标签:blog http os ar 使用 strong sp 文件 数据
引言
Bitcask 是一种 key-value 存储实现模型,其中心思想是 Append 写文件,内存索引加速文件读,通过闲时 Merge 文件减少数据冗余。下面我们从存储方式、索引和缓存三个方面学习 Bitcask 的具体实现方法。
数据存储方式
Bitcask 中,数据以文本的形式存储,增删改的数据以 Append 的形式追加到数据文件结尾,在数据存放目录下,我们定义两类文件:
xxx.w:数据存储文件,xxx 是一个数值,写满1G数据将新建文件,数值自增,程序往数值最大的一个文件 Append 数据
write.pos:记录当前数值最大的 xxx.w 文件(FileNo),以及该文件的写位移(Offset)
定义了数据文件和记录写位移的文件后,我们通过以下方式实现数据写:
读操作同样很简单,对该条数据所在文件的偏移位置读取定长数据。
那问题来了,写操作有 write.pos 文件指明要写入的 FileNo 和 Offset;对于读操作,如何快速地从浩瀚的数据中,找到某个 key 对应数据所在的文件和文件位移呢?挖掘技术到底哪家强?
数据索引
快速地获取 skey 对应的数据,依赖于内存中的数据索引。skey 对应的 FileNo、Offset 以索引的方式存在内存中,下图说明了数据索引的具体实现:
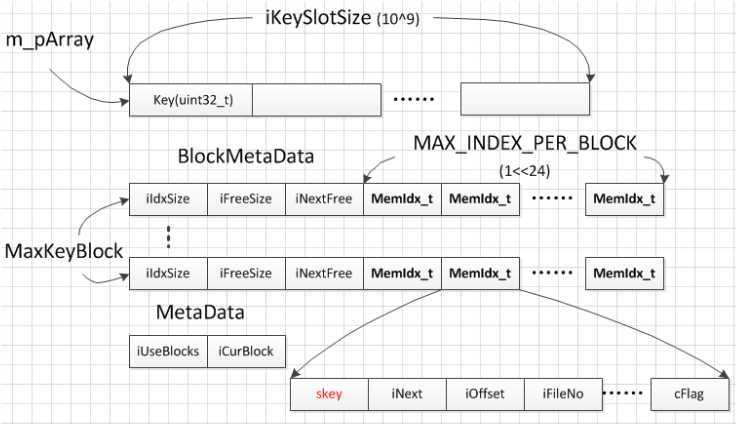
实现数据索引的数据结构主要有:
m_pArray数组:长度为 KeySlotSize、以 unsigned int 为元素的数组,负责存储数据索引(MemIdx_t)的索引
KeyBlock组:由 MaxKeyBlock 个 KeyBlock 组成,每一个 KeyBlock 由一个 BlockMetaData 和 MAX_INDEX_PER_BLOCK 个 MemIdx_t 组成
BlockMetaData:存放该 KeyBlock 中有多少个空闲 MemIdx_t 索引等统计数据
MemIdx_t:数据索引,其中 skey(字符串,chat*类型)即为数据的 key,FileNo 和 Offset 分别为 skey 对应数据所在的文件和位移
MetaData:指示 KeyBlock 总数、当前使用的 KeyBlock
m_pArray数组中的 key 作为索引 MemIdx_t 的索引,其与 skey 存在这样的关系:
建立 key 后,根据 skey 找到对应的磁盘数据块就变得简单了:
数据缓存
像很多其他数据库一样,我们也可以实现自己的缓存,即访问 skey 对应数据的时候,不是直接走以上步骤从磁盘读取数据,而是先看内存中有没有相应数据,有的话取内存数据,减少磁盘访问。实现缓存的数据结构如下:
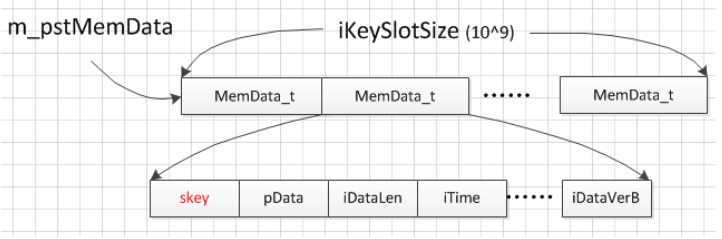
有了缓存,读取数据变成了以下过程:
同样在新增数据的时候,完成写盘后会更新数据缓存中 skey 相应的数据。
小结
本文从数据存储方式、索引、缓存三方面介绍了 Bitcask 的一种具体实现方法。增删改都用 Append 的实现方式简洁、提高了写盘效率,其通过闲时 Merge 消除数据冗余。
标签:blog http os ar 使用 strong sp 文件 数据
原文地址:http://www.cnblogs.com/bangerlee/p/4050047.html