标签:直接 避免 覆盖 concat procedure and dex varchar arc
知识回顾:数据都是存在硬盘上的,那查询数据不可避免的需要进行IO操作
*索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。*
* primary key
* unique key 快 加 约束
* index key 只有快
foreign key 是建表与表之间的关系
注意foreign key不是用来加速查询用的,不在我们研究范围之内,上面三种key前两种除了有加速查询的效果之外还有额外的约束条件(primary key:非空且唯一,unique key:唯一),而index key没有任何约束功能只会帮你加速查询
索引就是一种数据结构,类似于书的目录。意 味着以后再查数据应该先找目录再找数据,而不是用翻页的方式查询数据
**本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引的影响:**
* 在表中有大量数据的前提下,创建索引速度会很慢
* 在索引创建完毕后,对表的查询性能会大幅度提升,但是写的性能会降低
b+树
<https://images2017.cnblogs.com/blog/1036857/201709/1036857-20170912011123500-158121126.png>
只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据
查询次数由树的层级决定,层级越低次数越少
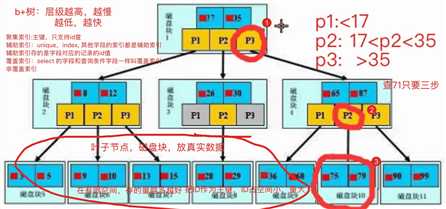
一个磁盘块儿的大小是一定的,那也就意味着能存的数据量是一定的。如何保证树的层级最低呢?一个磁盘块儿存放占用空间比较小的数据项
思考我们应该给我们一张表里面的什么字段字段建立索引能够降低树的层级高度>>> 主键id字段
聚集索引(primary key)** 一张表中有且只有一个主键
聚集索引其实指的就是表的主键,innodb引擎规定一张表中必须要有主键。先来回顾一下存储引擎。
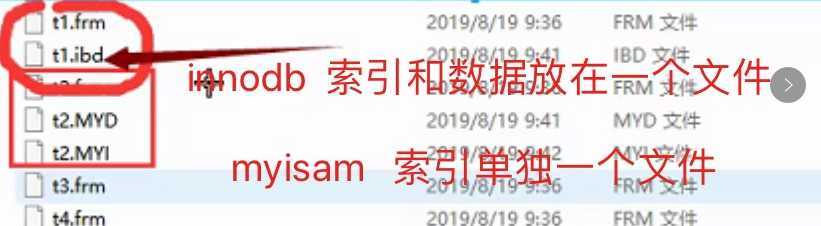
myisam在建表的时候对应到硬盘有几个文件(三个)?
innodb在建表的时候对应到硬盘有几个文件(两个)?frm文件只存放表结构,不可能放索引,也就意味着innodb的索引跟数据都放在idb表数据文件中。
**特点:**叶子结点放的一条条完整的记录
辅助索引(unique,index)
辅助索引:查询数据的时候不可能都是用id作为筛选条件,也可能会用name,password等字段信息,那么这个时候就无法利用到聚集索引的加速查询效果。就需要给其他字段建立索引,这些索引就叫辅助索引
**特点:**叶子结点存放的是辅助索引字段对应的那条记录的主键的值(比如:按照name字段创建索引,那么叶子节点存放的是:{name对应的值:name所在的那条记录的主键值})
select name from user where name=‘jason‘;
上述语句叫覆盖索引:只在辅助索引的叶子节点中就已经找到了所有我们想要的数据
select 后的字段 和你的 辅助索引 一样就是 覆盖索引
select age from user where name=‘jason‘;
上述语句叫非覆盖索引,虽然查询的时候命中了索引字段name,但是要查的是age字段,所以还需要利用主键才去查找
测试
#1. 准备表 create table s1( id int, name varchar(20), gender char(6), email varchar(50) ); #2. 创建存储过程,实现批量插入记录 delimiter $$ #声明存储过程的结束符号为$$ create procedure auto_insert1() BEGIN declare i int default 1; while(i<3000000)do insert into s1 values(i,‘jason‘,‘male‘,concat(‘jason‘,i,‘@oldboy‘)); set i=i+1; end while; END$$ #$$结束 delimiter ; #重新声明 分号为结束符号 #3. 查看存储过程 show create procedure auto_insert1\G #4. 调用存储过程 call auto_insert1(); ``` ``` mysql # 表没有任何索引的情况下 select * from s1 where id=30000; # 避免打印带来的时间损耗 select count(id) from s1 where id = 30000; select count(id) from s1 where id = 1; # 给id做一个主键 alter table s1 add primary key(id); # 速度很慢 select count(id) from s1 where id = 1; # 速度相较于未建索引之前两者差着数量级 select count(id) from s1 where name = ‘jason‘ # 速度仍然很慢 """ 范围问题 """ # 并不是加了索引,以后查询的时候按照这个字段速度就一定快 select count(id) from s1 where id > 1; # 速度相较于id = 1慢了很多 select count(id) from s1 where id >1 and id < 3; select count(id) from s1 where id > 1 and id < 10000; select count(id) from s1 where id != 3; alter table s1 drop primary key; # 删除主键 单独再来研究name字段 select count(id) from s1 where name = ‘jason‘; # 又慢了 create index idx_name on s1(name); # 给s1表的name字段创建索引 select count(id) from s1 where name = ‘jason‘ # 仍然很慢!!! """ 再来看b+树的原理,数据需要区分度比较高,而我们这张表全是jason,根本无法区分 那这个树其实就建成了“一根棍子” """ select count(id) from s1 where name = ‘xxx‘; # 这个会很快,我就是一根棍,第一个不匹配直接不需要再往下走了 select count(id) from s1 where name like ‘xxx‘; select count(id) from s1 where name like ‘xxx%‘; select count(id) from s1 where name like ‘%xxx‘; # 慢 最左匹配特性 # 区分度低的字段不能建索引 drop index idx_name on s1; # 给id字段建普通的索引 create index idx_id on s1(id); select count(id) from s1 where id = 3; # 快了 select count(id) from s1 where id*12 = 3; # 慢了 索引的字段一定不要参与计算 drop index idx_id on s1; select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id = 3 and email = ‘xxx‘; # 针对上面这种连续多个and的操作,mysql会从左到右先找区分度比较高的索引字段,先将整体范围降下来再去比较其他条件 create index idx_name on s1(name); select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id = 3 and email = ‘xxx‘; # 并没有加速 drop index idx_name on s1; # 给name,gender这种区分度不高的字段加上索引并不难加快查询速度 create index idx_id on s1(id); select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id = 3 and email = ‘xxx‘; # 快了 先通过id已经讲数据快速锁定成了一条了 select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id > 3 and email = ‘xxx‘; # 慢了 基于id查出来的数据仍然很多,然后还要去比较其他字段 drop index idx_id on s1 create index idx_email on s1(email); select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id > 3 and email = ‘xxx‘; # 快 通过email字段一剑封喉 ``` #### 联合索引 ```mysql select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id > 3 and email = ‘xxx‘; # 如果上述四个字段区分度都很高,那给谁建都能加速查询 # 给email加然而不用email字段 select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id > 3; # 给name加然而不用name字段 select count(id) from s1 where gender = ‘male‘ and id > 3; # 给gender加然而不用gender字段 select count(id) from s1 where id > 3; # 带来的问题是所有的字段都建了索引然而都没有用到,还需要花费四次建立的时间 create index idx_all on s1(email,name,gender,id); # 最左匹配原则,区分度高的往左放 select count(id) from s1 where name=‘jason‘ and gender = ‘male‘ and id > 3 and email = ‘xxx‘; # 速度变快 ``` 总结:上面这些操作,你感兴趣可以敲一敲,不感兴趣你就可以不用敲了,权当看个乐呵。理论掌握了就行了 慢查询日志 设定一个时间检测所有超出改时间的sql语句,然后针对性的进行优化!
标签:直接 避免 覆盖 concat procedure and dex varchar arc
原文地址:https://www.cnblogs.com/lddragon/p/11405338.html