标签:mic optimize label gpu 更新 传递 均值 rate 优化器
单GPU时,思路很简单,前向、后向都在一个GPU上进行,模型参数更新时只涉及一个GPU。
多GPU时,有模型并行和数据并行两种情况。
模型并行指模型的不同部分在不同GPU上运行。
数据并行指不同GPU上训练数据不同,但模型是同一个(相当于是同一个模型的副本)。
TensorFlow支持的是数据并行。
数据并行的原理:CPU负责梯度平均和参数更新,在GPU上训练模型的副本。
多GPU并行计算的过程如下:
1)模型副本定义在GPU上;
2)对于每一个GPU, 都是从CPU获得数据,前向传播进行计算,得到loss,并计算出梯度;
3)CPU接到GPU的梯度,取平均值,然后进行梯度更新。这个在tf的实现思路如下:
模型参数保存在一个指定gpu/cpu上,模型参数的副本在不同gpu上,每次训练,提供batch_size*gpu_num数据,并等量拆分成多个batch,分别送入不同GPU。前向在不同gpu上进行,模型参数更新时,将多个GPU后向计算得到的梯度数据进行平均,并在指定GPU/CPU上利用梯度数据更新模型参数。
假设有两个GPU(gpu0,gpu1),模型参数实际存放在cpu0上,实际一次训练过程如下图所示:
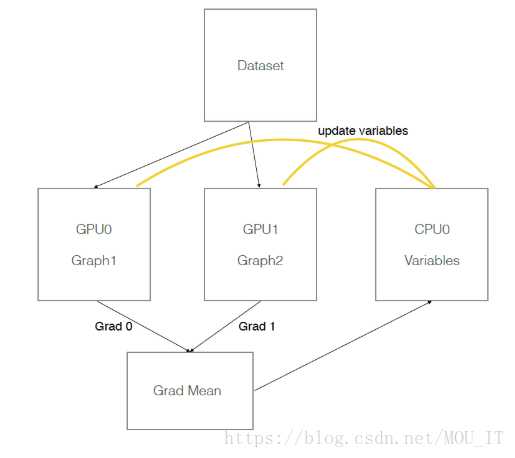
为了能让一个Slim模型在多个GPU上训练更加容易,这个模块提供了一系列帮助函数,比如create_clones()、optimize_clones()、deploy()、gather_clone_loss()、_add_gradients_summaries()、_sum_clones_gradients()等,该模块位于:https://github.com/tensorflow/models/blob/master/research/slim/deployment/model_deploy.py
用法如下:
g = tf.Graph()
# 定义部署配置信息,你可以将此类的实例传递给deploy()以指定如何部署要构建的模型。 如果未传递,则将使用从默认deployment_hparams构建的实例。
config = model_deploy.DeploymentConfig(num_clones=2, clone_on_cpu=True)
# 在保存变量的设备上创建global step
with tf.device(config.variables_device()):
global_step = slim.create_global_step()
# 定义输入
with tf.device(config.inputs_device()):
images, labels = LoadData(...)
inputs_queue = slim.data.prefetch_queue((images, labels))
# 定义优化器
with tf.device(config.optimizer_device()):
optimizer = tf.train.MomentumOptimizer(FLAGS.learning_rate, FLAGS.momentum)
# 定义模型和损失函数
def model_fn(inputs_queue):
images, labels = inputs_queue.dequeue()
predictions = CreateNetwork(images)
slim.losses.log_loss(predictions, labels)
# 模型部署
model_dp = model_deploy.deploy(config, model_fn, [inputs_queue],optimizer=optimizer)
# 开始训练
slim.learning.train(model_dp.train_op, my_log_dir,summary_op=model_dp.summary_op)Clone namedtuple:把那些每次调用model_fn的关联值保存在一起
DeployedModel namedtuple: 把那些需要被多个副本训练的值保存在一起
DeploymentConfig的参数:
标签:mic optimize label gpu 更新 传递 均值 rate 优化器
原文地址:https://www.cnblogs.com/Terrypython/p/11420718.html