标签:response tin 日志信息 libs 爬取 https for nes tail
目录
@(Scrapy框架的安装和基本用法)
什么是Scrapy?
???????Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经继承了各种功能(高性能异步下载、队列、分布式、解析、持久化等)的具有很强通用性的项目模板。对于框架的研究,重点在于研究其框架的特性、各个功能的用法即可。
开始安装
如果是Windows系统,应按照下面的顺序进行安装:
- pip3 install wheel
- 打开网址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
复制搜索:Twisted?18.9.0?cp36?cp36m?win_amd64.whl ,然后下载它
进入下载目录,执行: pip3 install Twisted-18.9.0-cp36-cp36m-win_amd64.whl- pip3 install pywin32
- pip3 install scrapy
构建你的项目
第一步,打开终端,执行
scrapy startproject 项目名称来构建一个项目(项目生成在当前目录下),项目的目录结构如下:project_name/ # 是你定义的项目名称 project_name/ # 是你定义的项目名称 spiders/ # 用于爬虫文件 __init\_.py __init__.py items.py # 数据结构模板文件 middlewares.py # 中间件 pipelines.py # 管道文件 settings.py # 配置文件(真正配置爬虫的文件) scrapy.cfg # 也是配置文件
第二步,进入上一步骤创建的项目目录(终端),执行
scrapy genspider 应用名称 爬取网页的起始URL来创建一个爬虫应用程序,创建的爬虫应用程序生成在spiders/目录下:# -*- coding: utf-8 -*- import scrapy class Test01Spider(scrapy.Spider): # 应用名称 name = 'test01' # 指定爬取的域名(如果你写了此属性,则非此域名的URL无法爬取) # allowed_domains = ['www.baidu.com'] # 起始爬取的URL start_urls = ['https://www.baidu.com/'] # 起始爬取的URL有多条时,则会将每条URL的响应数据(response)都调用一遍下面的parse函数 def parse(self, response): """ 访问起始URL并获取结果后的回调函数 :param response: 向起始的RUL发送请求后,获取的响应对象 :return: 该方法的返回值必须为 可迭代对象 或 None """ pass
第三步,打开settings.py文件,修改必要配置:
# 第19行,伪装请求载体身份(UA) USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # 第22行,是否遵守robots协议 ROBOTSTXT_OBEY = True
第四步,执行爬虫程序,执行方式有如下两种:
scrapy crawl 应用名称这种执行形式会显示执行的日志信息scrapy crawl 应用名称 --nolog不显示执行的日志
简单使用
爬取你的CSDN博客中所有文章和URL的对应关系
爬虫应用文件内容如下:# -*- coding: utf-8 -*- import scrapy class Test01Spider(scrapy.Spider): name = 'test01' # 应用名称 # 允许爬取的域名(如果你指定了此属性,则非此域名的URL无法爬取) allowed_domains = ['https://blog.csdn.net'] path = '/qq_41964425' # 你的CSDN博客主页路径 max_page = 7 # 你的CSDN博客中一共有多少页博客 # 将你的CSDN博客的每一页 都添加到起始爬取的URL中 start_urls = [] for i in range(1, max_page + 1): start_urls.append(allowed_domains[0] + path + '/article/list/' + str(i)) def parse(self, response): """ 访问起始URL并获取结果后的回调函数 :param response: 向起始的RUL发送请求后,获取的响应对象 :return: 该方法的返回值必须为 可迭代对象 或 None """ # 定位你的每篇博文的div div_list = response.xpath('//div[@class="article-item-box csdn-tracking-statistics"]') # type:list # xpath为response中的方法,可以将xpath表达式直接作用于该函数中 # 每个人的博客,每一页都有这篇文章,你打开源码看看就知道了 div_list.pop(0) # 帝都的凛冬 https://blog.csdn.net/yoyo_liyy/article/details/82762601 # 开始处理解析到的数据 content_list = [] for div in div_list: # xpath函数返回的为列表,列表中存放的数据为Selector类型的数据 # xpath解析到的内容被封装到了Selector对象中,需要调用extract()函数将解析到的内容从Selector中取出 title = div.xpath('.//h4/a/text()')[-1].extract().strip() # 获取博文标题 url = div.xpath('.//h4/a/@href').extract_first().strip() # 获取博文URL # extract():解析指定的元素,也可以解析列表中的所有元素 extract_first():取出列表中的第一个元素并进行操作 # 保存内容(注意格式) content_list.append({'title': title, 'url': url}) return content_list
跑起来:
运行此命令scrapy crawl test01 --nolog -o text.csv将进行持久化存储,-o 指定保存的文件(注意文件的格式,建议使用 .csv)
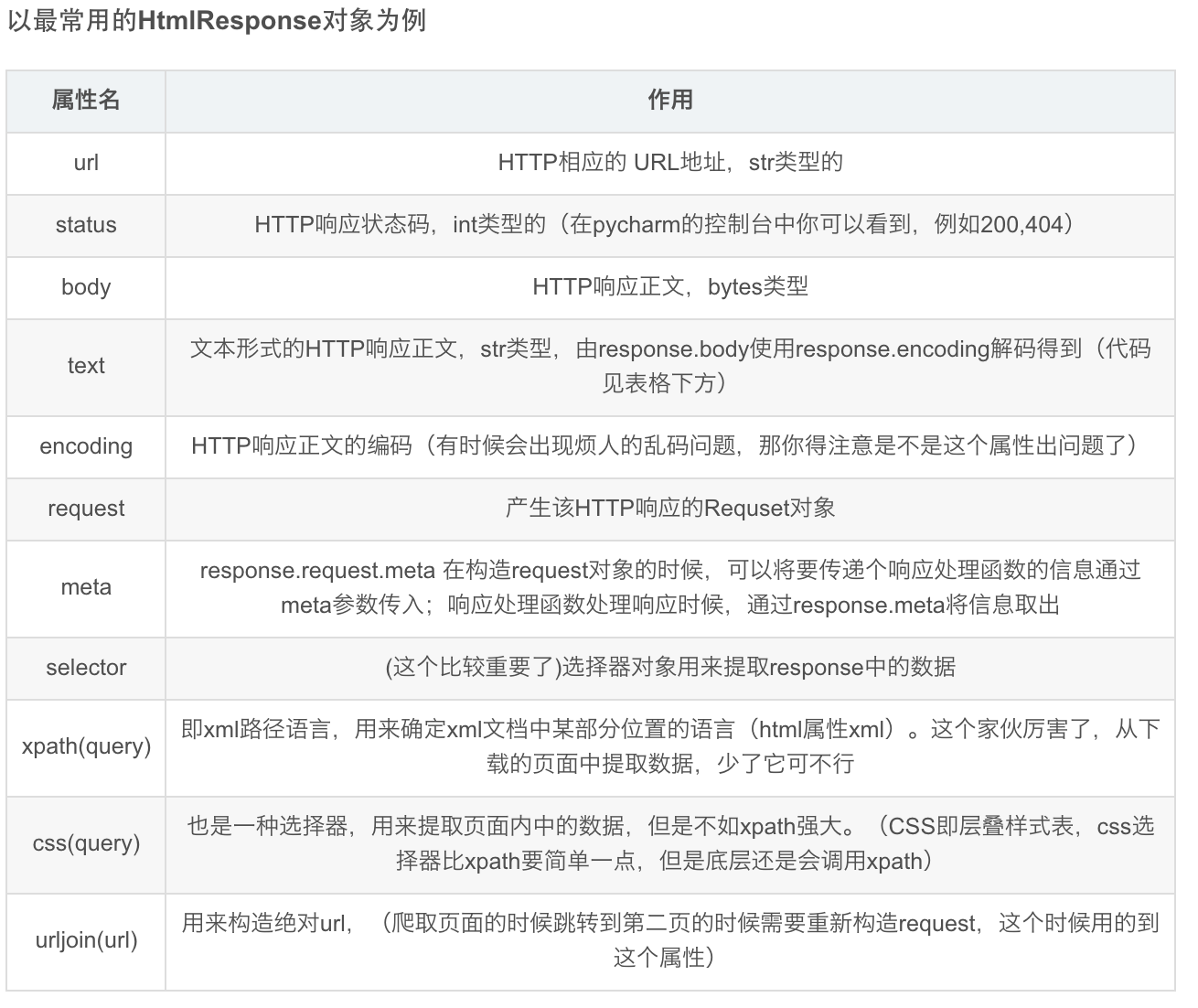
补充:Response对象的方法
标签:response tin 日志信息 libs 爬取 https for nes tail
原文地址:https://www.cnblogs.com/ggg566/p/11417457.html