标签:数据信息 man apache 创建DAG depend 遍历 恢复 交互 就是
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
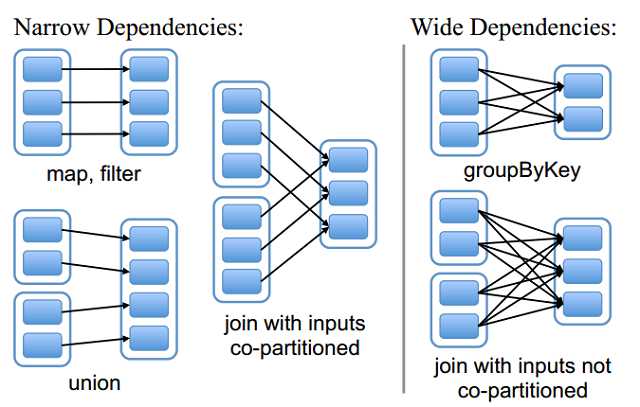
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女。窄依赖不会产生shuffle,比如说:flatMap/map/filter....
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:宽依赖我们形象的比喻为超生。宽依赖会产生shuffle,比如说:reduceByKey/groupByKey...
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
rdd1.cache
rdd2.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)
cache:默认是把数据缓存在内存中,其本质是调用了persist方法
persist:它可以把数据缓存在磁盘中,它可以有很多丰富的缓存级别,这些缓存级别都被封装在一个object StorageLevel

通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
(1)自动清除
整个应用程序结束之后,缓存中的所有数据自动清除
(2)手动清除
手动调用rdd的unpersist(true)
(1)某个rdd后期被使用了多次
val rdd2=rdd1.flatMap(_.split(" "))
val rdd3=rdd1.map((_,1))
上面rdd1被使用了多次,后期可以对rdd1的结果数据进行缓存,缓存之后后面用到了它,可以直接从缓存中获取得到。避免重新计算,浪费时间。
(2)一个rdd的结果数据计算逻辑比较复杂或者是计算时间比较长-------> 总之 它的数据来之不易
val rdd1=sc.textFile("/words.txt").flatMap(_.split(" ")).xxxx .xxxxx..............
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
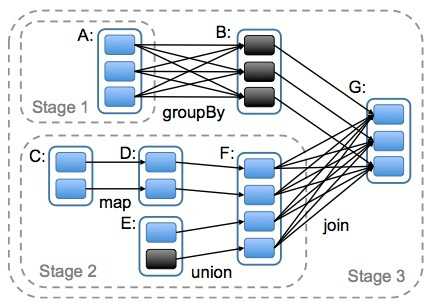
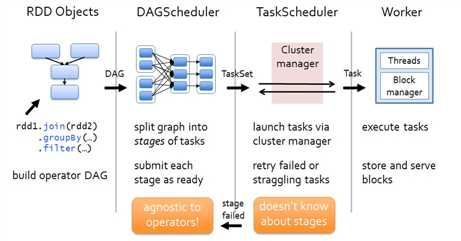
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
(1)Driver会运行客户端main方法中的代码,代码就会构建SparkContext对象,在构建SparkContext对象中,会创建DAGScheduler和TaskScheduler,然后按照rdd一系列的操作生成DAG有向无环图。最后把DAG有向无环图提交给DAGScheduler。
(2)DAGScheduler拿到DAG有向无环图后,按照宽依赖进行stage的划分,这个时候会产生很多个stage,每一个stage中都有很多可以并行运行的task,把每一个stage中这些task封装在一个taskSet集合中,最后提交给TaskScheduler。
(3)TaskScheduler拿到taskSet集合后,依次遍历每一个task,最后提交给worker节点的exectuor进程中。task就以线程的方式运行在worker节点的executor进程中。
(1)DAGScheduler对DAG有向无环图进行Stage划分。
(2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
(3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler
(4)将 Taskset 传给底层调度器
a)– spark-cluster TaskScheduler
b)– yarn-cluster YarnClusterScheduler
c)– yarn-client YarnClientClusterScheduler
(1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
(2)数据本地性决定每个Task最佳位置
(3)提交 taskset( 一组task) 到集群运行并监控
(4)推测执行,碰到计算缓慢任务需要放到别的节点上重试
(5)重新提交Shuffle输出丢失的Stage给DAGScheduler
sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
标签:数据信息 man apache 创建DAG depend 遍历 恢复 交互 就是
原文地址:https://www.cnblogs.com/mediocreWorld/p/11432298.html