标签:效率比较 计算 参数 点数据 arrays 北京 edr split ack
首先准备好文件
Hello World
Hello Java
Hello World
Hello hadoop
wo
shi
wo
开始编写程序
public class MapReduceTest { //第一个参数是我们的行偏移量 //第二个参数是我们的数据集 //第三个是我们要输出时候的key类型 //第四个是我们要输出时候的value类型 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable>{ //重写map方法 //第一个参数是偏移量 第二个是我们读取的数据集 第三个是上下文简单点说就说往文件上写要用到这个参数 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] s = value.toString().split(" ");//把数据按照空格切分 for (String values:s) {//用for循环去遍历我们的数组 //第一个参数是输出的key,第二个是value //这里为什么value是1呢 是因为一会我们要在reduce阶段统计出现的次数 现在数据就拆分成了 <hello ,1> context.write(new Text(values),new IntWritable(1));//将我们的数据输出// } } } //第一个、二个参数是跟map输出时候的类型保持一致 //第三个、四个是我们一会要输出时候的类型 Text == String IntWritable == int public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable value:values) {//遍历我们刚才在map端得到的数据 sum +=value.get(); //value.get()得到每一个数据后面的1并用+=把他们相加起来 } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf);//注意要导这个import org.apache.hadoop.mapreduce.Job包 job.setMapperClass(Map.class);//这里写的是我们的自定义Map方法名 job.setReducerClass(Reduce.class);//自定义Reduce方法名 job.setJarByClass(MapReduceTest.class);//这里写的是主类 job.setMapOutputKeyClass(Text.class);//Map输出时候key的类型 job.setMapOutputValueClass(IntWritable.class);//Map输出时候value的类型 job.setCombinerClass(Reduce.class);//这里这个是在map阶段进行了一次整合 job.setOutputKeyClass(Text.class);//这是输出时候的key类型 job.setOutputValueClass(IntWritable.class);//这是输出时候的key类型 FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test\\"));//文件存放的位置一定要有 FileSystem fs=FileSystem.get(conf); Path paths = new Path("D:\\新建文件夹\\demo"); //判断一下是否有这个文件夹有则删除 if (fs.exists(paths)){ fs.delete(paths,true); } FileOutputFormat.setOutputPath(job,paths);//文件输出的位置一定不能有 job.submit();//job提交 } }
文件1
name,money tom,100 kebi,200 tom,500 susan,600 hua,1000 hua,5000 xin,600
文件2
name,money tom,400 tom,500 susan,650 kebi,5000 xin,600 hua,800
代码编写
public class MapReduceTest02 { public static class Map extends Mapper<LongWritable, Text,Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer stringTokenizer=new StringTokenizer(value.toString(),","); if (key.get()!=0){//当偏移量不等于0时可以去掉第一行没有用的数据 while (stringTokenizer.hasMoreTokens()){ String name = stringTokenizer.nextToken(); String money = stringTokenizer.nextToken(); context.write(new Text(name),new IntWritable(Integer.parseInt(money))); } } } } public static class Reduce extends Reducer<Text, IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0;//总钱数 for (IntWritable value:values) { sum += value.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setJarByClass(MapReduceTest02.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test02\\")); Path path = new Path("D:\\新建文件夹\\output"); FileSystem fileSystem = FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
准备文件
如下是各自的好友列表,要求得出他们的共同好友,如A-B C,D,E。
A:B,C,D,E,F,M
B:C,D,L,E
C:A,B,E,F,D
D:G,A,V,X,E,B
E:F,A,C,B,T
F:A,D,B
G:M,L,K,B
编写代码
//我们先找出拥有这个好友的所有人
public class MapReduceTest03 { public static class Map extends Mapper<LongWritable, Text,Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if (key.get()!=0){//去除第一行无用数据 String[] split = value.toString().split(":");//先按:分割 String[] split1 = split[1].split(",");//按照,号继续分割得到我们想要的 for (String sp:split1) { context.write(new Text(sp),new Text(split[0]));//输出拥有这个好友的人 } } } } public static class Reduce extends Reducer<Text, Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for(Text friend : values){ sb.append(friend.toString()).append(","); } context.write(key, new Text(sb.toString())); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setJarByClass(MapReduceTest03.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test03\\")); Path path = new Path("D:\\新建文件夹\\output01"); FileSystem fileSystem = FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
上面的程序输出的结果
A C,F,D,E,
B G,F,E,D,C,A,
C E,A,B,
D C,F,B,A,
E D,C,A,B,
F E,A,C,
G D,
K G,
L G,B,
M G,A,
T E,
V D,
X D,
//输出我们想要的结果
public class MapReduceTest03s { public static class Map extends Mapper<LongWritable, Text,Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\t"); String[] split1 = split[1].split(","); Arrays.sort(split1);//排序去重 for (int i = 0; i < split1.length-1; i++) {//利用两个for循环对结果一一匹配 for (int j = i+1; j < split1.length; j++) { context.write(new Text(split1[i]+"-"+split1[j]),new Text(split[0])); System.out.println((split1[i]+"-"+split1[j])+"\t"+split[0]); } } } } public static class Reduce extends Reducer<Text, Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { StringBuffer sb=new StringBuffer(); for (Text te:values) { sb.append(te).append(","); } context.write(key, new Text(sb.toString())); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setJarByClass(MapReduceTest03s.class); job.setMapperClass(MapReduceTest03s.Map.class); job.setReducerClass(MapReduceTest03s.Reduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\output01\\")); Path path = new Path("D:\\新建文件夹\\output02"); FileSystem fileSystem = FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
最终结果展示
A-B E,C,D, A-C E,B,F,D, A-D B,E, A-E B,F,C, A-F D,B, A-G B,M, B-C D,E, B-D E, B-E C, B-F D, B-G L, C-D A,E,B, C-E B,A,F, C-F D,B,A, C-G B, D-E B,A, D-F A,B, D-G B, E-F B,A, E-G B, F-G B,
{"uid":"1000166111","phone":"17703771999","addr":"河南省 南阳"}
{"uid":"1000432103","phone":"15388889881","addr":"云南省 昆明"}
{"uid":"1000473355","phone":"15388889557","addr":"云南省 昆明"}
{"uid":"1000555472","phone":"18083815777","addr":"云南省 昆明"}
{"uid":"1000585644","phone":"15377892222","addr":"广东省 中山"}
{"uid":"1000774061","phone":"18026666666","addr":"广东省 惠州"}
{"uid":"1001024965","phone":"18168526111","addr":"江苏省 苏州"}
{"uid":"1001283200","phone":"15310952123","addr":"重庆"}
{"uid":"1001523180","phone":"15321168157","addr":"北京"}
//先创建一个实体类
//实现Writable接口 public class Phone implements Writable { private String uid; private String phone; private String addr; public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public String getAddr() { return addr; } public void setAddr(String addr) { this.addr = addr; } public Phone() { } public Phone(String uid, String phone, String addr) { this.uid = uid; this.phone = phone; this.addr = addr; } @Override public void write(DataOutput dataOutput) throws IOException {//序列化 dataOutput.writeUTF(this.uid); dataOutput.writeUTF(this.phone); dataOutput.writeUTF(this.addr); } @Override public void readFields(DataInput dataInput) throws IOException {//反序列化 this.uid=dataInput.readUTF(); this.phone=dataInput.readUTF(); this.addr=dataInput.readUTF(); } @Override public String toString() { return "Phone{" + "uid=‘" + uid + ‘\‘‘ + ", phone=‘" + phone + ‘\‘‘ + ", addr=‘" + addr + ‘\‘‘ + ‘}‘; } }
public class Json2Object { public static class Map extends Mapper<LongWritable, Text,Phone, NullWritable>{ Phone phone; String line; @Override protected void setup(Context context) throws IOException, InterruptedException { //代码的优化让我们的实例在内存中仅实例化一次 phone=new Phone(); line=new String(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { line=new String(value.getBytes(),0,value.getLength(),"GBK");//处理乱码 ObjectMapper objectMapper=new ObjectMapper(); Phone phones = objectMapper.readValue(line, Phone.class);//这句就能把我们的json数据转换为对象 context.write(phones,NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(Map.class); job.setJarByClass(Json2Object.class); job.setMapOutputKeyClass(Phone.class); job.setMapOutputValueClass(NullWritable.class); job.setNumReduceTasks(0);//我们这个不需要reduce计算所以把他设置为0 FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test07\\")); FileSystem fs=FileSystem.get(conf); Path paths = new Path("D:\\新建文件夹\\json"); if (fs.exists(paths)){ fs.delete(paths,true); } FileOutputFormat.setOutputPath(job,paths); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
准备一个文件里面一个单词非常多别的很少
//先实现我们的分区
public class PartitonerTest extends Partitioner<Text, IntWritable> { @Override public int getPartition(Text text, IntWritable intWritable, int i) { Random random=new Random();//定义一个随机数 return random.nextInt(i);//这里面的i就是ReduceTasks的数量 } }
//再把数据比较均匀的分散在4各分区中
public class MapReduceTest { public static class Map extends Mapper<LongWritable, Text, Text,IntWritable>{ Text text; IntWritable intWritable; @Override protected void setup(Context context) throws IOException, InterruptedException { text=new Text(); intWritable=new IntWritable(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] s = value.toString().split(" "); for (String it:s) { intWritable.set(1); text.set(it); System.out.println(text); if (!text.equals("")) context.write(text,intWritable); } } } public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable value:values) { sum +=value.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setJarByClass(MapReduceTest.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setCombinerClass(Reduce.class); job.setPartitionerClass(PartitonerTest.class); job.setNumReduceTasks(4);//这里面我们设置了4个文件 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test04")); Path path=new Path("D:\\新建文件夹\\lx"); FileSystem fileSystem=FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
//再去我们 刚才分好的四个分区中去计算单词个数
public class MapReduceTest02 { public static class Map extends Mapper<LongWritable, Text, Text,IntWritable>{ Text text; IntWritable intWritable; @Override protected void setup(Context context) throws IOException, InterruptedException { text=new Text(); intWritable=new IntWritable(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] s = value.toString().split("\t"); intWritable.set(Integer.parseInt(s[1])); for (String it:s) { text.set(it); context.write(text,intWritable); } } } public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum=0; for (IntWritable value:values) { sum +=value.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setJarByClass(MapReduceTest02.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setCombinerClass(Reduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\lx")); Path path=new Path("D:\\新建文件夹\\lx10"); FileSystem fileSystem=FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
name,age,score,sex tom,10,100,女 susa,9,99,男 hua,60,10,dog 多喝水,大
//创建实体类 public class Person implements Writable { private String name; private int age; private int score; private String sex; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public int getScore() { return score; } public void setScore(int score) { this.score = score; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public Person() { } public Person(String name, int age, int score, String sex) { this.name = name; this.age = age; this.score = score; this.sex = sex; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(this.name); dataOutput.writeInt(this.age); dataOutput.writeInt(this.score); dataOutput.writeUTF(this.sex); } @Override public void readFields(DataInput dataInput) throws IOException { this.name = dataInput.readUTF(); this.age=dataInput.readInt(); this.score=dataInput.readInt(); this.sex=dataInput.readUTF(); } @Override public String toString() { return "Person{" + "name=‘" + name + ‘\‘‘ + ", age=" + age + ", score=" + score + ", sex=‘" + sex + ‘\‘‘ + ‘}‘; } }
public class Data2Object { public static class Map extends Mapper<LongWritable, Text,Person, NullWritable>{ Person person; String line; @Override protected void setup(Context context) throws IOException, InterruptedException { person=new Person(); line=new String(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if (key.get()!=0){ line=new String(value.getBytes(),0,value.getLength(),"GBK"); String[] split = line.toString().split(","); if (split.length>=4){ person.setName(split[0]); person.setAge(Integer.parseInt(split[1])); person.setScore(Integer.valueOf(split[2])); person.setSex(split[3]); System.out.println(person); context.write(person,NullWritable.get()); } } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(Map.class); job.setJarByClass(Data2Object.class); job.setMapOutputKeyClass(Person.class); job.setMapOutputValueClass(NullWritable.class); job.setNumReduceTasks(0); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\test06\\")); FileSystem fs=FileSystem.get(conf); Path paths = new Path("D:\\新建文件夹\\data"); if (fs.exists(paths)){ fs.delete(paths,true); } FileOutputFormat.setOutputPath(job,paths); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } } }
网站提取 提取出对应公司的名称。 如:http://v.baidu.com/movie提取出baidu http://movie.youku.com提取出youku https://image.baidu.com提取出baidu http://blog.csdn.net/article/details/47444699提取出csdn 数据处理: 统计每个“公司”的上行流量之和、下行流量之和、总流量之和。 总流量=上行流量+下行流量 结果展示形式: 公司,上行流量之和,下行流量之和,总流量之和
这是实例的文件可以多弄点数据
电话号码 网址 上行流量 下行流量 15639120688 http://v.baidu.com/movie 3936 12058 13905256439 http://movie.youku.com 10132 538 15192566948 https://image.baidu.com 19789 5238 14542296218 http://v.baidu.com/tv 7504 13253 17314017739 http://www.weibo.com/?category=7 7003 79 14554637796 http://v.baidu.com/tv 15494 7950 13793181795 http://weibo.com/?category=1760 996 15246 18350161914 https://image.baidu.com 1600 5101 15255537988 http://blog.csdn.net/article/details/47444699 17666 7643 18515646476 https://zhidao.baidu.com/question/1430480451137504979.html 10826 10043 15932420636 http://movie.youku.com 977 3136 18567886220 http://www.weibo.com/?category=7 4652 4336 13694165557 http://movie.youku.com 9610 17284 14728294152 http://www.weibo.com/?category=7 15955 6533 13773776226 http://blog.csdn.net/article/details/47444699 10536 8208 15399710194 http://v.baidu.com/tv 5224 6962 17508400165 http://v.baidu.com/movie 18758 15853 13307519578 http://blog.csdn.net/article/details/47444699 14261 15569 15975769645 http://v.baidu.com/tv 9118 7682 17640300232 http://blog.csdn.net/article/details/47444699 2790 56 18539313261 https://zhidao.baidu.com/question/1430480451137504979.html 1131 18106 15531448828 https://zhidao.baidu.com/question/1430480451137504979.html 2181 2498 17779548801 https://zhidao.baidu.com/question/1430480451137504979.html 1287 5243
//先创建对象的实体类 public class Gongsi implements Writable { private String name; private int shang; private int xia; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getShang() { return shang; } public void setShang(int shang) { this.shang = shang; } public int getXia() { return xia; } public void setXia(int xia) { this.xia = xia; } public Gongsi() { } public Gongsi(String name, int shang, int xia) { this.name = name; this.shang = shang; this.xia = xia; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(this.name); dataOutput.writeInt(this.shang); dataOutput.writeInt(this.xia); } @Override public void readFields(DataInput dataInput) throws IOException { this.name = dataInput.readUTF(); this.shang = dataInput.readInt(); this.xia = dataInput.readInt(); } @Override public String toString() { return "Gongsi{" + "name=‘" + name + ‘\‘‘ + ", shang=" + shang + ", xia=" + xia + ‘}‘; } }
public class NameMapReduceObject { public static class NameMapReduceMap extends Mapper<LongWritable, Text,Text,Gongsi>{ Text text; Gongsi gongsi; String names; @Override protected void setup(Context context) throws IOException, InterruptedException { text=new Text(); gongsi=new Gongsi(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); if (key.get()!=0){ String[] http = split[1].split("://"); String[] yuming = http[1].split("/"); String[] name = yuming[0].split("[.]"); if (name.length>=3){//判断一下切出来的是否长度大于等于3 names=name[1]; }else { names=name[0]; } //给实体赋值 gongsi.setName(names); gongsi.setShang(Integer.parseInt(split[2])); gongsi.setXia(Integer.parseInt(split[3])); text.set(names); context.write(text,gongsi); } } } public static class NameMapReduceReduce extends Reducer<Text,Gongsi,Text,Text> { Text text; @Override protected void setup(Context context) throws IOException, InterruptedException { text=new Text(); } @Override protected void reduce(Text key, Iterable<Gongsi> values, Context context) throws IOException, InterruptedException { int shang=0; int xia=0; int sum=0; for (Gongsi gs:values) { shang += gs.getShang(); xia += gs.getXia(); } sum = shang+xia; String zong=shang+" "+xia+" "+sum; text.set(zong); context.write(key,text); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(NameMapReduceMap.class); job.setReducerClass(NameMapReduceReduce.class); job.setJarByClass(NameMapReduceObject.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Gongsi.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\http\\")); FileSystem fs=FileSystem.get(conf); Path paths = new Path("D:\\新建文件夹\\name1"); if (fs.exists(paths)){ fs.delete(paths,true); } FileOutputFormat.setOutputPath(job,paths); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
需求说明: 计算每个人相应科目的平均分。 将同一个科目的放在一个文件中,并按照平均分从大到小排序。 结果展示形式: part1文件中: computer huangxiaoming 92.5 computer xuzheng 91.2 …… part2文件中: english zhaobenshan 95.1 english liuyifei 94.3 ……
//文件准备 computer,huangxiaoming,85,86,41,75,93,42,85 computer,xuzheng,54,52,86,91,42 computer,huangbo,85,42,96,38 english,zhaobenshan,54,52,86,91,42,85,75 english,liuyifei,85,41,75,21,85,96,14 algorithm,liuyifei,75,85,62,48,54,96,15 computer,huangjiaju,85,75,86,85,85 english,huangdatou,48,58,67,86,15,33,85 algorithm,huanglei,76,95,86,74,68,74,48 algorithm,huangjiaju,85,75,86,85,85,74,86 computer,huangdatou,48,58,67,86,15,33,85 english,zhouqi,85,86,41,75,93,42,85,75,55,47,22 english,huangbo,85,42,96,38,55,47,22 algorithm,liutao,85,75,85,99,66 computer,huangzitao,85,86,41,75,93,42,85 math,wangbaoqiang,85,86,41,75,93,42,85 computer,liujialing,85,41,75,21,85,96,14,74,86 computer,liuyifei,75,85,62,48,54,96,15 computer,liutao,85,75,85,99,66,88,75,91 computer,huanglei,76,95,86,74,68,74,48 english,liujialing,75,85,62,48,54,96,15 math,huanglei,76,95,86,74,68,74,48 math,huangjiaju,85,75,86,85,85,74,86 math,liutao,48,58,67,86,15,33,85 english,huanglei,85,75,85,99,66,88,75,91 math,xuzheng,54,52,86,91,42,85,75 math,huangxiaoming,85,75,85,99,66,88,75,91 math,liujialing,85,86,41,75,93,42,85,75 english,huangxiaoming,85,86,41,75,93,42,85 algorithm,huangdatou,48,58,67,86,15,33,85 algorithm,huangzitao,85,86,41,75,93,42,85,75
//因为我们要进行排序所以要实现WritableComparable重写compareTo方法 public class Arrst implements WritableComparable<Arrst> { private String kemu; private String name; private double abs; public Arrst() { } public Arrst(String kemu, String name,double abs) { this.kemu = kemu; this.name = name; this.abs=abs; } public double getAbs() { return abs; } public void setAbs(double abs) { this.abs = abs; } public String getKemu() { return kemu; } public void setKemu(String kemu) { this.kemu = kemu; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Arrst{" + "kemu=‘" + kemu + ‘\‘‘ + ", name=‘" + name + ‘\‘‘ + ", abs=" + abs + ‘}‘; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(this.kemu); dataOutput.writeUTF(this.name); dataOutput.writeDouble(this.abs); } @Override public void readFields(DataInput dataInput) throws IOException { this.kemu = dataInput.readUTF(); this.name = dataInput.readUTF(); this.abs=dataInput.readDouble(); } @Override public int compareTo(Arrst o) { if (o.getAbs() == this.getAbs()){//如果平均分相同则按照名字排序 return o.getName().compareTo(this.getName()); }else {//如果不同从大到小排序 return o.getAbs() > this.getAbs() ? 1:-1; } } }
//编写我们的分区确保每一科目都进入相同的文件中 public class PartitonerScore extends Partitioner<Arrst, Text> { Map<String, Integer> num=new HashMap<>(); @Override public int getPartition(Arrst arrst, Text text, int i) { num.put("computer",0); num.put("english",1); num.put("algorithm",2); num.put("math",3); Integer integer = num.get(arrst.getKemu());//用key获得value return integer; } }
public class ScoerMapReduce { public static class Map extends Mapper<LongWritable, Text,Arrst,Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(","); double sum=0; int s=0; double abs=0; for (int i = 2; i <split.length ; i++) { s++; sum += Integer.parseInt(split[i]); } abs=sum/s; Arrst arrst=new Arrst(); arrst.setKemu(split[0]); arrst.setName(split[1]); arrst.setAbs(abs); context.write(arrst,new Text(split[0])); } } public static class Reduce extends Reducer<Arrst,Text,Text,Text> { @Override protected void reduce(Arrst key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text it:values) { String ss=key.getName()+" "+key.getAbs(); context.write(new Text(it),new Text(ss)); } } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setJarByClass(ScoerMapReduce.class); job.setMapOutputKeyClass(Arrst.class); job.setMapOutputValueClass(Text.class); job.setPartitionerClass(PartitonerScore.class); job.setOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setNumReduceTasks(4);//这里不要忘记写我们想要几个文件 FileInputFormat.setInputPaths(job,new Path("D:\\新建文件夹\\score\\")); Path path = new Path("D:\\新建文件夹\\scoreoutput"); FileSystem fileSystem = FileSystem.get(conf); if (fileSystem.exists(path)){ fileSystem.delete(path); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
Reduce端连接比Map端连接更为普遍,因为输入的数据不需要特定的结构,
但是效率比较低,因为所有数据都必须经过Shuffle过程。
基本思路:
1、Map端读取所有的文件,并在输出的内容里加上标示,代表数据是从哪个文 件里来的。
2、在reduce处理函数中,按照标识对数据进行处理。
3、然后根据Key去join来求出结果直接输出。
准备两个文件上传到hdfs集群上
110 鞋子 111 裤子 112 上衣 113 泳衣
110 500 111 300 112 200 113 1000
public class JoinMapReduce { public static class JoinMapReduceMap extends Mapper<LongWritable, Text, Text, NullWritable> { Map<String,String> shangmap=new HashMap<>(); String line; Text text; @Override protected void setup(Context context) throws IOException, InterruptedException { line=new String(); text=new Text(); BufferedReader br = new BufferedReader(new FileReader("file.txt"));//准备一个流读取我们hdfs上的文件 String line=""; while ((line=br.readLine())!=null){ String[] split = line.split(" "); shangmap.put(split[0],split[1]);//把数据添加到map集合中 } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); String jia = shangmap.get(split[0]);//利用刚才得到的数据座位key去获得value String ss=split[0]+" "+jia+" "+split[1]; text.set(ss); context.write(text,NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); job.setMapperClass(JoinMapReduceMap.class); job.setJarByClass(JoinMapReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setNumReduceTasks(0);//不用reduce阶段就设置为0 FileInputFormat.setInputPaths(job,new Path("hdfs://master:9000/mapjoin/input1/")); FileSystem fs=FileSystem.get(conf); Path paths = new Path("hdfs://master:9000/outfile");//这个位置的目录不能存在 job.addCacheFile(new URI("hdfs://master:9000/mapjoin/input2/file.txt"));//这个必须精确到某个文件 if (fs.exists(paths)){ fs.delete(paths,true); } FileOutputFormat.setOutputPath(job,paths); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
我们把程序都写好后开始打包发送到我们的hadoop集群上
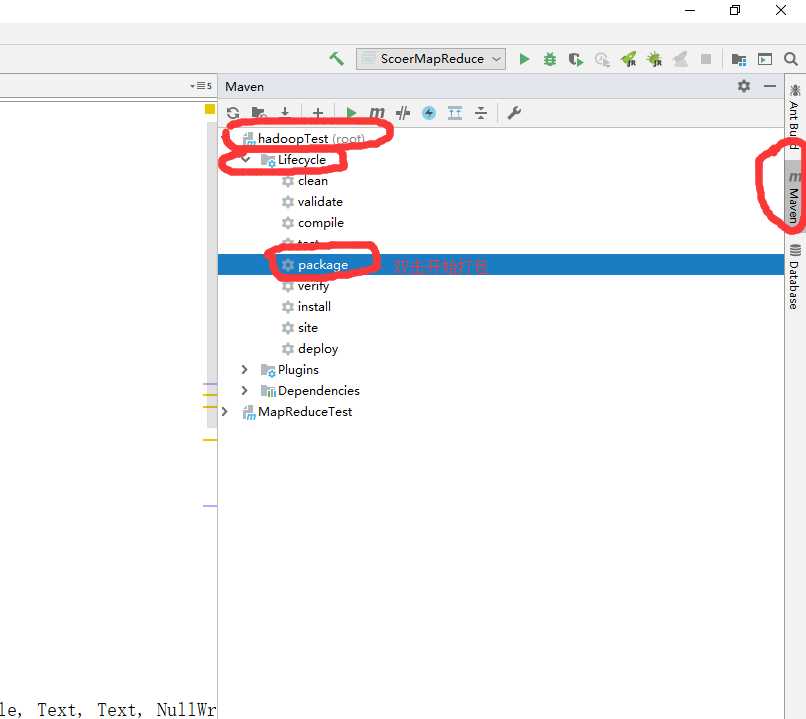
用xftp把刚才我们打包好的jar文件拖到我们的linux系统上
然后在存放jar目录下执行
hadoop jar join.jar com.dzm.join.JoinMapReduce
hadoop jar固定这么写 后面的 join.jar是我们刚才发送的jar名字 在后面是我们的全包名+类名
查看我们刚才执行完的程序
hdfs dfs -cat /test/output/part*
/test/output/part*是我们程序里自定义的输出目录位置
标签:效率比较 计算 参数 点数据 arrays 北京 edr split ack
原文地址:https://www.cnblogs.com/tkzm/p/11428137.html