标签:des style blog http color io os ar 使用
基础知识普及:
对于筛选索引,MSDN如是说:
筛选索引是一种经过优化的非聚集索引,尤其适用于涵盖从定义完善的数据子集中选择数据的查询。 筛选索引使用筛选谓词对表中的部分行进行索引。 与全表索引相比,设计良好的筛选索引可以提高查询性能、减少索引维护开销并可降低索引存储开销。
筛选索引与全表索引相比具有以下优点:
提高了查询性能和计划质量 设计良好的筛选索引可以提高查询性能和执行计划质量,因为它比全表非聚集索引小并且具有经过筛选的统计信息。 与全表统计信息相比,经过筛选的统计信息更加准确,因为它们只涵盖筛选索引中的行。
减少了索引维护开销 仅在数据操作语言 (DML) 语句对索引中的数据产生影响时,才对索引进行维护。 与全表非聚集索引相比,筛选索引减少了索引维护开销,因为它更小并且仅在索引中的数据更改时才进行维护。 筛选索引的数量可以非常多,特别是在其中包含很少更改的数据时。 同样,如果筛选索引只包含频繁修改的数据,则索引大小较小时可以减少更新统计信息的开销。
减少了索引存储开销 在没必要创建全表索引时,创建筛选索引可以减少非聚集索引的磁盘存储开销。 可以使用多个筛选索引替换一个全表非聚集索引而不会明显增加存储需求。
MSDN地址:http://msdn.microsoft.com/zh-cn/library/cc280372(v=sql.105).aspx
--========================================================
基础案例介绍:
在很多场景中,过滤索引能解决很多复合索引无法处理的问题,成为一些特殊问题的必杀技,如下面的查询:
SELECT TOP(10) C2 FROM TB1 WHERE C1>5 ORDER BY C2 DESC
如果按C2倒序排序后,排在结果集前面的大多数行都满足C1>5的条件的话,那么我们可以建立以下索引来优化:
CREATE INDEX IDX_C2_INC ON TB1(C2) INCLUDE(C1)
但如果满足C1>5的行特别少或者排在结果集尾部的话,那么查询需要遍历索引的大部分才能找到匹配的数据返回给客户,从而导致大量逻辑IO开销。
如果满足C1>5的行比较少,那么可以使用以下索引来优化:
CREATE INDEX IDX_C1_C2 ON TB1(C1,C2)
虽然以上索引能帮助快速找到所有C1<5的行,但仍需要经过一次排序后才能获得TOP(5)的数据,而排序又会导致CPU资源开销。
随着SQL SERVER 2008引入过滤索引后,这样的查询便可以轻松搞定,我们只需要建立以下索引:
CREATE INDEX IDX_C2_WH ON TB1(C2) WHERE C1>5
查询可以通过索引很快找到满足C1>5并且按C2排序的TOP 5的数据,最小化地消耗CPU和IO资源。
--===========================================================
在SQL Server中,数据库选择的“自动创建统计(Auto Create Statistics)”选项默认为开启状态, 随着索引的创建,数据库会自动创建与之对应的统计信息,创建过滤索引的过程同样会创建对于的统计信息。
当数据库设置为自动更新统计时(数据库未开启跟踪标志情况下),SQL Server 监控表中的数据更改,当更改满足一下条件之一时更新:
1.向空表插入数据时
2.少于500行的表增加500行或者更多
3.当表中行多于500行时,数据的变化量大于20%时
(在SQL SERVER 2000中,指的是20%的行被修改,而在SQL SERVER 2005/2008中,指的是20%的列数据被修改)
PS: 20%不是一个绝对值
--===========================================================
那么问题出来了,这个20%比例对过滤索引的统计信息是否满足呢?如果满足的话,哪基数是什么呢?是表中的数据还是当前满足条件的数据呢?
让我们来做个测试吧
首先准备测试数据
--创建表,并插入5000行数据 SELECT TOP(5000) IDENTITY(INT,1,1) AS ID, * INTO TB001 FROM SYS.all_columns GO --创建聚簇索引 CREATE CLUSTERED INDEX IDX_ID ON TB001(ID) GO --创建过滤索引 CREATE INDEX IDX_COLUMNID ON TB001(object_id) WHERE Column_id<3 GO --再导入25000行数据 INSERT INTO TB001 SELECT TOP(5000) * FROM SYS.all_columns GO 5 --更新统计信息 UPDATE STATISTICS TB001 GO
查看过滤索引的统计信息
--查看过滤索引的统计信息 DBCC SHOW_STATISTICS(‘dbo.TB001‘,‘IDX_COLUMNID‘) GO
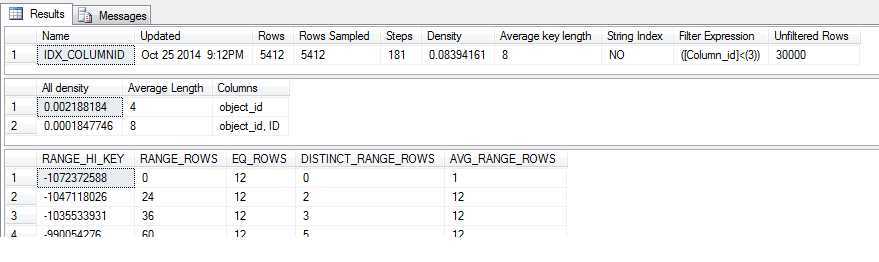
目前表中有30000行数据,满足条件的数据是5412行,都超过500行的限制,考虑20%这是一个参考值而不是绝对值,我们测试值调整到50%;为了避免版本问题导致更新行还是更新列的问题,我们统一使用插入方式来测试。
1.首先测试插入5412*50%=2706行数据
--再导入2706行数据 INSERT INTO TB001 SELECT TOP(2706) * FROM SYS.all_columns GO --执行查询尝试触发统计更新 SELECT TOP(1) object_id,COUNT(1)
FROM TB001
WHERE Column_id<3
GROUP BY object_id
ORDER BY COUNT(1) DESC --查看过滤索引的统计信息 DBCC SHOW_STATISTICS(‘dbo.TB001‘,‘IDX_COLUMNID‘) GO
统计信息未发生变化,仍旧是:
2.首先测试插入30000*50%=15000行数据(需要考虑之前已插入的2706条数据)
--再导入25000行数据 INSERT INTO TB001 SELECT TOP(5000) * FROM SYS.all_columns GO INSERT INTO TB001 SELECT TOP(5000) * FROM SYS.all_columns GO --由于之前插入2706条数据,因此第三次插入2294 INSERT INTO TB001 SELECT TOP(2294) * FROM SYS.all_columns GO SELECT COUNT(1) FROM TB001 --执行查询尝试触发统计更新 SELECT TOP(1) object_id,COUNT(1)
FROM TB001
WHERE Column_id<3
GROUP BY object_id
ORDER BY COUNT(1) DESC GO --查看过滤索引的统计信息 DBCC SHOW_STATISTICS(‘dbo.TB001‘,‘IDX_COLUMNID‘) GO
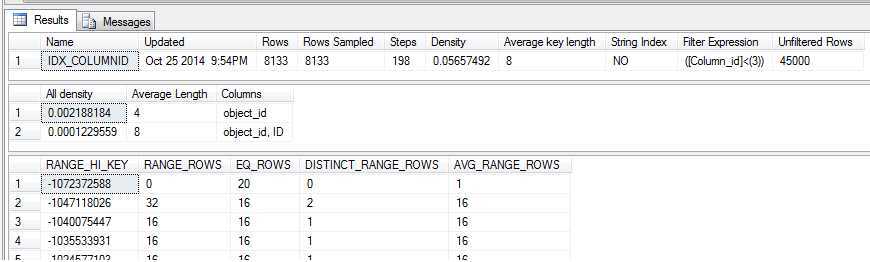
感谢上苍,感谢党,统计更新了,世界和平了,妈妈再也不用担心我的成绩了(毕业很多年啦,泪流满面啊)!!!
--=====================================================
在测试过程中,最开始想使用以下查询来触发:
SELECT TOP(1) object_id FROM TB001 WHERE Column_id<3 AND Column_id=82873218 ORDER BY object_id GO SELECT COUNT(1) FROM TB001 WHERE Column_id<3 GO
结果得出一个错误结论,经多次测试后才发现上述两个查询虽然使用到索引,但是无法触发统计更新。
--=====================================================
总结:无论是复合索引还是过滤索引的统计信息,都是以上一次统计信息更新时表的行数作为基数,当更新达到按20%左右的比例左右后,由查询执行来触发统计自动更新。
PS1: 更新数指的是操作影响的行数,如执行10次UPDATE操作,每次UPDATE影响50行数据,那么更新数为500,即使这10次UPDATE没有改变任何一条数据(类似UPDATE T1 SET C1=C1这类操作)
PS2: 即使更新数达到20%左右,查询使用到该过滤索引,也不一定会触发统计更新,只有查询优化器认为该统计过期并且需要一个更新过的统计信息来生成执行计划时,才会触发统计自动更新
PS2:由于过滤索引的只存放满足过滤条件的数据的特殊性,存在一些场景下,索引数据变化很多而对应的统计信息尚未满足过期(无效)条件,从而导致生成不高效的执行计划,因此有很多高手大神都建议专门针对这些有过滤条件的统计信息制定更新计划,提高其更新频率
PS3:除创建过滤索引会生成有过滤条件的统计信息外,数据库管理员也可以主动添加有过滤条件的统计信息,供执行优化器使用。
--=============================================
漂亮妹子看多了,来点普通的,哈哈

标签:des style blog http color io os ar 使用
原文地址:http://www.cnblogs.com/TeyGao/p/4050972.html