标签:定时任务 机器数 prope 推荐 掌握 增强 等等 是什么 通过
SPI具体约定:当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入(从使用层面来说,就是运行时,动态给接口添加实现类)。 基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定(不需要在代码里写死)。
这样做的好处:java设计出SPI目的是为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。这样程序运行的时候,该机制就会为某个接口寻找服务的实现,有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。例如,JDBC驱动,可以加载MySQL、Oracle、或者SQL Server等,目前有不少框架用它来做服务的扩张发现。
回答这个问题可以延伸一下和API的对比,API是将方法封装起来给调用者使用的,SPI是给扩展者使用的。
Dubbo 的扩展点加载是基于JDK 标准的 SPI 扩展点发现机制增强而来的,Dubbo 改进了 JDK 标准的 SPI 的以下问题:
可从两个方面去入手,考虑接口扩展性,改造JDK的SPI机制来实现自己的扩展SPI机制。另外就是从动态代理入手,从网络通信、编码解码这些步骤以动态代理的方式植入远程调用方法中,实现透明化的调用。
暴露本地服务、暴露远程服务、启动netty、连接zookeeper、到zookeeper注册、监听zookeeper。
dubbo支持多种协议,默认使用的是dubbo协议,具体介绍官方文档写得很清楚,传送地址:相关协议介绍,重点是掌握好推荐dubbo协议。Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
在dubbo中我们一个服务可能既是Provider,又是Consumer,因此就存在他自己调用自己服务的情况,如果再通过网络去访问,那自然是舍近求远,因此他是有本地暴露服务的这个设计.从这里我们就知道这个两者的区别
zk为默认推荐,其余还有Multicast、redis、Simple等注册中心。
zookeeper的信息会缓存到服务器本地作为一个cache缓存文件,并且转换成properties对象方便使用,每次调用时,按照本地存储的地址进行调用,但是无法从注册中心去同步最新的服务列表,短期的注册中心挂掉是不要紧的,但一定要尽快修复。所以挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。
当网站处于高峰期时,并发量大,服务能力有限,那么我们只能暂时屏蔽边缘业务,这里面就要采用服务降级策略了。首先dubbo中的服务降级分成两个:屏蔽(mock=force)、容错(mock=fail)。
mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。要生效需要在dubbo后台进行配置的修改。
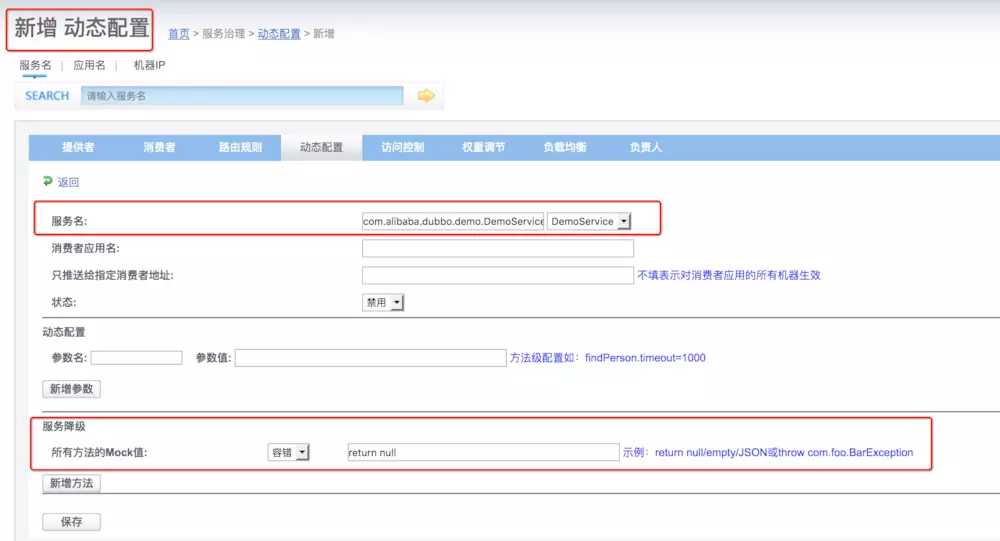
改变注册在zookeeper上的节点信息,从而zookeeper通知重新生成invoker(这些具体细节在zookeeper创建节点,zookeeper连接,zookeeper订阅中都详细讲了,这里不再重复)。
标签:定时任务 机器数 prope 推荐 掌握 增强 等等 是什么 通过
原文地址:https://www.cnblogs.com/fanguangdexiaoyuer/p/11421600.html