n ‘sh..t‘ test.txt #查询以sh开头,以t结尾,中间最少有两个字符的行
1:he was ‘short‘ and fat.
2:He was wearing a blue polo ‘shirt‘ with black pants.
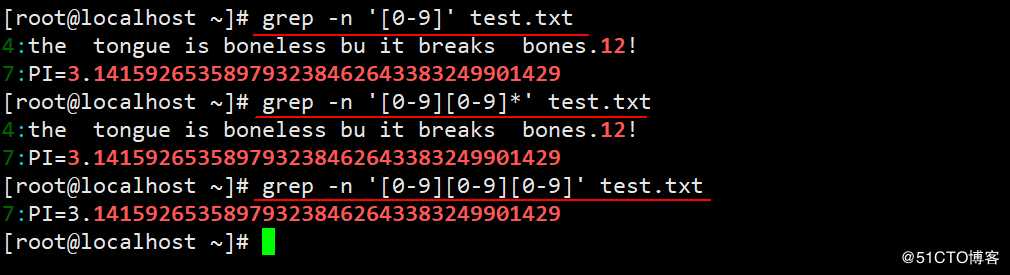
[root@localhost ~]# grep -n ‘wo*‘ test.txt #查找以w开头,后面有0个或无穷多个o的行
1:he ‘w‘as short and fat.
2:He ‘w‘as ‘w‘earing a blue polo shirt ‘w‘ith black pants.
5:google is the best tools for search key‘wo‘rd.
6:The year ahead ‘w‘ill test our political establishment to the limit.
8:a ‘woo‘d cross!
9:Actions speak louder than ‘wo‘rds
11:#‘wooo‘d #
12:#‘wooooooo‘d #由于上面的显示方式,并不友好,我还要将过滤结果标红,所以接下来我就上截图了。


自己看下面的执行结果:



一般来说基础正则表达式足以我们使用了,但如果想要简化整个指令,那么就可以使用扩展正则表达式,如果使用扩展正则表达式,需要使用egrep或awk命令,常见的扩展正则表达式的元字符主要包括如下几个:
扩展正则表达式字符汇总: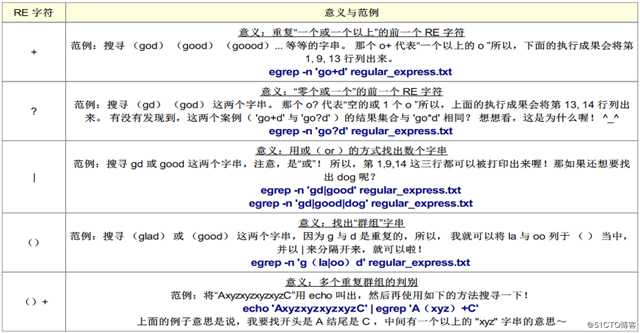
标签:ddr family 小数 bash 字母 via 它的 sep 行号
原文地址:https://blog.51cto.com/14154700/2432199