标签:imp 有一个 应用 数据 移动 不可 性能 梯度下降法 包含
在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练。其实,常用的梯度下降法还具体包含有三种不同的形式,它们也各自有着不同的优缺点。
下面我们以线性回归算法来对三种梯度下降法进行比较。
一般线性回归函数的假设函数为:
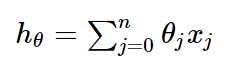
对应的代价函数为:
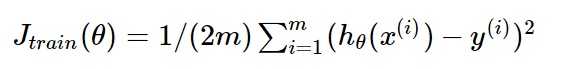
下图作为一个二维参数(,
)组对应能量函数的可视化图:
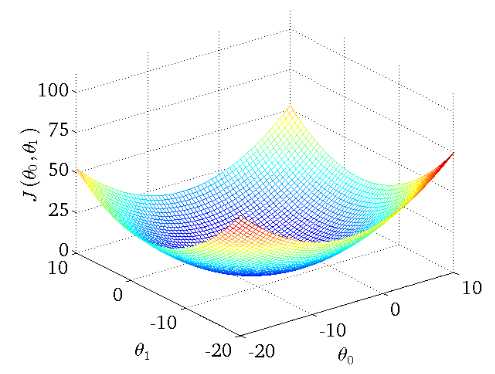
下面我们来分别讲解三种梯度下降法
我们的目的是要代价函数尽可能的小,即求解weights使误差函数尽可能小。首先,我们随机初始化weigths,然后不断反复的更新weights使得代价函数减小,直到满足要求时停止。这里更新算法我们选择梯度下降算法,利用初始化的weights并且反复更新weights:
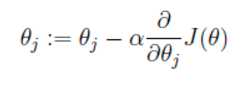
这里代表学习率,表示每次向着J最陡峭的方向迈步的大小。为了更新weights,我们需要求出函数J的偏导数。首先当我们只有一个数据点(x,y)的时候,J的偏导数是:
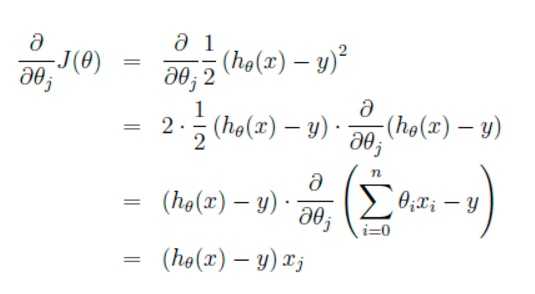
则对所有数据点,上述损失函数的偏导(累和)为:
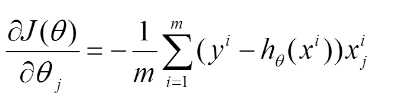
再最小化代价函数的过程中,需要不断反复的更新weights使得误差函数减小,更新过程如下:
那么好了,每次参数更新的伪代码如下(\alpha暂时被省略了):
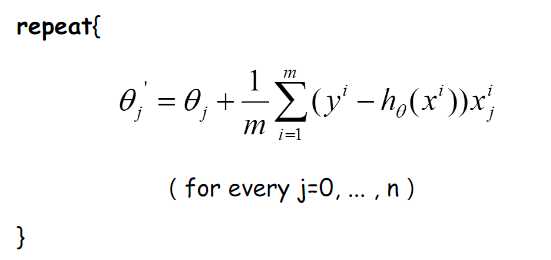
由上图更新公式我们就可以看到,我们每一次的参数更新都用到了所有的训练数据(比如有m个,就用到了m个),如果训练数据非常多的话,是非常耗时的。
下面给出批梯度下降的收敛图:
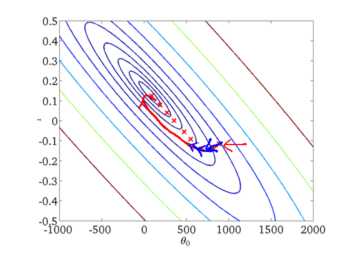
从图中,我们可以得到BGD迭代的次数相对较少。
由于批梯度下降每跟新一个参数的时候,要用到所有的样本数,所以训练速度会随着样本数量的增加而变得非常缓慢。随机梯度下降正是为了解决这个办法而提出的。它是利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ(\alpha暂时被省略了):
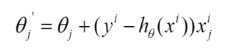
更新过程如下:

随机梯度下降是通过每个样本来迭代更新一次,对比上面的批量梯度下降,迭代一次需要用到所有训练样本(往往如今真实问题训练数据都是非常巨大),一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
随机梯度下降收敛图如下:
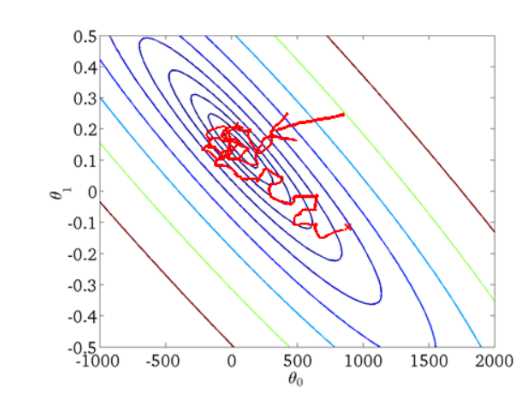
我们可以从图中看出SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。但是大体上是往着最优值方向移动。
我们从上面两种梯度下降法可以看出,其各自均有优缺点,那么能不能在两种方法的性能之间取得一个折衷呢?即,算法的训练过程比较快,而且也要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷。
我们假设每次更新参数的时候用到的样本数为10个(不同的任务完全不同,这里举一个例子而已)
更新伪代码如下:
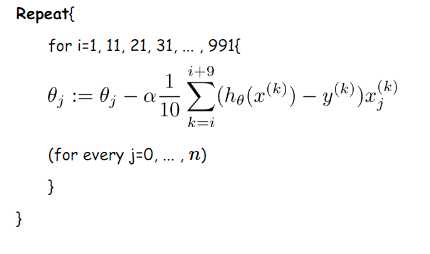
BSD
1 import numpy as np 2 3 def batch_gradient_descent(X, y, alpha, theta, iteration): 4 m = X.shape[0] 5 X_train = X.transpose() # 转置 6 7 for i in range(iteration): 8 h = np.dot(X_train, theta) 9 loss = h - y 10 gradient = np.dot(X_train, loss) / m 11 theta = theta - alpha * gradient 12 13 return theta
SGD
1 import numpy as np 2 3 def stochastic_gradient_descent(X, y, alpha, theta, iteration): 4 m = X.shape[0] 5 np.random.shuffle(X) # 打乱样本顺序 6 7 for _ in range(iteration): # 外层迭代次数 8 for j in range(m): # 遍历样本 9 h = np.dot(X[j], theta) 10 loss = h - y 11 gradient = np.dot(X[j], loss) 12 theta = theta - alpha * gradient 13 14 return theta
MBGD
1 import numpy as np 2 3 def stochastic_gradient_descent(X, y, alpha, theta, iteration, b): 4 m = X.shape[0] 5 np.random.shuffle(X) # 打乱样本顺序 6 X = X.transpose() # 转置 7 8 for _ in range(iteration): # 外层迭代次数 9 for j in range(0, m, b): # 遍历b个样本 10 h = np.dot(X[:,:j], theta) 11 loss = h - y 12 gradient = np.dot(X[:,:j], loss) 13 theta = theta - alpha * gradient 14 15 return theta
1.批梯度下降每次更新使用了所有的训练数据,最小化损失函数,优点是易得到全局最优解,易于并行实现;缺点是如果样本值很大的话,更新速度会很慢。
2.随机梯度下降在每次更新的时候,只考虑了一个样本点,这样会大大加快训练数据,但是这样造成噪声点较多,那么每一次利用噪声点进行更新的过程中,就不一定是朝着极小值方向更新,但是由于更新多轮,整体方向还是大致朝着极小值方向更新。
3.小批量梯度下降法是为了解决批梯度下降法的训练速度慢,以及随机梯度下降法的准确性综合而来,不同问题的batch是不一样的。
参考:
https://zhuanlan.zhihu.com/p/25765735、
https://www.cnblogs.com/maybe2030/p/5089753.html#_label0
标签:imp 有一个 应用 数据 移动 不可 性能 梯度下降法 包含
原文地址:https://www.cnblogs.com/huangm1314/p/11437394.html