标签:文件合并 scan 观察 操作 记录 集合 活着 服务器 结构
Client
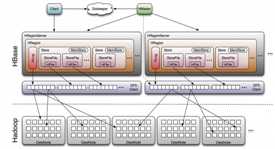
1 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
Zookeeper
1 保证任何时候,集群中只有一个master
2 存贮所有Region的寻址入口
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master职责
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 HDFS上的垃圾文件回收
5 处理schema更新请求
Region Server职责
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
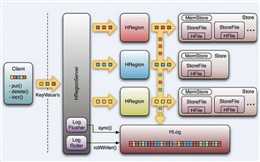
1 Table中的所有行都按照row key的字典序排列;
2 Table 在行的方向上分割为多个Hregion;
3 region按大小分割的(默认10G),每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion;
4 Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的;
5 HRegion虽然是负载均衡的最小单元,但并不是物理存储的最小单元。
事实上,HRegion由一个或者多个Store组成,每个store保存一个column family。每个Strore又由一个memStore和0至多个StoreFile组成。
StoreFile以HFile格式保存在HDFS上。
一个region由多个store组成,每个store包含一个列族的所有数据Store包括位于内存的memstore和位于硬盘的storefile;
客户端检索数据时,先在memstore找,找不到再找storefile。
每个Region Server维护一个Hlog,而不是每个Region一个。这样不同region(来自不同table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。
如果一台region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其它region server上进行恢复。HLog文件就是一个普通的Hadoop Sequence File。
1、HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。
2、接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。
3、Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
4、最后HRegionServer把查询到的数据响应给Client。
1、Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
2、Client向该HRegionServer服务器发起写入数据请求,然后HRegionServer收到请求并响应。
3、Client先把数据写入到HLog,以防止数据丢失,然后将数据写入到Memstore。
4、如果HLog和Memstore均写入成功,则这条数据写入成功,如果Memstore达到阈值,会把Memstore中的数据flush到Storefile中。当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为二。
1、数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并 且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时,系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了。
2、当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint之后的数据。
3、StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(minor_compact, major_compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行split,等分为两个StoreFile。
4、由于对表的更新是不断追加的,compact时,需要访问Store中全部的 StoreFile和MemStore,将他们按row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,合并的过程还是比较快。
任何时刻,一个region只能分配给一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
master使用zookeeper来跟踪region server状态。
当某个region server启动时,会首先在zookeeper上的server目录下建立代表自己的znode。由于master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知。因此一旦region server上线,master能马上得到消息。
当region server下线时,它和zookeeper的会话断开,zookeeper而自动释放代表这台server的文件上的独占锁。master就可以确定,master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的同志。
1、 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为master。
2 、扫描zookeeper上的server父节点,获得当前可用的region server列表。
3 、和每个region server通信,获得当前已分配的region和region server的对应关系。
4、 扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表。
1、由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region 上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。因此master下线短时间内对整个hbase集群没有影响。
1、(hbase.regionserver.global.memstore.size)默认;堆大小的40%regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作;
2、(hbase.hregion.memstore.flush.size)默认:128M,单个region里memstore的缓存大小,超过那么整个HRegion就会flush;
3、(hbase.regionserver.optionalcacheflushinterval)默认:1h,内存中的文件在自动刷新之前能够存活的最长时间
把小的storeFile文件合并成大的Storefile文件,清理过期的数据,包括删除的数据,将数据的版本号保存为3个。
当Region达到阈值,会把过大的Region一分为二,默认一个HFile达到10Gb的时候就会进行切分。
以 HBase0.92 版本为例,它提供了三种观察者接口:
● RegionObserver:提供客户端的数据操纵事件钩子: Get、 Put、 Delete、 Scan 等。
● WALObserver:提供 WAL 相关操作钩子。
● MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
由于HBase的查询比较弱,如果需要实现类似于 select name,salary,count(1),max(salary) from user group by name,salary order by salary 等这样的复杂性的统计需求,基本上不可能,或者说比较困难,所以我们在使用HBase的时候,一般都会借助二级索引的方案来进行实现;
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
标签:文件合并 scan 观察 操作 记录 集合 活着 服务器 结构
原文地址:https://www.cnblogs.com/FrankWongWong/p/11420710.html