标签:get put sign 取数据 dom self scope for 使用
课程地址:https://cloud.tencent.com/developer/labs/lab/10295/console

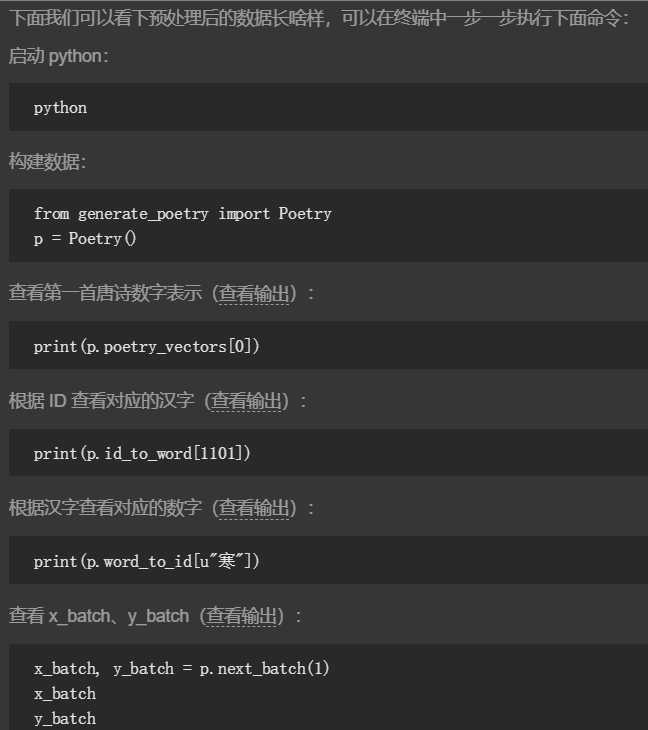
1.获取训练数据
wget 命令获取:wget http://tensorflow-1253675457.cosgz.myqcloud.com/poetry/poetry
2.数据预处理
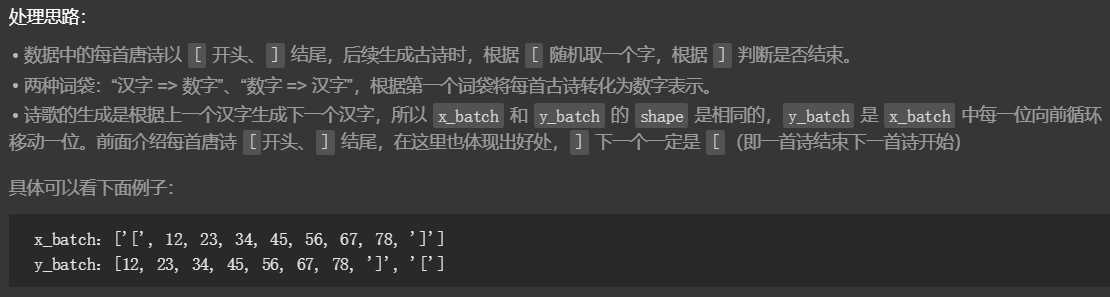

#-*- coding:utf-8 -*- import numpy as np from io import open import sys import collections reload(sys) sys.setdefaultencoding(‘utf8‘) class Poetry: def __init__(self): self.filename = "poetry" self.poetrys = self.get_poetrys() self.poetry_vectors,self.word_to_id,self.id_to_word = self.gen_poetry_vectors() self.poetry_vectors_size = len(self.poetry_vectors) self._index_in_epoch = 0 def get_poetrys(self): poetrys = list() f = open(self.filename,"r", encoding=‘utf-8‘) for line in f.readlines(): _,content = line.strip(‘\n‘).strip().split(‘:‘) content = content.replace(‘ ‘,‘‘) #过滤含有特殊符号的唐诗 if(not content or ‘_‘ in content or ‘(‘ in content or ‘(‘ in content or "□" in content or ‘《‘ in content or ‘[‘ in content or ‘:‘ in content or ‘:‘in content): continue #过滤较长或较短的唐诗 if len(content) < 5 or len(content) > 79: continue content_list = content.replace(‘,‘, ‘|‘).replace(‘。‘, ‘|‘).split(‘|‘) flag = True #过滤即非五言也非七验的唐诗 for sentence in content_list: slen = len(sentence) if 0 == slen: continue if 5 != slen and 7 != slen: flag = False break if flag: #每首古诗以‘[‘开头、‘]‘结尾 poetrys.append(‘[‘ + content + ‘]‘) return poetrys def gen_poetry_vectors(self): words = sorted(set(‘‘.join(self.poetrys) + ‘ ‘)) #数字ID到每个字的映射 id_to_word = {i: word for i, word in enumerate(words)} #每个字到数字ID的映射 word_to_id = {v: k for k, v in id_to_word.items()} to_id = lambda word: word_to_id.get(word) #唐诗向量化 poetry_vectors = [list(map(to_id, poetry)) for poetry in self.poetrys] return poetry_vectors,word_to_id,id_to_word def next_batch(self,batch_size): assert batch_size < self.poetry_vectors_size start = self._index_in_epoch self._index_in_epoch += batch_size #取完一轮数据,打乱唐诗集合,重新取数据 if self._index_in_epoch > self.poetry_vectors_size: np.random.shuffle(self.poetry_vectors) start = 0 self._index_in_epoch = batch_size end = self._index_in_epoch batches = self.poetry_vectors[start:end] x_batch = np.full((batch_size, max(map(len, batches))), self.word_to_id[‘ ‘], np.int32) for row in range(batch_size): x_batch[row,:len(batches[row])] = batches[row] y_batch = np.copy(x_batch) y_batch[:,:-1] = x_batch[:,1:] y_batch[:,-1] = x_batch[:, 0] return x_batch,y_batch
3.LSTM 模型
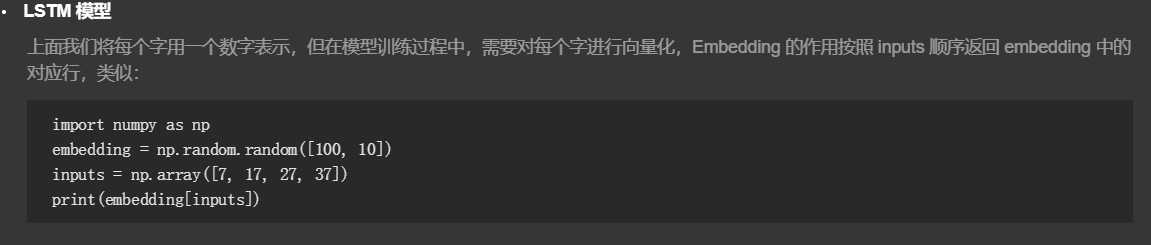
#-*- coding:utf-8 -*- import tensorflow as tf class poetryModel: #定义权重和偏置项 def rnn_variable(self,rnn_size,words_size): with tf.variable_scope(‘variable‘): w = tf.get_variable("w", [rnn_size, words_size]) b = tf.get_variable("b", [words_size]) return w,b #损失函数 def loss_model(self,words_size,targets,logits): targets = tf.reshape(targets,[-1]) loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets], [tf.ones_like(targets, dtype=tf.float32)],words_size) loss = tf.reduce_mean(loss) return loss #优化算子 def optimizer_model(self,loss,learning_rate): tvars = tf.trainable_variables() grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), 5) train_op = tf.train.AdamOptimizer(learning_rate) optimizer = train_op.apply_gradients(zip(grads, tvars)) return optimizer #每个字向量化 def embedding_variable(self,inputs,rnn_size,words_size): with tf.variable_scope(‘embedding‘): with tf.device("/cpu:0"): embedding = tf.get_variable(‘embedding‘, [words_size, rnn_size]) input_data = tf.nn.embedding_lookup(embedding,inputs) return input_data #构建LSTM模型 def create_model(self,inputs,batch_size,rnn_size,words_size,num_layers,is_training,keep_prob): lstm = tf.contrib.rnn.BasicLSTMCell(num_units=rnn_size,state_is_tuple=True) input_data = self.embedding_variable(inputs,rnn_size,words_size) if is_training: lstm = tf.nn.rnn_cell.DropoutWrapper(lstm, output_keep_prob=keep_prob) input_data = tf.nn.dropout(input_data,keep_prob) cell = tf.contrib.rnn.MultiRNNCell([lstm] * num_layers,state_is_tuple=True) initial_state = cell.zero_state(batch_size, tf.float32) outputs,last_state = tf.nn.dynamic_rnn(cell,input_data,initial_state=initial_state) outputs = tf.reshape(outputs,[-1, rnn_size]) w,b = self.rnn_variable(rnn_size,words_size) logits = tf.matmul(outputs,w) + b probs = tf.nn.softmax(logits) return logits,probs,initial_state,last_state
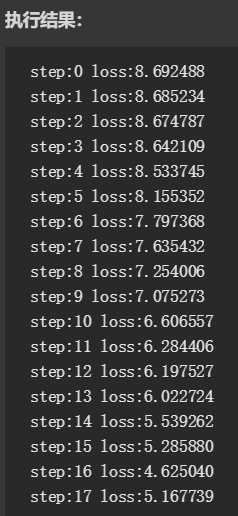
4.训练 LSTM 模型
每批次采用 50 首唐诗训练,训练 40000 次后,损失函数基本保持不变,GPU 大概需要 2 个小时左右。当然你可以调整循环次数,节省训练时间,亦或者直接下载我们训练好的模型。
wget http://tensorflow-1253675457.cosgz.myqcloud.com/poetry/poetry_model.zip unzip poetry_model.zip
#-*- coding:utf-8 -*- from generate_poetry import Poetry from poetry_model import poetryModel import tensorflow as tf import numpy as np if __name__ == ‘__main__‘: batch_size = 50 epoch = 20 rnn_size = 128 num_layers = 2 poetrys = Poetry() words_size = len(poetrys.word_to_id) inputs = tf.placeholder(tf.int32, [batch_size, None]) targets = tf.placeholder(tf.int32, [batch_size, None]) keep_prob = tf.placeholder(tf.float32, name=‘keep_prob‘) model = poetryModel() logits,probs,initial_state,last_state = model.create_model(inputs,batch_size, rnn_size,words_size,num_layers,True,keep_prob) loss = model.loss_model(words_size,targets,logits) learning_rate = tf.Variable(0.0, trainable=False) optimizer = model.optimizer_model(loss,learning_rate) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) sess.run(tf.assign(learning_rate, 0.002 * 0.97 )) next_state = sess.run(initial_state) step = 0 while True: x_batch,y_batch = poetrys.next_batch(batch_size) feed = {inputs:x_batch,targets:y_batch,initial_state:next_state,keep_prob:0.5} train_loss, _ ,next_state = sess.run([loss,optimizer,last_state], feed_dict=feed) print("step:%d loss:%f" % (step,train_loss)) if step > 40000: break if step%1000 == 0: n = step/1000 sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** n))) step += 1 saver.save(sess,"poetry_model.ckpt")
根据 [ 随机取一个汉字,作为生成古诗的第一个字,遇到 ] 结束生成古诗。
#-*- coding:utf-8 -*- from generate_poetry import Poetry from poetry_model import poetryModel from operator import itemgetter import tensorflow as tf import numpy as np import random if __name__ == ‘__main__‘: batch_size = 1 rnn_size = 128 num_layers = 2 poetrys = Poetry() words_size = len(poetrys.word_to_id) def to_word(prob): prob = prob[0] indexs, _ = zip(*sorted(enumerate(prob), key=itemgetter(1))) rand_num = int(np.random.rand(1)*10); index_sum = len(indexs) max_rate = prob[indexs[(index_sum-1)]] if max_rate > 0.9 : sample = indexs[(index_sum-1)] else: sample = indexs[(index_sum-1-rand_num)] return poetrys.id_to_word[sample] inputs = tf.placeholder(tf.int32, [batch_size, None]) keep_prob = tf.placeholder(tf.float32, name=‘keep_prob‘) model = poetryModel() logits,probs,initial_state,last_state = model.create_model(inputs,batch_size, rnn_size,words_size,num_layers,False,keep_prob) saver = tf.train.Saver() with tf.Session() as sess: sess.run(tf.global_variables_initializer()) saver.restore(sess,"poetry_model.ckpt") next_state = sess.run(initial_state) x = np.zeros((1, 1)) x[0,0] = poetrys.word_to_id[‘[‘] feed = {inputs: x, initial_state: next_state, keep_prob: 1} predict, next_state = sess.run([probs, last_state], feed_dict=feed) word = to_word(predict) poem = ‘‘ while word != ‘]‘: poem += word x = np.zeros((1, 1)) x[0, 0] = poetrys.word_to_id[word] feed = {inputs: x, initial_state: next_state, keep_prob: 1} predict, next_state = sess.run([probs, last_state], feed_dict=feed) word = to_word(predict) print poem

参考博客:
1.
标签:get put sign 取数据 dom self scope for 使用
原文地址:https://www.cnblogs.com/exciting/p/11419184.html
