标签:实现 统计 取整 就是 思想 前缀和 其它 默认 合并
分块是一种\(O(N\sqrt{N})\)的维护序列的数据结构,它比树形数据结构好写(方便书写和调试但代码不一定短)、复杂度也很接近(有时能卡过\(O(N\log N)\)的数据)、功能也更强大,常被视为一种“准暴力”的手段。
注意:我们通常将分块看作\(O(N\sqrt{N})\)的数据结构,但这并不准确,下文会分析其复杂度
分块的思想很简单,就是把序列分成一些块,对于每个块打标记,使得对于每个块我们可以在指定复杂度内完成操作。于是我们可以将所有符合要求的整块处理掉(不会太多),再暴力处理不被完全包含的角块(不会太大),从而在有限时间内完成操作。
可以先跳过此模块或者结合下一个模块理解。
就是把序列分成num个整块,每个整块的大小为siz,多余的部分构成一个角块
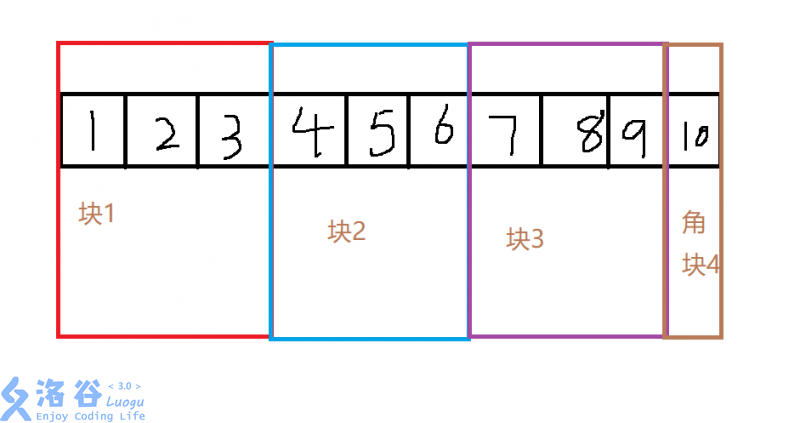
就是最初分出的几个整块,区间中的整块指的就是区间包含的最初分出来的整块
例如最初分出来的\([1,3]\)就是一个整块,而对于区间\([3,8]\),唯一的整块是\([4,6]\),显然,一个区间最多有\(num\)个整块
就是无法构成整块的区间,
例如最初\([10,10]\)就是一个角块,而对于区间\([3,8]\),\([7,8]\)是一个角块,显然,一个区间最多包含\(2\)个角块,尺寸和不大于\(2\times siz\)
我们对序列进行分块,并为每一个块预处理出一个值(尽可能概括块中所需的信息),使得对于每个块我们可以在指定复杂度内完成查询。
对于每次区间操作,我们修改区间包含的所有整块的值,再对于两端的角块进行暴力操作,维护块的性质
对于每次区间查询,我们将每个整块的值合并,再与两端的角块的值合并,得出结果。
通常,我们认为分块的复杂度是\(O(\sqrt{N})\),这在\(O(\text{合并块的成本}+\text{处理角块的成本})=O(\text{处理所有整块的成本})\)时成立,但更准确的式子应该是
\[O(\text{siz}\times\text{处理角块的复杂度}+\text{num}\times\text{处理整块的复杂度})\]
其实我们还应该考虑\(\text{合并结果的成本}\)与\(\text{最初的预处理}\)这两者都是和\(\text{siz}\)与\(\text{num}\)有关的,但此处讨论过于复杂,暂时不管
具体来说,如果我们处理角块的复杂度较大,那么我们希望每个块的尺寸尽量小,如果处理整块的复杂度较大,那么我们希望块的数量尽量小。
观察
\[O(\text{siz}\times\text{处理角块的复杂度}+\text{num}\times\text{处理整块的复杂度})\]
由于\(O(\text{siz}\times\text{num})=O(N)\),我们可以使用均值不等式(即基本不等式)调整两个参数的值。
我们设\(u=\text{处理角块的复杂度},v=\text{处理整块的复杂度}\),则有
\[O=u\times\text{siz}+v\times\text{num}\]
\[O=u\times\text{siz}+v\times\frac{N}{\text{siz}}\]
\[O\geq \sqrt{u\times\text{siz}\times v\times\frac{N}{\text{siz}}}=\sqrt{u\times v\times N}\]
当且仅当\(\text{siz}=\sqrt{\frac{v\times N}{u}}\)时等号成立,复杂度最低
但在实际情况中,\(u,v\)可能不像想象中那么明确,我们常常可以通过调整参数来获得最优解
此模块将列举分块的常见应用,可以直观地感受分块的作用于实现方法
这些操作都是线段树可以进行的(建议先学习线段树相应操作,二者在案例上的思想是一样的)
数列分块就是把数列中每m个元素打包起来,达到优化算法的目的。
以此题为例,如果我们把每m个元素分为一块,共有\(\frac{n}{m}\)块,每次区间加的操作会涉及\(O(\frac{n}{m})\)个整块,以及区间两侧两个不完整的块中至多2m个元素。
我们给每个块设置一个加法标记(就是记录这个块中元素一起加了多少),每次操作对每个整块直接O(1)标记,而不完整的块由于元素比较少,暴力修改元素的值。
每次询问时返回元素的值加上其所在块的加法标记。
这样每次操作的复杂度是\(O(\frac{n}{m})+O(m)\),根据均值不等式,当m取\(\sqrt{n}\)时总复杂度最低,为了方便,我们都默认下文的分块大小为\(\sqrt{n}\)。
?
这题的询问变成了区间上的询问,不完整的块还是暴力;而要想快速统计完整块的答案,需要维护每个块的元素和,先要预处理一下。
考虑区间修改操作,不完整的块直接改,顺便更新块的元素和;完整的块类似之前标记的做法,直接根据块的元素和所加的值计算元素和的增量。
?
很显然,如果只有区间乘法,和分块入门 1 的做法没有本质区别,但要思考如何同时维护两种标记。
我们让乘法标记的优先级高于加法(如果反过来的话,新的加法标记无法处理)
若当前的一个块乘以m1后加上a1,这时进行一个乘m2的操作,则原来的标记变成\(m1*m2,a1*m2\)
若当前的一个块乘以m1后加上a1,这时进行一个加a2的操作,则原来的标记变成m1,a1+a2
?
区间修改没有什么难度,这题难在区间查询比较奇怪,因为权值种类比较多,似乎没有什么好的维护方法。
模拟一些数据可以发现,询问后一整段都会被修改,几次询问后数列可能只剩下几段不同的区间了。
我们思考这样一个暴力,还是分块,维护每个分块是否只有一种权值,区间操作的时候,对于同权值的一个块就O(1)统计答案,否则暴力统计答案,并修改标记,不完整的块也暴力。
?
这样看似最差情况每次都会耗费O(n)的时间,但其实可以这样分析:
假设初始序列都是同一个值,那么查询是\(O(\sqrt{n})\),如果这时进行一个区间操作,它最多破坏首尾2个块的标记,所以只能使后面的询问至多多2个块的暴力时间,所以均摊每次操作复杂度还是\(O(\sqrt{n})\)。
换句话说,要想让一个操作耗费O(n)的时间,要先花费\(\sqrt{n}\)个操作对数列进行修改。
初始序列不同值,经过类似分析后,就可以放心的暴力啦。
?
稍作思考可以发现,开方操作比较棘手,主要是对于整块开方时,必须要知道每一个元素,才能知道他们开方后的和,也就是说,难以快速对一个块信息进行更新。
看来我们要另辟蹊径。不难发现,这题的修改就只有下取整开方,而一个数经过几次开方之后,它的值就会变成 0 或者 1。
如果每次区间开方只不涉及完整的块,意味着不超过2√n个元素,直接暴力即可。
如果涉及了一些完整的块,这些块经过几次操作以后就会都变成 0 / 1,于是我们采取一种分块优化的暴力做法,只要每个整块暴力开方后,记录一下元素是否都变成了 0 / 1,区间修改时跳过那些全为 0 / 1 的块即可。
这样每个元素至多被开方不超过4次,显然复杂度没有问题。
这类操作,往往可以在每一个块内放一个平衡树(或set),可以起到扩展数据结构的作用
?
有了上一题的经验,我们可以发现,数列简单分块问题实际上有三项东西要我们思考:
对于每次区间操作:
1.不完整的块?的\(O(\sqrt{n})\)个元素怎么处理?
2.\(O(\sqrt{n})\)个?整块?怎么处理?
3.要预处理什么信息(复杂度不能超过后面的操作)?
我们先来思考只有询问操作的情况,不完整的块枚举统计即可;而要在每个整块内寻找小于一个值的元素数,于是我们不得不要求块内元素是有序的,这样就能使用二分法对块内查询,需要预处理时每块做一遍排序,复杂度\(O(n\log n)\),每次查询在\(\sqrt{n}\)个块内二分,以及暴力\(2\sqrt{n}\)个元素,总复杂度\(O(n\log n + n\sqrt{n}\log\sqrt{n})\)。
可以通过均值不等式计算出更优的分块大小,就不展开讨论了
那么区间加怎么办呢?
套用第一题的方法,维护一个加法标记,略有区别的地方在于,不完整的块修改后可能会使得该块内数字乱序,所以头尾两个不完整块需要重新排序,复杂度分析略。
在加法标记下的询问操作,块外还是暴力,查询小于(x – 加法标记)的元素个数,块内用(x – 加法标记)作为二分的值即可。
n<=100000其实是为了区分暴力和一些常数较大的写法。
接着第二题的解法,其实只要把块内查询的二分稍作修改即可。
先说随机数据的情况
之前提到过,如果我们块内用数组以外的数据结构,能够支持其它不一样的操作,比如此题每块内可以放一个动态的数组,每次插入时先找到位置所在的块,再暴力插入,把块内的其它元素直接向后移动一位,当然用链表也是可以的。
查询的时候类似,复杂度分析略。
?
但是这样做有个问题,如果数据不随机怎么办?
如果先在一个块有大量单点插入,这个块的大小会大大超过√n,那块内的暴力就没有复杂度保证了。
还需要引入一个操作:重新分块(重构)
每根号n次插入后,重新把数列平均分一下块,重构需要的复杂度为O(n),重构的次数为√n,所以重构的复杂度没有问题,而且保证了每个块的大小相对均衡。当然,也可以当某个块过大时重构,或者只把这个块分成两半。
我们先预处理出两个数组:
p[i][j]表示第i个块到第j个块的区间最小众数,可以\(O(n\sqrt{n})\)计算
s[i][j]表示第1~i个块中数字j出现的次数,也可以\(O(n\sqrt{n})\)计算
然后我们就可以开始操作了,
首先我们需要一个结论
\[\text{区间众数}\in\{\text{整块连成区间的众数}\cup \text{\{角块中的所有数\}}\}\]
理由:显然,如果区间众数不是整块的众数,那么必然是角块中的数使得整块中的某些元素变多了
于是对于一个区间,我们需要考虑的数就只有\(O(\sqrt{n})\)个,用前缀和处理即可
上面的案例都是根据下标分块,其实分块思想不止于此,此题是根据值域分块的经典案例。
我们先预处理出一个数组sum[i][j],表示模i余j的数的和,此处我们只需要预处理小于\(\sqrt{n}\)的模数的贡献,复杂度在\(O(n\sqrt{n})\)
对于每个修改操作,我们需要加上它对于每个小于\(\sqrt{n}\)的模数的贡献(\(O(\sqrt{n})\))
对于每个查询,我们需要分类讨论,如果值小于\(\sqrt{n}\),那么直接\(O(1)\)调用数组,如果大于\(\sqrt{n}\),那么直接暴力统计,复杂度为\(O(\sqrt{n})\)
标签:实现 统计 取整 就是 思想 前缀和 其它 默认 合并
原文地址:https://www.cnblogs.com/guoshaoyang/p/11407679.html