标签:字母 最优 领域 转换 好处 一个个 分词 左右 方法
当前文本向量化主流的方式是word2vec词向量技术,从基于统计的方法,到基于神经网络的方法,掌握word2vec词向量技术是学习文本向量化的最好的方式
下面是Tomas MIkolov的三篇有关word embedding的文章:
1、Efficient Estimation of Word Representation in Vector Space, 2013
2、Distributed Representations of Sentences and Documents, 2014
3、Enriching Word Vectors with Subword Information, 2016
因此严格意义上说,word2vec是一个2013年出现的新方法,15年以后逐渐流行起来。
什么是word2vec?
word2vec是词的一种表示,它将词以固定维数的向量表示出来。是用来将一个个的词变成词向量的工具。例如:“我爱中国”这句话通过分词为 我/ 爱/ 中国。那么这时候三个词都将表示为n维的词向量。中国 = [x1,x2,…,xn]
为什么要用word2vec?word2vec有什么好处。
传统的基于词袋模型 one-hot representation在判定同义词,相似句子的时候很无力。
例如在一个只有两个词的词典中。快递被编码为v1 = [0,1],快件被编码为v2 =[1,0],计算两个的相似度。为v1*v2 = 0。
word2vec充分利用上下文信息,对上下文进行训练。
每个词不在是 只有一个位置为1,其余位置为0的稀疏向量。而是一个稠密的固定维度向量。直观上可减少额外存储和计算开销。
其次,在深层次的语义理解上,经过训练后的词向量能利用上下文信息。能判定找出相似词语。
例如word2vec从大量文本语料中以无监督的方式学习语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。比如“机器”和“机械”意思很相近,而“机器”和“猴子”的意思相差就很远了,那么由word2vec构建的这个数值空间中,“机器”和“机械”的距离较“机器”和“猴子”的距离而言是要近很多的。
word2vec有哪几种实现方式?
共两种:1)用上下文预测中心词cbow(continue bag of word)
2)利用中心词预测上下文 skip-gram
从实现方式上看两者只是输入输出发生了变化。
word2vec的本质是什么?
当然是无监督学习,因为输出并没有label。但是从输入的和输出的形式上来看,输入的是一对对单词,看起来像是有监督,其实并不是。
因为词向量的本质可以看出是一个只有一层的神经网络,因此必须有输入,输出。而训练过程或者说目的不是得到预测结果单词,或对单词进行分类。最为关键的是获得hidden layer中权重。也就是说借助了sequence2sequence模型训练过程,得到hidden layer的权重。
sigmoid函数是什么?
sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
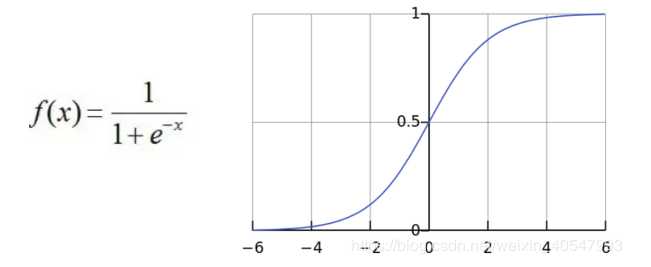
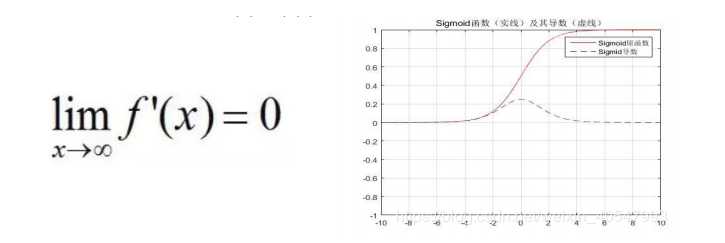
Sigmoid函数的基本性质:定义域:(−∞,+∞);值域:(0,1);函数在定义域内为连续和光滑;处处可导,导数为:f′(x)=f(x)(1−f(x))
Softmax函数
Softmax要解决这样一个问题:我有一个向量,想用数学方法把向量中的所有元素归一化为一个概率分布。也就是说,该向量中的元素在[0,1]范围内,且所有元素的和为1。
softmax就是这个数学方法,本质上是一个函数。
假设我们有一个k维向量z,我们想把它转换为一个k维向量 ,使其所有元素的范围是[0,1]且所有元素的和为1,函数表达式是:
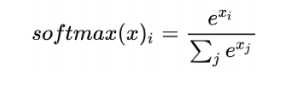
也就是说, 内的每一个元素是对z内的对应元素求指数,再除以所有元素求指数后的和。所以Softmax函数也叫做归一化指数函数(normalized exponential function)。
二叉树
二叉树是树的特殊一种,具有如下特点:1)每个结点最多有两颗子树,结点的度最大为2;2)左子树和右子树是有顺序的,次序不能颠倒;3)即使某结点只有一个子树,也要区分左右子树。
斜树:所有的结点都只有左子树(左斜树),或者只有右子树(右斜树)。这就是斜树,应用较少。如下图的左斜树与右斜树:
满二叉树:所有的分支结点都存在左子树和右子树,并且所有的叶子结点都在同一层上,这样就是满二叉树。就是完美圆满的意思,关键在于树的平衡。
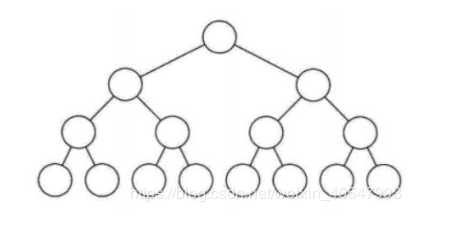
完全二叉树:对一棵具有n个结点的二叉树按层序排号,如果编号为i的结点与同样深度的满二叉树编号为i结点在二叉树中位置完全相同,就是完全二叉树。满二叉树必须是完全二叉树,反过来不一定成立。其中关键点是按层序编号,然后对应查找。
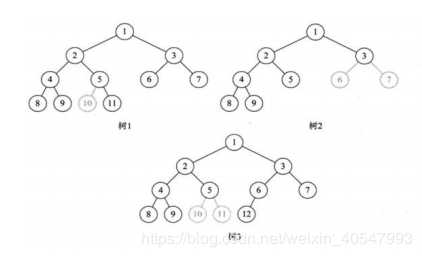
在上图中,树1,按层次编号5结点没有左子树,有右子树,10结点缺失。树2由于3结点没有字数,是的6,7位置空挡了。树3中结点5没有子树。所以上图都不是完全二叉树。
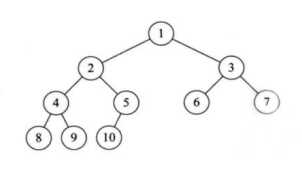
上图就是一个完全二叉树。结合完全二叉树定义得到其特点:1)叶子结点只能出现在最下一层(满二叉树继承而来);2)最下层叶子结点一定集中在左 部连续位置。3)倒数第二层,如有叶子节点,一定出现在右部连续位置。4)同样结点树的二叉树,完全二叉树的深度最小(满二叉树也是对的)。
Huffman树
在计算机科学中,树是一种很重要的非线性数据结构,它是数据元素(在树中称为结点)按分支关系组织起来的结构。若干棵互不相交的树所构成的集合称为森林。下面我们给出几个与树相关的常用概念。
路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层号为1,则从根结点到第L层结点的路径长度为L-1。
结点的权和带权路径长度:若为树中结点赋予一个具有某种含义的(非负)数值,则这个数值称为该结点的权。结点的带权路径长度是指,从根节点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:规定为所有叶子结点的带权路径长度之和。
Huffman树:给定n个权值作为n个叶子结点,构造一棵二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树。
Huffman树构造:给定n个权值{??1, ??2, … … , ???? }作为二叉树的n个叶子结点,可通过以下算法来构造一棵Huffman树。
Huffman树构造算法
(1)将 {??1, ??2, … … , ???? } 看成是有n棵树的森林(每棵树仅有一个结点)。
(2)在森林中选出两个根结点的权值最小的树合并,作为一棵新树的根结点权值为其左、右子树根结点权值之和。
(3)从森林中删除选取的两棵树,并将新树加入森林。
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求的Huffman树。
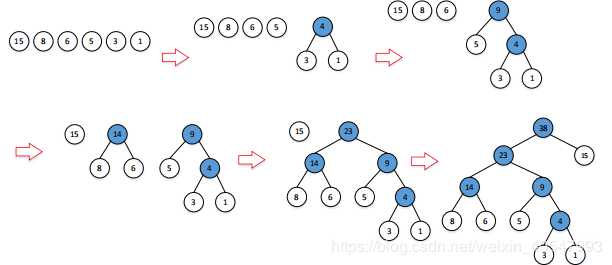
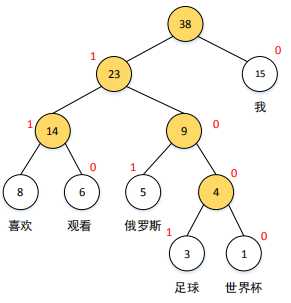
举个例子:假设去年世界杯期间,从新浪微博中抓取了若干条与足球相关的微博,经统计,“我”、“喜欢”、“观看”、“俄罗斯”、“足球”、“世界杯”这六个词出现的次数分别为15,8,6,5,3,1。请以这6个词为叶子结点,以相应词频当权值,构造一棵Huffman树。
在数据通信中,需要将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。例如,需传送的报文为“AFYER DATA EAR ARE ART AREA”,这里用到的字符集为“A,E,R,T,F,D”,各字母出现的次数为8,54,5,3,1,1.现要求为这些字母设计编码。
要区别6个字母,最简单的二机制编码方式是等长编码,固定采用3位二进制(2^3=8>6),可分别用000、001、010、011、100、101对“A,E,R,T,F,D”进行编码发送,当对方接收报文时再按照三位一分进行译码。
显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5(2^5=32>26).然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。
为使不等长编码为前缀编码(即要求一个字符的编码不能是另一个字符编码的前缀),可用字符集中的每个字符作为叶子结点生成一棵编码二叉树,为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度,效果上就是传送报文的最短长度。因此,求传送报文的最短长度问题转化为求由字符集中的所有字符作为叶子结点,由字符出现频率作为其权值所产生的Huffman树的问题。
利用Huffman树设计的二进制前缀编码,称为Huffman编码,它既能满足前缀编码的条件,又能保证报文编码总长最短。
文本领域如何用Huffman编码,它把训练语料中的词当成叶子结点,其在语料中出现的次数当作权值,通过构造相应的Huffman树来对每一个词进行Huffman编码。
下图中六个词的Huffman编码,其中约定(词频较大的)左孩子结点编码为1,(词频较小的)右孩子结点编码为0.这
样一来,“我”、“喜欢”、“观看”、“巴西”、“足球”、“世界杯”这六个词的Huffman编码分别为0,111,110,101,1001和1000.
什么是语言模型?
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?
比如下面三句话:
1)今天天气很好,我们去圆明园约会吧。
2)今天很好天气,我们去圆明园约会吧。
3)今天我们天气,很好去圆明园约会吧。
如何判断一个句子是否合理,很容易想到了一种很好的统计模型来解决上述问题,只需要看它在所有句子中出现的概率就行了。第一个句子出现的概率大概是80%,第二个句子出现的概率大概是50%,第三个句子出现的概率大概是20%,第一个句子出现的可能性最大,因此这个句子最为合理
如何计算一个句子出现的概率呢?
我们可以把有史以来人类说过的话都统计一遍,这样就能很方便的计算概率了。然而,你我都知道这条路走不通。
假设想知道S在文本中出现的可能性,也就是数学上所说的S的概率,既然S=w1,w2,...,wn,那么不妨把S展开表示,
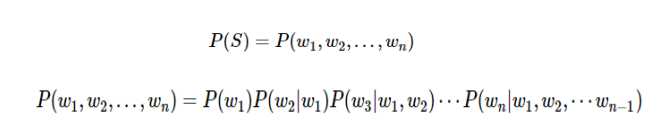
利用条件概率的公式,S这个序列出现的概率等于每一个词出现的条件概率的乘乘积,展开为:
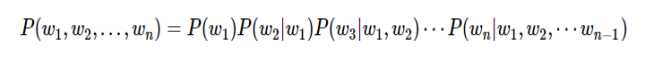
计算P(w1)很容易,P(w2|w1)也还能算出来,P(w3|w1,w2)已经非常难以计算了
所以这样的方法存在两个致命的缺陷:
1)參数空间过大:条件概率P(wn|w1,w2,..,wn-1)的可能性太多,无法估算,不可能有用;
2)数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。
马尔科夫假设
了解决參数空间过大的问题。引入了:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
即在此时,假设一个词wi出现的概率只与它前面的wi−1有关,这种假设称为1阶马尔科夫假设。现在,S的概率就变得简单了:
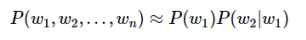
那么,接下来的问题就变成了估计条件概率P(wi|wi−1),根据它的定义,
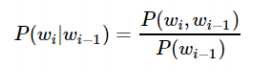
当样本量很大的时候,基于大数定律,一个短语或者词语出现的概率可以用其频率来表示,即
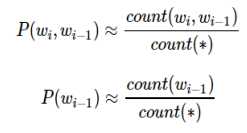
其中,count(i)表示词i出现的次数,count表示语料库的大小。那么
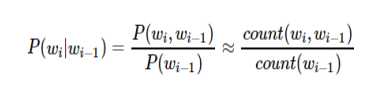
一元语言模型(unigram):
如果一个词的出现与它周围的词是独立的,称为一元语言模型
P(S ) = P(w1) * P(w2) * P(w3) * ...* P(wn)
二元语言模型(bigram)
如果一个词的出现仅依赖于它前面出现的一个词,称为二元语言模型

三元语言模型(trigram)
假设一个词的出现仅依赖于它前面出现的两个词,称为三元语言模型

一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。
在实践中用的最多的就是bigram和trigram了,高于四元的用的非常少,由于训练它须要更庞大的语料,并且数据稀疏严重,时间复杂度高,精度却提高的不多。
前言:
机器学习的套路是,对所研究的问题建模,构造一个目标函数,然后优化参数,最后用这个目标函数进行预测。
对于统计语言模型,常使用最大对数似然作为目标函数,即:
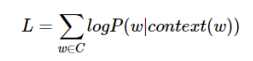
在n-gram模型中,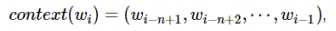
由此可见,概率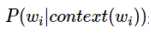 是关于w和context(w)的函数,即
是关于w和context(w)的函数,即
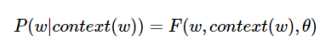
一旦F确定下来了,任何概率都可以使用这个函数进行计算了。
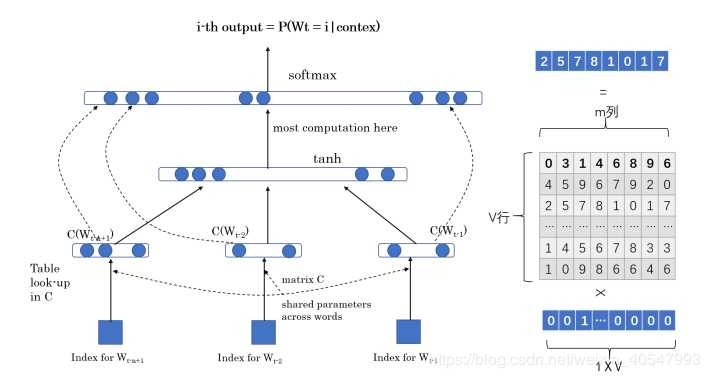
神经网络语言模型(Neural Network Language Model,NNLM)
面介绍的n-gram模型相信我们已经十分清楚了,但是n-gram模型的一个突出的确定就是,n的设置不宜过大,n从2到3提升效果显著,但是从3-4提升的效果就没那么好了。而且随着n的增大,参数的数量是以几何形势增长的。
因此,n-gram模型只能提取某个词前面两到三个词的信息,而不能提取更多的信息了。然而很明显的是,整文本序列中,包含更前面的词能够提供比仅仅2到3个词更多的信息,这也是神经网络语言模型着重要解决的问题之一。
神经网络模型主要在以下两点上寻求更大的进步:1)n-gram模型没有考虑上下文中更多的词提供的信息;2)n-gram模型没有考虑词与词之间的相似性。
比如:如果在一个语料库中,“我爱青岛”出现了6000次,而“我爱大连"只出现了15次,n-gram模型得出的结果是前面一个句子的可能性会比后面一个句子大得多。但是实际上,这两个句子是相似的,他们在真实的情况下出现的概率也应该是相仿的。
神经网络语言模型可以概括为以下三点:1)将词汇表中的每个词表示成一个在m维空间里的实数形式的分布式特征向量;2)使用序列中词语的分布式特征向量来表示连接概率函数;3)同时学习特征向量和概率函数的参数。
特征向量表示词的不同特征:每一个词都是向量空间内的一个点。特征的个数通常都比较小,比如30,60或者100,远远小于词汇表的长度。概率函数是在给定一个词前面的若干词的情况下,该词出现的条件概率。调整概率函数的参数,使得训练集的对数似然达到最大。每个词的特征向量是通过训练得到的,也可以用先验知识进行初始化。
数学理论探讨
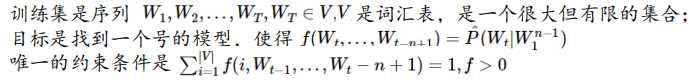


标签:字母 最优 领域 转换 好处 一个个 分词 左右 方法
原文地址:https://www.cnblogs.com/huangm1314/p/11307103.html