标签:transport out 比较 empty ephemeral uid exce 设置 存储
故障前提ElasticSearch 版本:5.2
集群节点数:5
索引主分片数:5
索引分片副本数:1
线上环境ES存储的数据量很大,当天由于存储故障,导致一时间 5个节点的 ES 集群,同时有两个节点离线,一个节点磁盘只读(机房小哥不会处理,无奈只有清空数据重新安装系统),一个节点重启后,ES集群报个别索引分片分配异常,ES索引出于保证数据一致性的考虑,并没有把重启节点上的副本分片提升为主分片,所以该索引处于 不可写入 状态(索引分片 red)。
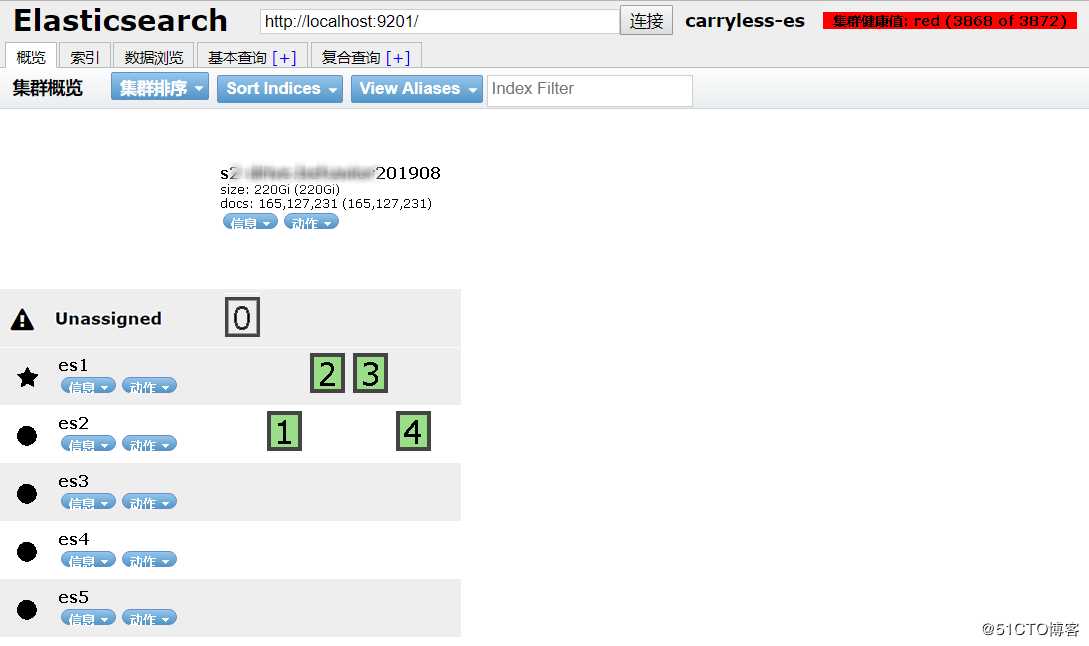
在网上找了找类似的处理方案,分为以下几个。
利用 _reroute API 进行分片路由。
pass: 分片都启不来,按照网上的操作执行失败。
利用 _reindex API 进行现有数据重新复制到新索引,然后把旧索引删除,新索引建立别名为老索引名称。
优点:因为如图分片 0 出于只读状态,所以数据是可以访问的,所以利用_reindex可以把副本分片的数据进行复制迁移到新索引,最大保证数据的安全性。
缺点:因为涉及的数据量比较大,而且_reindex效率很低,220G 的索引数据,大概要3-4天的时间才能写入完毕。线上环境等不了这么久。
也找了许多提升_reindex效率的方法,设置新索引的副本数为 0,禁用刷新 等等。提升效果都很小。
找了下官方文档,找到了如下方法。
[root@***es4 ~]# curl ‘http://localhost:9201/s2*******r201908/_shard_stores?pretty‘
{
"indices" : {
"s2********201908" : {
"shards" : {
"0" : {
"stores" : [
{
"kgEDY2A4TBKK6lFzqsurnQ" : {
"name" : "es3",
"ephemeral_id" : "72HkjNj5S-qyl6gmVkbWeg",
"transport_address" : "10.2.97.130:9300",
"attributes" : { }
},
"allocation_id" : "B4G1nHTgQieomyy-KME1ug",
"allocation" : "unused"
},
{
"d3WYyXhBQvqYbZieXzfCNw" : {
"name" : "es5",
"ephemeral_id" : "deBE6DjyRJ-kXdj0XU7FzQ",
"transport_address" : "10.2.101.116:9300",
"attributes" : { }
},
"allocation_id" : "svMhSywPSROQa7MnbvKB-g",
"allocation" : "unused",
"store_exception" : {
"type" : "corrupt_index_exception",
"reason" : "failed engine (reason: [corrupt file (source: [index])]) (resource=preexisting_corruption)",
"caused_by" : {
"type" : "i_o_exception",
"reason" : "failed engine (reason: [corrupt file (source: [index])])",
"caused_by" : {
"type" : "corrupt_index_exception",
"reason" : "checksum failed (hardware problem?) : expected=24fb23d3 actual=66004bad (resource=BufferedChecksumIndexInput(MMapIndexInput(path=\"/var/lib/elasticsearch/nodes/0/indices/oC_7CtFfS2-pa3OoBDAlDA/0/index/_1fjsf.cfs\") [slice=_1fjsf_Lucene50_0.pos]))"
}
}
}
}
]
}
}
}
}
}利用 _shard_stores 接口,查看故障索引的分片异常原因。
(es5 节点上,我调用接口设置了副本数从1 变为 0,所以该只读索引还保存有原有分片 0 的副本分片节点信息,可忽略)
我们看到该索引的 0 主分片(故障主分片)以前是存在于 es3 节点上的。ES 由于数据安全性保证,在两个节点都有离线的情况下,锁住了 0 主分片的写入,导致索引也出于只读状态。
[root@*******es4 ~]# curl -XPOST ‘http://localhost:9201/_cluster/reroute?master_timeout=5m&pretty‘ -d ‘
{
"commands": [
{
"allocate_stale_primary": {
"index": "s2-********201908",
"shard": 0,
"node": "es3",
"accept_data_loss": true
}
}
]
}‘我们可以手动调用集群的 reroute 接口,在接受部分数据丢失的情况下,我们可以把 es3 节点上的原有副本,强制提升为索引的主分片。
官方文档 说明。
此外,/_cluster/reroute 接口还能够接受手动分配一个空的主分片到已有索引分配之中。谨慎使用
[root@*******es4 ~]# curl -XPOST ‘http://localhost:9201/_cluster/reroute?master_timeout=5m&pretty‘ -d ‘
{
"commands": [
{
"allocate_empty_primary": {
"index": "s2-********201908",
"shard": 0,
"node": "es3",
"accept_data_loss": true
}
}
]
}‘这种更残暴,直接把分片数据清空,强制拉上线。 但是这也不失为一种处理方法。
最终,该索引恢复正常。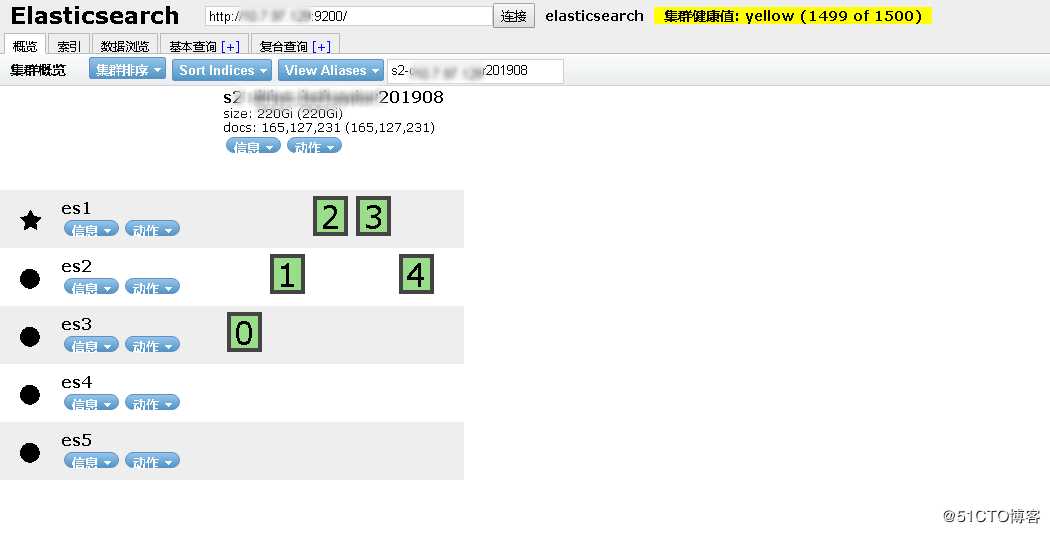
标签:transport out 比较 empty ephemeral uid exce 设置 存储
原文地址:https://blog.51cto.com/professor/2432102