标签:code mod ash 命名 The div belle 时间 词法
LTP(Language Technology Platform)为中文语言技术平台,是哈工大社会计算与信息检索研究中心开发的一整套中文语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块(包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library,DLL)的应用程序接口,可视化工具,并且能够以网络服务的形式进行使用。
LTP开发文档:
https://ltp.readthedocs.io/zh_CN/latest/index.html
语言云LTP-Cloud:
http://www.ltp-cloud.com/
模型下载地址:
http://ltp.ai/download.html
下面介绍 Windows10 Python 环境下 LTP 的扩展包 pyltp 安装过程。
1.常见错误
大家通常会调用 “pip install pyltp” 安装该扩展包,但会遇到各种错误,下面介绍一种可行的方法。
2.安装pyltp包
首先,安装Python3.6环境,如下图所示“python-3.6.7-amd64.exe”。
接着,下载pyltp扩展包的whl文件至本地,调用CMD环境进行安装,注意需要将所在文件的路径写清楚。
pyltp-0.2.1-cp35-cp35m-win_amd64.whl(对应Python3.5版本)
pyltp-0.2.1-cp36-cp36m-win_amd64.whl(对应Python3.6版本)
1 pip install C:Python36spyltp-0.2.1-cp36-cp36m-win_amd64.whl
安装pyltp时遇到的错误 ===>> https://www.cnblogs.com/huangm1314/p/11320553.html
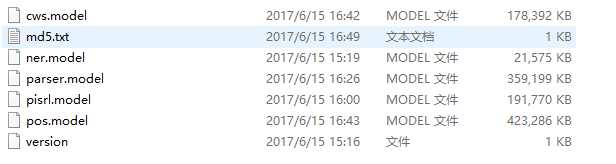
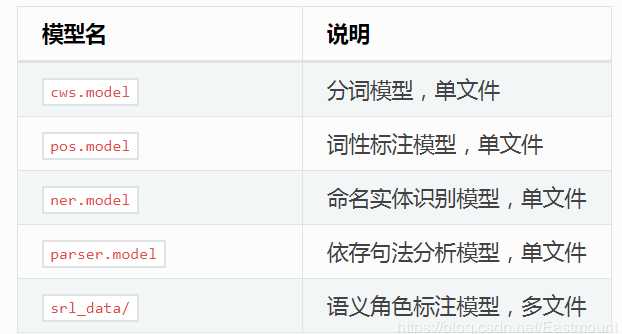
3.下载模型文件
七牛云
http://ltp.ai/download.html
1 from pyltp import SentenceSplitter 2 sentence = SentenceSplitter.split(‘我是风儿,你是傻。缠缠绵绵到天涯!‘) 3 print(sentence) 4 print(‘\n‘.join(sentence))
输出:
1 <pyltp.VectorOfString object at 0x000001C4B3C27570> 2 我是风儿,你是傻。 3 缠缠绵绵到天涯!
1 from pyltp import Segmentor 2 import os 3 LTP_MODEL_DIR = ‘F:\ltp_data_v3.4.0\ltp_data_v3.4.0‘ 4 cws_model = os.path.join(LTP_MODEL_DIR, ‘cws.model‘) 5 6 segmentor = Segmentor() # 初始化实例 7 segmentor.load(cws_model) # 加载模型 8 words = segmentor.segment(‘欧几里得是西元前三世纪的希腊数学家。‘) # 分词 9 print(‘分词‘, words) 10 print(‘ ‘.join(words)) 11 segmentor.release() # 释放模型
分词结果如下:
1 分词 <pyltp.VectorOfString object at 0x000001CDB6717570> 2 欧 几 里 得 是 西元前 三 世纪 的 希腊 数学家 。
pyltp分词支持用户使用自定义词典。分词外部词典本身是一个文本文件,每行指定一个词,编码须为 UTF-8,样例如下所示:
1 欧几里得 2 亚里士多德
使用自定义词典进行分词的模型加载方式如下:
1 segmentor = Segmentor() # 初始化实例 2 segmentor.load_with_lexicon(cws_model, ‘./word_dic.txt‘) # 加载模型 3 words = segmentor.segment(‘欧几里得是西元前三世纪的希腊数学家。‘) # 分词 4 print(‘分词‘, words) 5 print(‘ ‘.join(words)) 6 segmentor.release() # 释放模型
自定义词典,分词结果如下,分词效果明显得到改善。
1 分词 <pyltp.VectorOfString object at 0x0000027657917570> 2 [INFO] 2019-08-08 21:44:53 loaded 2 lexicon entries 3 欧几里得 是 西元前 三 世纪 的 希腊 数学家 。
1 from pyltp import Postagger 2 import os 3 LTP_MODEL_DIR = ‘F:\ltp_data_v3.4.0\ltp_data_v3.4.0‘ 4 pos_model = os.path.join(LTP_MODEL_DIR, ‘pos.model‘) 5 6 postagger = Postagger() # 初始化实例 7 postagger.load(pos_model) # 加载模型 8 9 words = [‘欧几里得‘,‘是‘,‘西元前‘,‘三‘,‘世纪‘,‘的‘,‘希腊‘,‘数学家‘,‘。‘] 10 postags = postagger.postag(words) 11 12 for word,pos in zip(words, postags): 13 print(word,pos) 14 postagger.release() # 释放模型
词性标注结果如下:
nh v nt m n u ns n wp
# 欧几里得 - nh - 人名
# 是 - v - 动词
# 西元前 - nt - 时间名词
# 三 - m - 数字
# 世纪 - n - 普通名词
# 的 - u - 助词
# 希腊 - ns - 地理名词
# 数学家- n - 普通名词
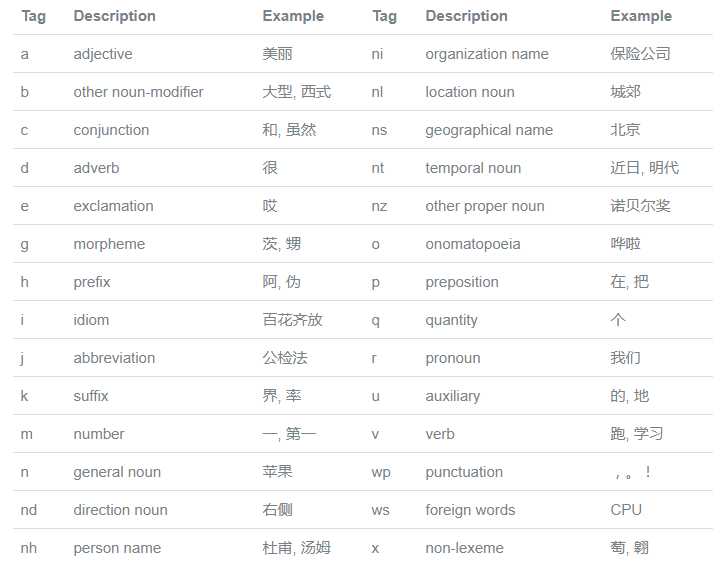
# 。 - wp - 标点符号更多的词性含义:
1 from pyltp import NamedEntityRecognizer 2 import os 3 LTP_MODEL_DIR = ‘F:\ltp_data_v3.4.0\ltp_data_v3.4.0‘ 4 5 ner_model = os.path.join(LTP_MODEL_DIR, ‘ner.model‘) 6 7 recognizer = NamedEntityRecognizer() # 初始化实例 8 recognizer.load(ner_model) #加载模型 9 10 words = [‘欧几里得‘, ‘是‘, ‘西元前‘, ‘三‘, ‘世纪‘, ‘的‘, ‘希腊‘, ‘数学家‘, ‘。‘] 11 postags = [‘nh‘, ‘v‘, ‘nt‘, ‘m‘, ‘n‘, ‘u‘, ‘ns‘, ‘n‘, ‘wp‘] 12 13 nertags = recognizer.recognize(words, postags) 14 15 print(‘ ‘.join(nertags)) 16 recognizer.release() # 释放模型
命名实体结果如下,ltp命名实体类型为:人名(Nh),地名(NS),机构名(Ni);ltp采用BIESO标注体系。B表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成实体。
1 S-Nh O O O O O S-Ns O O 2 # 欧几里得 - S-Nh - 人名 3 # 希腊 - S-Ns - 地名

1 from pyltp import Parser 2 import os 3 LTP_MODEL_DIR = ‘F:\ltp_data_v3.4.0\ltp_data_v3.4.0‘ 4 5 par_model = os.path.join(LTP_MODEL_DIR, ‘parser.model‘) #依存句法分析模型路径,模型名称为`parser.model 6 7 parser = Parser() # 初始化实例 8 parser.load(par_model) # 加载模型 9 10 words = [‘欧几里得‘, ‘是‘, ‘西元前‘, ‘三‘, ‘世纪‘, ‘的‘, ‘希腊‘, ‘数学家‘, ‘。‘] 11 postags = [‘nh‘, ‘v‘, ‘nt‘, ‘m‘, ‘n‘, ‘u‘, ‘ns‘, ‘n‘, ‘wp‘] 12 arcs = parser.parse(words, postags) # 句法分析 13 14 rely_id = [arc.head for arc in arcs] # 提取依存父节点id 15 relation = [arc.relation for arc in arcs] # 提取依存关系 16 heads = [‘Root‘ if id == 0 else words[id - 1] for id in rely_id] 17 18 for i in range(len(words)): 19 print(f‘{relation[i]}->({words[i]},{heads[i]})‘) 20 parser.release()
依存句法分析,输出结果如下:
1 SBV(欧几里得, 是) 2 HED(是, Root) 3 ATT(西元前, 世纪) 4 ATT(三, 世纪) 5 ATT(世纪, 数学家) 6 RAD(的, 世纪) 7 ATT(希腊, 数学家) 8 VOB(数学家, 是) 9 WP(。, 是)
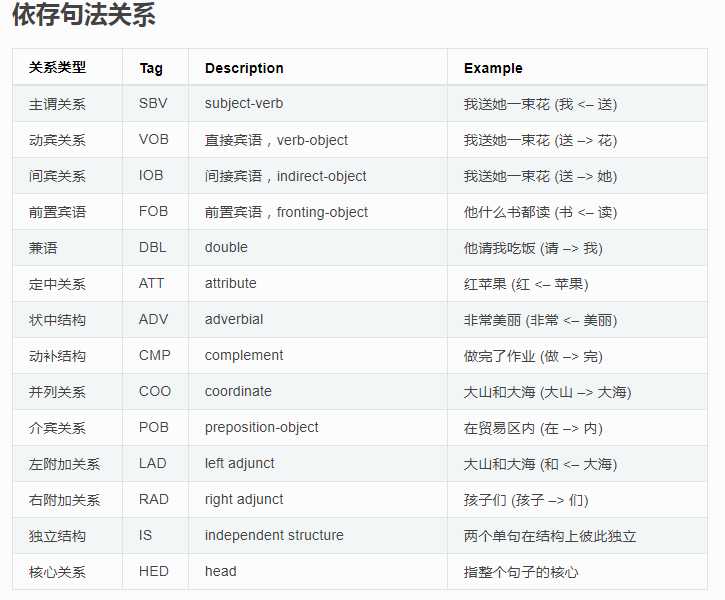
更多关于依存句法:
1 import os 2 LTP_DATA_DIR = ‘/path/to/your/ltp_data‘ # ltp模型目录的路径 3 srl_model_path = os.path.join(LTP_DATA_DIR, ‘srl‘) # 语义角色标注模型目录路径,模型目录为`srl`。注意该模型路径是一个目录,而不是一个文件。 4 5 from pyltp import SementicRoleLabeller 6 labeller = SementicRoleLabeller() # 初始化实例 7 labeller.load(srl_model_path) # 加载模型 8 9 words = [‘元芳‘, ‘你‘, ‘怎么‘, ‘看‘] 10 postags = [‘nh‘, ‘r‘, ‘r‘, ‘v‘] 11 # arcs 使用依存句法分析的结果 12 roles = labeller.label(words, postags, arcs) # 语义角色标注 13 14 # 打印结果 15 for role in roles: 16 print role.index, "".join( 17 ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]) 18 labeller.release() # 释放模型
结果如下:
1 3 A0:(0,0)A0:(1,1)ADV:(2,2)
第一个词开始的索引依次为0、1、2…
返回结果 roles 是关于多个谓词的语义角色分析的结果。由于一句话中可能不含有语义角色,所以结果可能为空。
role.index 代表谓词的索引, role.arguments 代表关于该谓词的若干语义角色。
arg.name 表示语义角色类型,arg.range.start 表示该语义角色起始词位置的索引,arg.range.end 表示该语义角色结束词位置的索引。
例如上面的例子,由于结果输出一行,所以“元芳你怎么看”有一组语义角色。 其谓词索引为3,即“看”。这个谓词有三个语义角色,范围分别是(0,0)即“元芳”,(1,1)即“你”,(2,2)即“怎么”,类型分别是A0、A0、ADV。
arg.name 表示语义角色关系,arg.range.start 表示起始词位置,arg.range.end 表示结束位置。
更多语义角色模型如下:
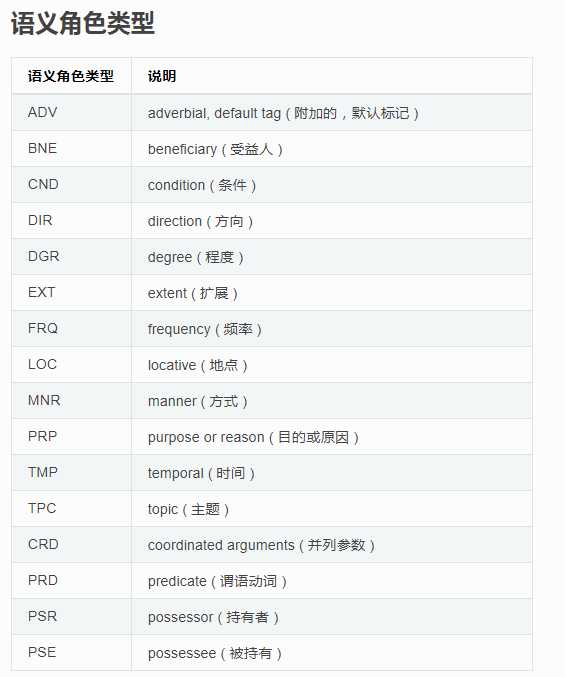
参考文档:
http://www.ltp-cloud.com/intro#pos_how
标签:code mod ash 命名 The div belle 时间 词法
原文地址:https://www.cnblogs.com/huangm1314/p/11323829.html