标签:数据包 代表性 unix tick session复制 匹配 带宽 指令 kernel
HaProxy系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
haproxy是一款负载均衡软件,它工作在7层模型上,可以分析数据包中的应用层协议,并按规则进行负载。通常这类7层负载工具也称为反向代理软件,nginx是另一款著名的反向代理软件。
haproxy支持使用splice()系统调用,它可以将数据在两个套接字之间在内核空间直接使用管道进行传递,无需再在kernel buffer-->app buffer-->kernel之间来回复制数据,实现零复制转发(Zero-copy forwarding),还可以实现零复制启动(zero-starting)。haproxy默认对客户端的请求和对服务端的响应数据都开启了splice功能,它自身对数据状态进行判断,决定此数据是否启用splice()进行管道传递,这能极大提高性能。
先说明说明HTTP协议事务模型。
http协议是事务驱动的,意味着每个request产生且仅产生一个response。客户端发送请求时,将建立一个从客户端到服务端的TCP连接,客户端发送的每一个request都经过此连接传送给服务端,然后服务端发出response报文。随后这个TCP连接将关闭,下一个request将重新打开一个tcp连接进行传送。
[conn1][req1]......[resp1][close1][conn2][req2]......[resp2][close2]......
这种模式称为"http close"模式。这种模式下,有多少个http事务就有多少个连接,且每发出一个response就关闭一次tcp连接。这种情况下,客户端不知道response中body的长度。
如果"http close"可以避免"tcp连接随response而关闭",那么它的性能就可以得到一定程度的提升,因为频繁建立和关闭tcp连接消耗的资源和时间是较大的。
那么如何进行提升?在server端发送response时给出content-length的标记,让客户端知道还有多少内容没有接收到,没有接收完则tcp连接不关闭。这种模式称为"keep-alive"。
[conn][req1]...[resp1][req2]...[resp2][close]
另一种提升"http close"的方式是"pipelining"模式。它仍然使用"keep-alive"模式,但是客户端不需要等待收到服务端的response后才发送后续的request。这在请求一个含有大量图片的页面时很有用。这种模式类似于累积报文数量成一批或完成后才一次性发送,能很好的提升性能。
[conn][req1][req2]...[resp1][resp2][close]...
很多http代理不支持pipelining,因为它们无法将response和相应的request在一个http协议中联系起来,而haproxy可以在pipelinign模式下对报文进行重组。
默认haproxy操作在keep-alive模式:对于每一个tcp连接,它处理每一个request和response,并且在发送response后连接两端都处于空闲状态一段时间,如果该连接的客户端发起新的request,则继续使用此连接。
haproxy支持5种连接模式:
keep alive:分析并处理所有的request和response(默认),后端为静态或缓存服务器建议使用此模式。tunnel:仅分析处理第一个request和response,剩余所有内容不进行任何分析直接转发。1.5版本之前此为默认,现在不建议设置为此模式。passive close:在请求和响应首部加上"connection:close"标记的tunnel,在处理完第一个request和response后尝试关闭两端连接。server close:处理完第一个response后关闭和server端的连接,但和客户端的连接仍然保持,后端为动态应用程序服务器组建议使用此模式。forced close:传输完一个response后客户端和服务端都关闭连接。任何一个反向代理软件,都必须具备这个基本的功能。这主要针对后端是应用服务器的情况,如果后端是静态服务器或缓存服务器,无需实现会话保持,因为它们是"无状态"的。
如果反向代理的后端提供的是"有状态"的服务或协议时,必须保证请求过一次的客户端能被引导到同义服务端上。只有这样,服务端才能知道这个客户端是它曾经处理过的,能查到并获取到和该客户端对应的上下文环境(session上下文),有了这个session环境才能继续为该客户端提供后续的服务。
如果不太理解,简单举个例子。客户端A向服务端B请求将C商品加入它的账户购物车,加入成功后,服务端B会在某个缓存中记录下客户端A和它的商品C,这个缓存的内容就是session上下文环境。而识别客户端的方式一般是设置session ID(如PHPSESSID、JSESSIONID),并将其作为cookie的内容交给客户端。客户端A再次请求的时候(比如将购物车中的商品下订单)只要携带这个cookie,服务端B就可以从中获取到session ID并找到属于客户端A的缓存内容,也就可以继续执行下订单部分的代码。
假如这时使用负载均衡软件对客户端的请求进行负载,如果这个负载软件只是简单地进行负载转发,就无法保证将客户端A引导到服务端B,可能会引导到服务端X、服务端Y,但是X、Y上并没有缓存和客户端A对应的session内容,当然也无法为客户端A下订单。
因此,反向代理软件必须具备将客户端和服务端"绑定"的功能,也就是所谓的提供会话保持,让客户端A后续的请求一定转发到服务端B上。
作为负载均衡软件,一般都会提供一种称为"源地址hash"的调度算法,将客户端的IP地址结合后端服务器数量和权重做散列计算,每次客户端请求时都会进行同样的hash计算,这样同一客户端总能得到相同的hash值,也就能调度到同一个服务端上。
一般来说,除非无路可选,都不应该选择类似源地址hash这样的算法。因为只要后端服务器的权重发生任何一点改变,所有源IP地址的hash值几乎都会改变,这是非常大的动荡。
作为反向代理软件,一般还提供一种cookie绑定的功能实现会话保持。反向代理软件为客户端A单独生成一个cookie1,或者直接修改应用服务器为客户端设置的cookie2,最后将cookie通过在响应报文中设置"Set-Cookie"字段响应给客户端。与此同时,反向代理软件会在内存中维持一张cookie表,这张表记录了cookie1或修改后的cookie2对应的服务端。只要客户端请求报文中的"Cookie"字段中携带了cookie1或cookie2属性的请求到达反向代理软件时,反向代理软件根据cookie表就能检索到对应的服务端是谁。
需要注意的是,客户端收到的cookie可能来源有两类:一类是反向代理软件增加的,这时客户端收到的响应报文中将至少有两个"Set-Cookie"字段,其中一个是反代软件的,其他是应用服务器设置的;一类是反向代理软件在应用服务器设置的Cookie基础上修改或增加属性。
例如,当配置haproxy插入cookie时,客户端从第一次请求到第二次请求被后端应用程序处理的过程大致如下图所示:
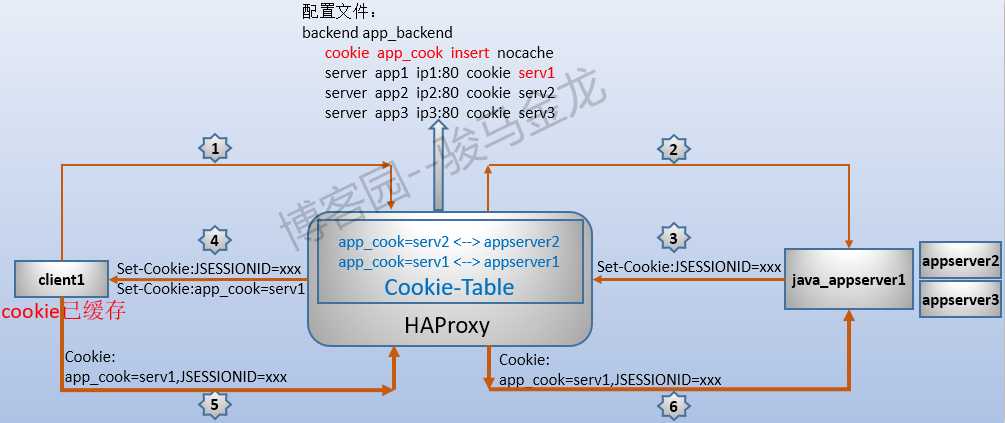
haproxy还提供另一种stick table功能实现会话粘性(stickiness)。这张stick-table表非常强大,它可以根据抽取客户端请求报文中的内容或者源IP地址或者抽取响应报文中的内容(例如应用服务器设置的Session ID这个cookie)作为这张表的key,将后端服务器的标识符ID作为key对应的value。只要客户端再次请求,haproxy就能对请求进行匹配(match),无论是源IP还是cookie亦或是其它字符串作为key,总能匹配到对应的记录,而且匹配速度极快,再根据value转发给对应的后端服务器。
例如,下图是一张最简单的stick table示意图:
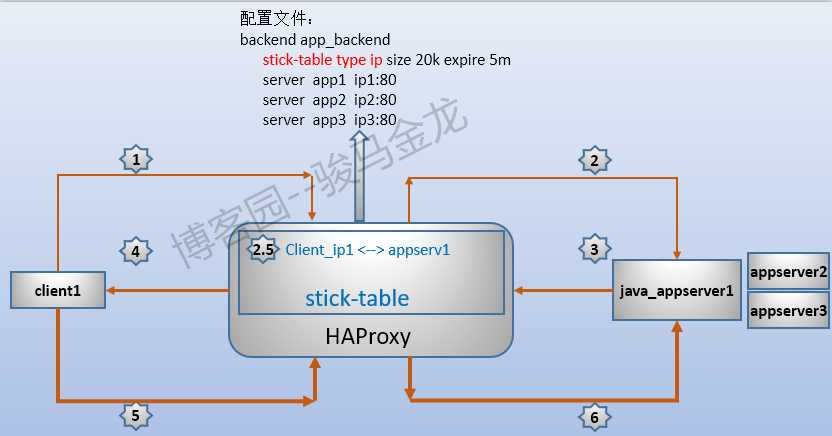
该stick-table存储的key是客户端的源IP地址,当客户端第一次请求到达haproxy后,haproxy根据调度算法为其分配一个后端appserver1,当请求转发到达后端后,haproxy立即在stick table表中建立一条ip1和appserver1的粘性(stickiness)记录。之后,无论是否使用cookie,haproxy都能为该客户端找到它对应的后端服务器。
stick table的强大远不止会话粘性。还可以根据需要定制要记录的计数器和速率统计器,例如在一个时间段内总共流入了多少个连接、平均每秒流入多少个连接、流入流出的字节数和平均速率、建立会话的数量和平均速率等。
更强大的是,stick table可以在"主主模型"下进行stick记录复制(replication),它不像session复制(copy),节点一多,无论是节点还是网络带宽的压力都会暴增。haproxy每次推送的是stick table中的一条记录,而不是整表整表地复制,而且每条记录占用的空间很小(最小时每条记录50字节),使得即使在非常繁忙的情况下,在几十台haproxy节点之间复制都不会占用太多网络带宽。借助stick table的复制,可以完完整整地实现haproxy"主主模型",保证所有粘性信息都不会丢失,从而保证haproxy节点down掉也不会让客户端和对应的服务端失去联系。
无论反向代理软件实现的会话保持能力有多强,功能有多多,只要后端是应用服务器,就一定是"有状态"的。有状态对于某些业务逻辑来说是必不可少的,但对架构的伸缩和高可用带来了不便。我们无法在架构中随意添加新的代理节点,甚至无法随意添加新的应用服务器,高可用的时候还必须考虑状态或者某些缓存内容是否会丢失。
如果将所有应用服务器的session信息全部存储到一台服务器上(一般放在redis或数据库中)进行共享,每台应用服务器在需要获取上下文的时候从这台服务器上取,那么应用服务器在取session消息之前就是"无状态"的。
例如,下面是一个后端使用session共享的示意图:
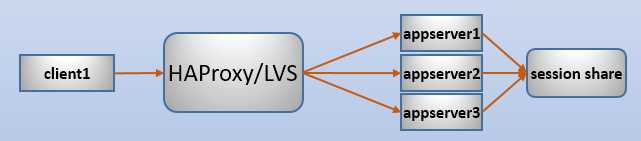
使用session share后,调度器无论将请求调度到哪个后端上,这个后端都能从session share服务器上获取到对应的session上下文。这样无状态的请求完全可以被任意负载,负载软件无需记住后端服务器,从而达到四层负载的效果。如果没有特殊需求(如处理7层协议),这时可以使用LVS替代haproxy,因为在负载性能上,LVS比haproxy高好几个级别。
session共享给架构带来的好处非常多,正如上面所说的,可以使用LVS进行极其高效的负载(前提是没有LVS无法实现的需求),无论是负载节点还是应用服务器节点都可以随意增删服务器。而唯一需要保证的就是session共享服务器的高可用。
任何一个负载均衡软件,都应该提供后端服务器健康状况检查的功能,即使自身没有,也必须能够借助其他第三方工具来实现。只有具备后端健康检查的功能,在后端某服务器down掉的时候,调度器才能将它从后端服务器组中踢出去,保证客户端的请求不会被调度到这台down掉的服务器上。
haproxy为多种协议类型提供了健康状况检查的功能,除了最基本的基于tcp的检查,据我从官方手册上根据关键词的统计,还为以下几种协议提供健康检查:
如果haproxy没有指定基于哪种协议进行检查,默认会使用tcp协议进行检查,这种检查的健康判断方式就是能否连上后端。例如:
1
2
3
backend static_group
server staticsrv1 192.168.100.62:80 check rise 1
server staticsrv2 192.168.100.63:80 check rise 1
在server指令中的check设置的是是否开启健康检查功能,以及检查的时间间隔、判断多少次不健康后就认为后端下线了以及成功多少次后认为后端重新上线了。
如果要基于其它协议检查,需要使用协议对应的option指令显式指定要检查的对象。且前提是server中必须指定check,这是控制检查与否的开关。例如,基于http协议检查:
1
2
3
4
backend dynamic_group
option httpchk GET /index.php
server appsrv1 192.168.100.60:80 check
server appsrv2 192.168.100.61:80 check
对于基于http协议的检查,haproxy提供了多种判断健康与否的方式,可以通过返回状态码或拿状态码来进行正则匹配、通过判断响应体是否包含某个字符串或者对响应体进行正则匹配。
例如:
1
2
3
4
5
6
7
8
9
10
backend dynamic_group1
option httpchk GET /index.php
http-check expect status 200
server appsrv1 192.168.100.60:80 check
server appsrv2 192.168.100.61:80 check
backend dynamic_group2
option httpchk GET /index.php
http-check expect ! string error
server appsrv1 192.168.100.60:80 check
server appsrv2 192.168.100.61:80 check
上面两个后端组都指定了使用http协议进行检查,并分别使用http-check expect指定了要检查到状态码200、响应体中不包含字符串"error"才认为健康。如果不指定http-check expect指令,那么基于http协议检查的时候,只要状态码为2xx或3xx都认为是健康的。
haproxy除了具备检查后端的能力,还支持被检查,只需要使用monitor类的指令即可。所谓被检查,指的是haproxy可以指定一个检查自己的指标,自己获取检查结果,并将检查状态上报给它的前端或高可用软件,让它们很容易根据上报的结果(200或503状态码)判断haproxy是否健在。
以下是两个被检查的示例:
1
2
3
4
5
6
7
8
9
10
frontend www
mode http
monitor-uri /haproxy_test
frontend www
mode http
acl site_dead nbsrv(dynamic) lt 2
acl site_dead nbsrv(static) lt 2
monitor-uri /site_alive
monitor fail if site_dead
第一个示例中,"/haproxy_test"是它的前端指定要检查的路径,此处haproxy对该uri路径进行监控,当该路径正常时,haproxy会告诉前段"HTTP/1.0 200 OK",当不正常时,将"HTTP/1.0 503 Service unavailable"。
第二个示例中,不仅监控了"/site_alive",还监控了后端健康节点的数量。当dynamic或static后端组的健康节点数量少于2时,haproxy立即主动告诉前端"HTTP/1.0 503 Service unavailable",否则返回给前端"HTTP/1.0 200 OK"。
一个合格的反向代理软件,必须能够处理流入的请求报文和流出的响应报文。具备这些能力后,不仅可以按照需求改造报文,还能筛选报文,防止被恶意攻击。
haproxy提供了很多处理请求、响应报文的功能性指令,还有一些所谓"函数"。
大多数处理请求报文的函数都以"req"或"capture.req."开头,处理响应报文的函数都以"res."或"capture.res."开头,这样的函数非常多,几乎可以实现任何想达到的功能。完整的指令集见官方手册:https://cbonte.github.io/haproxy-dconv/1.7/configuration.html#7.3.2。
以下是几个比较具有代表性的函数或指令:
1
2
3
4
5
6
7
capture request header:捕获请求报文。
capture response header:捕获响应报文。
reqadd:在请求首部添加字段。
rspadd:在响应首部添加字段。
req.cook(name):获取Cookie字段中的name属性的值。
res.cook(name):获取"Set-Cookie"字段中name属性的值。
。。。。。。
以上函数都是对7层协议进行处理。除此之外,haproxy还有非常多的函数可以分别处理4层、5层、6层协议。
作为反向代理,必须具备查看自身和后端服务器的状态信息。
haproxy提供了多种获取状态信息的方法:
stats enable指令启用状态报告功能,这样就可以在浏览器中输入特定的url访问状态信息。stat socket指令是干吗用的,其实这就是为系统管理员提供的接口。
1
2
3
4
5
6
7
8
9
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 2000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
我们安装"socat"包(socket cat,在epel源提供该包)后,就可以通过socat命令来查看/var/lib/haproxy/stats这个状态套接字。例如,执行下面的命令可以获取到所有可执行的命令。
echo "help" | socat unix:/var/lib/haproxy/stats -
例如,其中一条命令是"show backend"用来列出所有的backend,可以这样使用:
echo "show backend" | socat unix:/var/lib/haproxy/stats -
或者也可以进入交互式操作模式:
socat readline unix:/var/lib/haproxy/stats
可以说,支持ACL的软件都是好软件,比如haproxy、varnish。
ACL本意是access control list(访问控制列表),用来定义一组黑名单或白名单。但显然,它绝不仅仅是为了黑白名单而存在的,有了ACL,可以随意按条件定制一组或多组列表。ACL存在的意义,就像是正则表达式存在的意义一样,极大程度上简化了软件在管理上的复杂度。
在haproxy中,只要能在逻辑意义上进行分组的,几乎都可以使用ACL来定制。比如哪些IP属于A组,后端哪些节点是静态组,后端节点少于几个时属于dead状态等等。
haproxy支持后端连接重用的功能。
在默认情况下(不使用连接重用),当某客户端的请求到来后,haproxy为了将请求转发给后端,会和后端某服务器建立一个TCP连接,并将请求调度到该服务器上,该客户端后续的请求也会通过该TCP连接转发给后端(假设没有采用关闭后端连接的http事务模型)。但在响应后和该客户端的下一个请求到来前,这个连接是空闲的。
其实仔细想想,和后端建立的TCP连接仅仅只是为了调度转发,免去后续再次建立tcp连接的消耗。完全可以为其它客户端的请求调度也使用这个TCP连接,保证TCP连接资源不浪费。可以使用http-reuse strategy_name指令设置连接重用的策略,而默认策略禁用连接重用。
该指令有4个值:
never:这是默认设置。表示禁用连接重用,因为老版本的haproxy认为来源不同的请求不应该共享同一个后端连接。safe:这是建议使用的策略。"安全"策略下,haproxy为客户端的每个第一个请求都单独建立一个和后端的TCP连接,但是后续的请求则会重用和该后端的空闲TCP连接。这样的转发不仅提高了资源使用率,还保持了keep-alive的功能。因此,safe策略配合http-keep-alive事务模式比http-server-close事务模式更高效,无论后端是静态、缓存还是动态应用服务器。aggressive:一种激进的策略,该策略的haproxy会重用空闲TCP连接来转发大多数客户端的第一次请求。之所以是大多数而不是所有,是因为haproxy会挑选那些已经被重用过至少一次的连接(即从建立开始转发过至少两次,不管源是否是同一客户端)进行重用,因为haproxy认为只有这样的连接才具有重用能力。always:它将总是为第一个请求重用空闲连接。当后端是缓存服务器时,这种策略比safe策略的性能要高许多,因为这样的请求行为都是一样的,且可以共享同一连接来获取资源。不过不建议使用这种策略,因为大多数情况下,它和aggressive的性能是一样的,但是却带来了很多风险。因此,为了性能的提升,将它设置为safe或aggressive吧,同时再将http事务模型设置为http-keep-alive,以免后端连接在响应后立即被关闭。
标签:数据包 代表性 unix tick session复制 匹配 带宽 指令 kernel
原文地址:https://www.cnblogs.com/jiftle/p/11416606.html