标签:diff too record require sid nal eve 总结 并发
本文由我手动整理自 W3Cschool Hadoop 教程 (https://www.w3cschool.cn/hadoop/),看不懂就手敲了一遍,好烦呀
数据分布在多台机器上
计算随数据走
串行 IO 取代随机 IO
传输时间 << 寻道时间,一般数据写入后不在修改
Hadoop 可运行与一般的商用机器上,具有高容错,高可靠性,高扩展等特点
特别适合写一次,读多次的场景
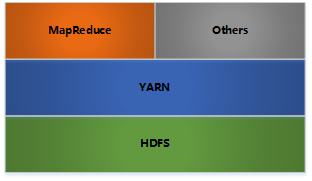
内部各个节点基本都是采用 Master-Worker 架构
Hadoop Distributed File System,分布式文件系统
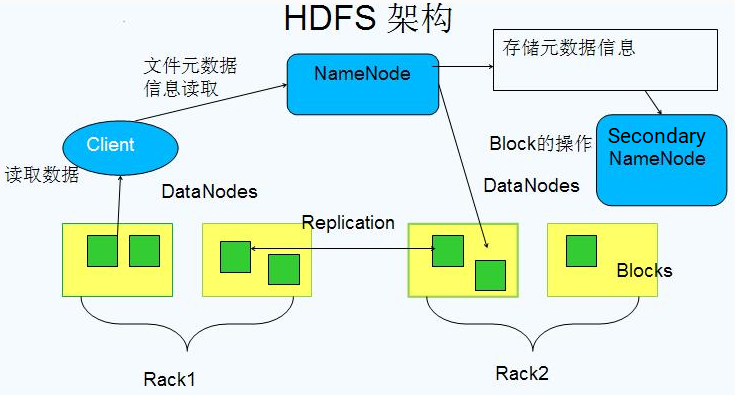
Block 数据块
NameNode
Secondary NameNode
定时与 NameNode 进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的结果传给 NameNode,替换其镜像,并清空编辑日志,类似于 CheckPoint 机制),但 NameNode 失效后仍需要手工将其设置成主机。
DataNode
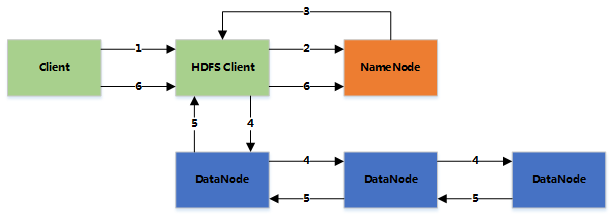
客户端将文件写入本地磁盘的文件中
当临时文件大小达到一个Block大小时,HDFS Client 通知 NameNode,申请写入文件
NameNode 在HDFS的文件系统中创建一个文件,并把该 Block ID 和要写入的 DataNode 的列表返回给客户端
客户端收到这些消息后,将临时文件写入 DataNodes
文件写完后(客户端关闭),NameNode 提交文件(这时文件才可见,如果提交前,NameNode 挂掉,那文件也就丢失了。
fsync:只保证数据的信息写到 NameNode 上,但并不保证数据已经被写道 DataNode 中)
Rack Aware(机架感知)
通过配置文件制定机架名和DNS的对应关系
假设复制参数是3,在写入文件时,会在本地的机架保存一份数据,然后再另一个机架内保存两份数据(同机架内的传输速度快,从而提高性能)
整个HDFS的集群,最好是负载均衡的,这样才能尽量利用集群的优势
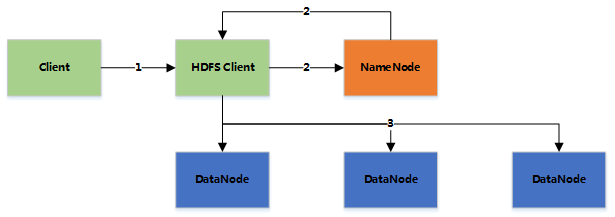
DataNode 可以失效
DataNode 会定时发送心跳到 NameNode。如果在一段时间内 NameNode 没有收到 DataNode 的心跳信息,则认为其失效。此时 NameNode 就会将该节点的数据(从该节点的复制节点中获取)复制到另外的 DataNode 中。
数据可以损坏
无论是写入时还是硬盘本身的问题,只要数据有问题(读取时通过校验码来检测),都可以通过其他的复制节点读取,同时还会再复制一份到健康的节点中。
NameNode 不可靠

架构存在的问题:
总的来说,就是 单点问题 和 资源利用率问题。
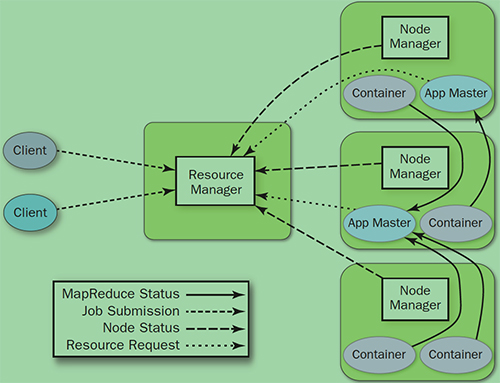
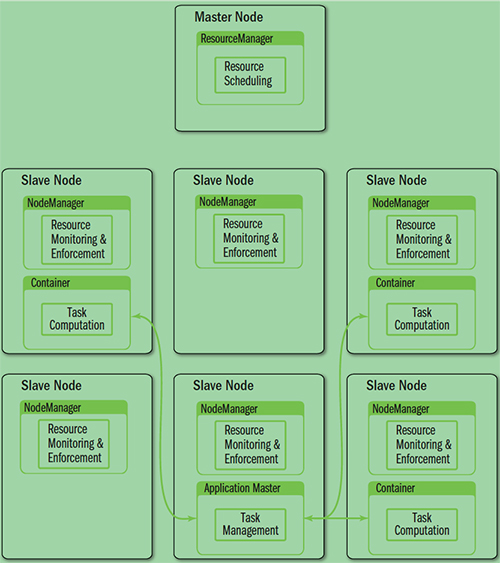
YARN 就是将 JobTracker 的职责进行拆分,将资源管理和任务调度拆分成独立的进程:一个全局的资源管理(ResourceManager)和一个单个作业的管理(ApplicationMaster)。ResourceManager 和 NodeManager 提供计算资源的分配和管理,为 ApplicationMaster 完成应用程序的运行。
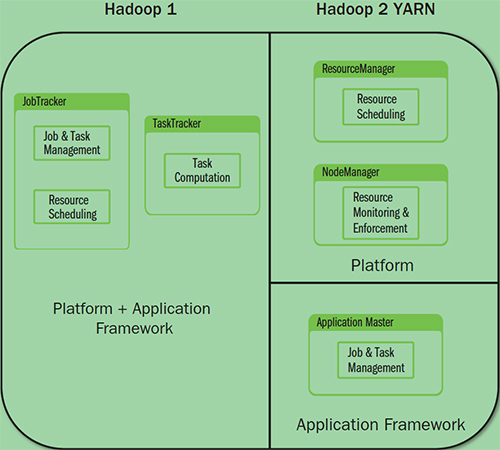
YARN 架构下形成了一个通用的资源管理平台和一个通用的应用计算平台,避免了旧架构的单点问题和资源利用率问题,同时也让在其上在运行的应用不再局限于MapReduce形式。
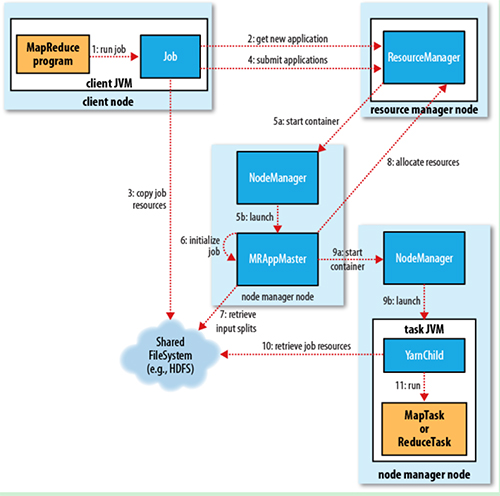

Job Submission
从 ResourceManager 中获取一个 Application ID 检查作业输出配置,计算输入分片、拷贝作业资源(Job jar、配置文件、分片信息)到 HDFS,以便后面任务的执行。
Job Initialization
ResourceManager 将作业递交给 Scheduler(有很多调度算法,一般是根据优先级)。
Scheduler为作业分配一个 Container,ResourceManager 就加载一个 application master process 并交给 NodeManager 管理。
ApplicationMaster 主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个Map task 和响应的 Reduce task。
ApplicationMaster 还决定如何运行作业,如果作业很小(可配置),则直接在同一个 JVM 下运行。
Task Assignment
ApplicationMaster 向 ResourceManager 申请资源(一个个的 Container,指定任务分配的资源要求),一般是根据 data locality 来分配资源。
Task Execution
ApplicationMaster 根据 ResourceManager 的分配情况,在对应的 NodeManager 中启动 Container,从HDFS中读取任务所需的资源(job jar,配置文件等),然后执行该任务。
Progress and Status Update
定时将任务的进度和状态报告给 ApplicationMaster Client,定时向 ApplicationMaster 获取整个任务的进度和状态。
Job Completion
Client 定时检查整个作业是否完成。作业完成后,会清空临时文件、目录等。
负责全局的资源管理和任务调度,把整个集群当成计算资源池,只关注分配,不管应用,且不负责容错。
<resource-name,priority,resource-requirement,number-of-containers>
resource-name:主机名、机架名或*(代表任意机器)resource-requirement:目前只支持CPU和内存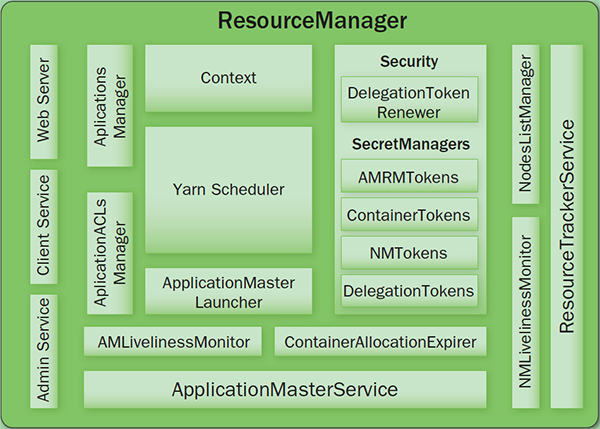

PUBLIC:/filecachePRIVATE:/usercache//filecacheAPPLICATION:/usercache//appcache//(在程序完成后会被删除)单个作业的资源管理和任务监控。
ApplicationMaster 可以是用任何语言编写的程序,它和 ResourceManager 和 NodeManager 之间是通过 ProtocolBuf 交互,以前是一个全局 JobTracker 负责的,现在每个作业都有一个,可伸缩性更强,至少不会应为作业太多,造成 JobTracker 瓶颈。同时将作业的逻辑放到一个独立的 ApplicationMaster 中,使得灵活性更高,每个作业都可以有自己的处理方式,不用绑定到 MapReduce 的处理模式上。
一般的 MapReduce 是根据 Block 数量来决定 Map 和 Reduce 的计算数量,然后一般的 Map 或 Reduce 就占用一个 Container。
数据的本地化是通过 HDFS 的 Block 分片信息获取的。
yarn.app.mapreduce.am.job.recovery.enable=true),这一步是通过将应用运行状态保存到共享的存储上来实现的,ResourceManager不会负责任务状态的保存和恢复。可以看出,一般的错误处理都是由当前模块的父模块进行监控(心跳)和恢复。而最顶端的模块则通过定时保存,同步状态和Zookeeper来实现 HA。
一种分布式的计算方式,指定一个 Map(映射) 函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归约) 函数,用来保证所有映射的键值对中的每一个共享相同的键组。
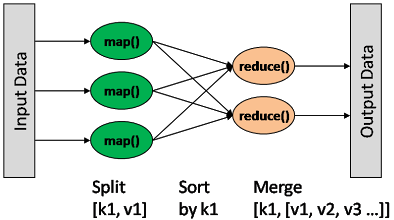
Map 输出格式和 Reduce 输入格式一定是相同的。
基本流程
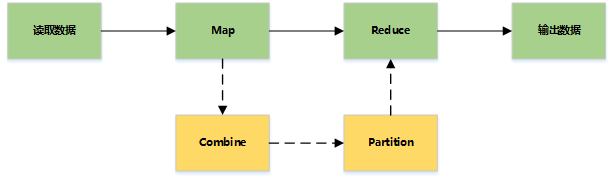
详细流程
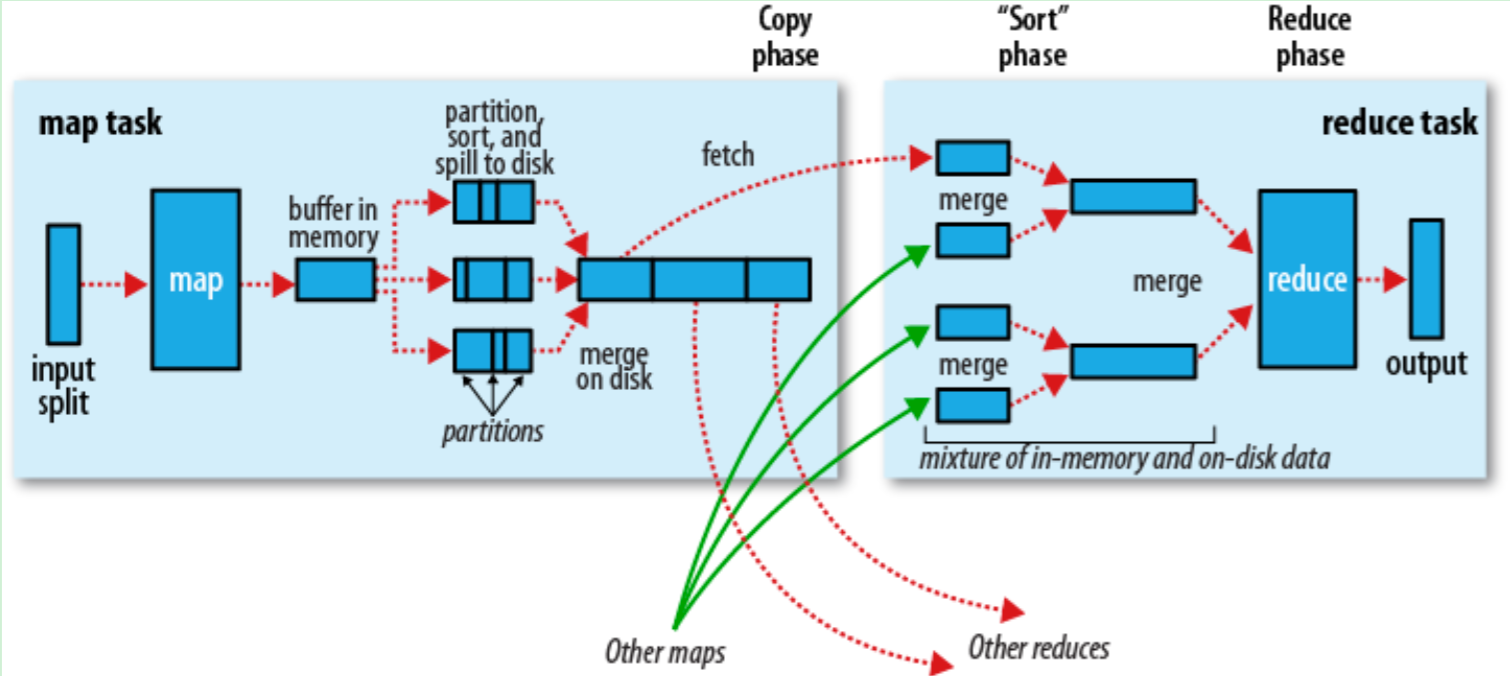
多节点下的流程
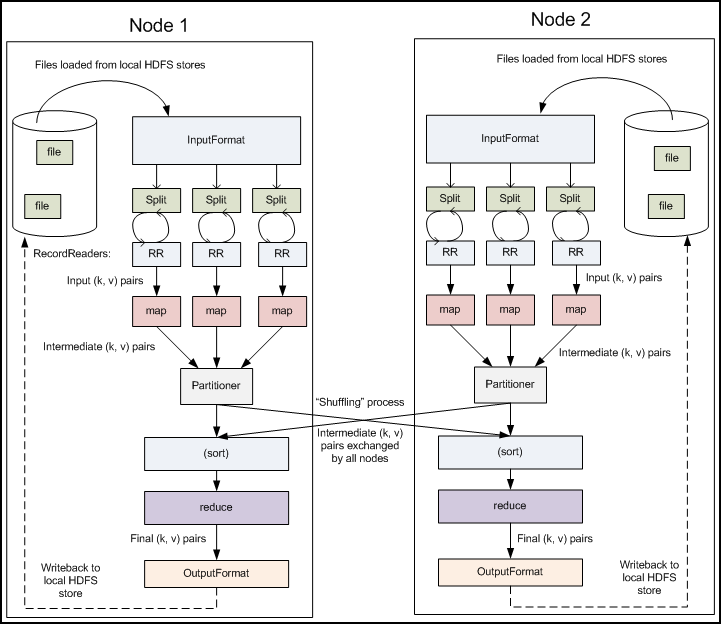
主要过程

Map Side
Record Reader
记录阅读器会翻译由输入格式生成的记录,记录阅读器用于数据解析给记录,并不分析记录本身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值对的形式传输给 Mapper。通常键是位置信息,值是构成记录的数据存储块(自定义的记录不再本文的讨论范围内)。
Map
在映射器中用户提供的代码称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义。键决定可数据分类的依据,而值决定了处理器中的分析信息。
Shuffle and Sort
Reduce 任务以随机和排序步骤开始,此步骤写入输出文件并下载到本地计算机。这些数据采用键进行排序以把等价秘钥组合到一起。
Reduce
Reduce 采用分组数据作为输入,该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当 Reduce 功能完成,就会发送0个或多个键值对。
输出格式
输出格式会转换最终的键值对并写入文件。默认情况下键和值以 tab 分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入 HDFS。类似记录读取(自定义的输出格式不再本文的讨论范围内)。
通过 InputFormat 决定读取的数据的类型,然后拆分成一个个 InputSplit,每个 InputSplit 对应一个 Map 处理,RecordReader 读取 InputSplit 的内容给 Map。
决定读取数据的格式,可以使文件或者数据库等。
List getSplits():获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题。RecordReader <K,V> createRecordReader():创建 RecordReader,从InputSplit中读取数据,解决读取分片中数据问题。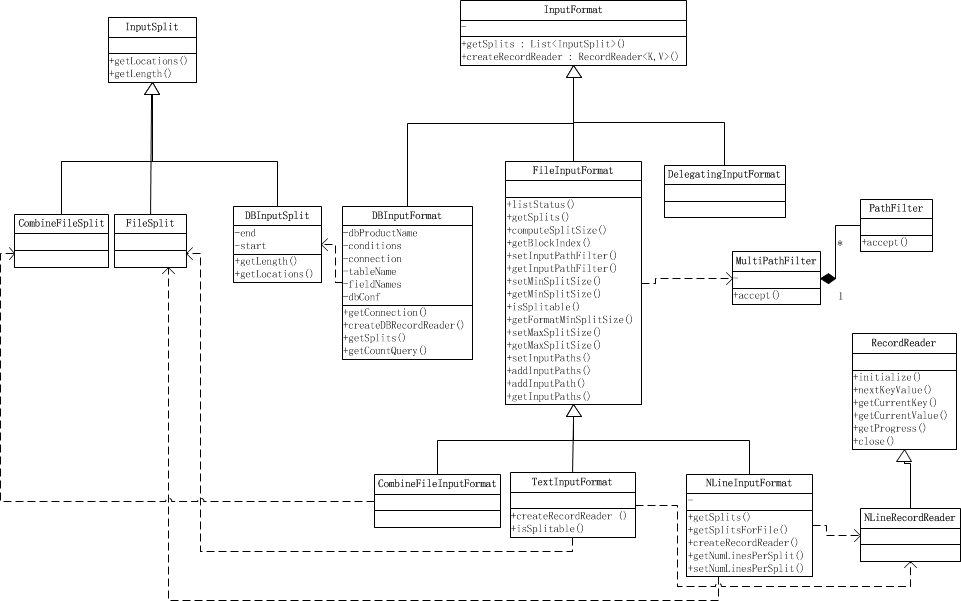
key.value.separator.in.input.line 变量设置,默认为 \t 字符。mapred.line.input.format.linespermap 属性,默认为 1。代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法。
Split内有 Location 信息,有利于数据局部化。一个InputSplit交给一个单独的 Map 处理。
public abstract class InputSplit {
/**
* 获取 Split 的大小,支持根据 size 对 InputSplit 排序。
*/
public abstract long getLength() throws IOException, InterruptedException;
/**
* 获取存储该分片的数据所在的节点位置。
*/
public abstract String[] getLocations() throws IOException, InterruptedException;
}将 InputSplit 拆分成一个个 <Key,Value>对给 Map 处理,也是实际的文件读取分割对象。
CombineFileInputFormat 可以将若干个 Split 打包成一个,目的是避免过多的 Map 任务(因为 Split 的数目决定了 Map 的数目,大量的 Mapper Task 创建销毁开销将是巨大的)。
通常一个 split 就是一个Block(FileInputFormat 仅仅拆分比Block大的文件),这样做的好处使得 Map 可以存储有当前数据的节点上运行的本地的任务,而不需要通过网络进行跨节点的任务调度。
通过mapred.min.split.size, mapred.max.split.size,block.size 来控制拆分的大小。
如果mapred.min.split.size 大于 block size,则会将两个 Block 合成到一个 split,这样有部分 Block 数据需要通过网络读取。
如果mapred.max.split.size 小于 block size,则会将一个 Block 拆成多个 split,增加了 Map 任务数(Map 对 split 进行计算,且上报结果,关闭当前计算打开新的 split 均需要耗费资源)。
先获取文件在 HDFS 上的路径和 Block 信息,然后根据 splitSize 对文件进行切分( splitSize = computeSplitSize(blockSize,minSize,maxSize) ),默认 splitSize 就等于 blockSize 的默认值(64M)。
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 首先计算分片的最大和最小值。这两个值将会用来计算分片的大小
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// 拆分 splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for( FileStatus file : files ){
Path path = file.getPath();
long length = file.getLen();
if( length != 0 ){
FileSystem fs = path.getFileSystem(job.getConfiguration());
// 获取该文件所有的 Block 信息列表[hostname, offset, length]
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
// 判断文件是否可分割,通常是可分割的,但如果文件是压缩的,将不可分割
if( isSplitable(job, path) ){
long blockSize = file.getBlockSize();
// 计算分片大小,即 Math.max(minSize, Math.min(maxSize, blockSize));
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
// 循环分片:当剩余数据与分片大小比值大于 Split_Slot 时,继续分片;
// 小于等于时,停止分片。
while( ((double) bytesRemaining) / splitSize > SPLIT_SLOP ){
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
// 处理剩下的数据,不足一个 Block 大小的
if(bytesRemaining != 0){
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkLocations.length-1].getHosts()));
}
} else {
// 不可拆分成 splits,整块返回
splits.add(makeSplit(path, 0, length, blkLocation[0].getHosts()));
}
} else {
// 对于长度为 0 的文件,创建空 Hosts 列表,返回
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// 设置输入文件的数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total of Splits:" + splits.size);
return splits;
}Split 是根据文件大小分割的,而一般处理是根据分隔符进行分割的,这样势必存在一条记录横跨两个 split。

解决办法:只要不是第一个 split,都会远程读取一条记录,忽略掉第一条记录。
public class LineRecordReader extends RecordReader<LongWritable, Text> {
public static final String MAX_LINE_LENGTH = "mapreduce.input.linerecordreader.line.maxlength";
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private int maxLineLength;
private LongWritable key = null;
private Text value = null;
// initialize 函数即对 LineRecordReader 的一个初始化
// 主要是计算分片的始末位置,打开输入流以供读取 K-V对,处理经过分片压缩的情况等
public void initialize(InputSplit genericSplit, TaskAttemptContext context) throw IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.Max_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
// 打开文件,并定位到分片读取的起始位置
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
boolean skipFirstLine = false;
if(codec != null){
// 文件是压缩文件的话,直接打开文件
in = new LineReader(codec.createInputStream(fileIn),job);
end = Lone.MAX_VALUE;
} else {
// 只要不是第一个 split,则忽略本 split 的第一行数据
if(start != 0){
skipFirstLine = true;
--start;
// 定位到偏移位置,下面的读取就会从偏移位置开始
fileIn.seek(start);
}
in = new LineReader(fileIn, job);
}
if(skipFirstLine) {
// 忽略第一行数据,重新定位 start
start += in.readLine(new Text(), 0, (int)Math.min((long) Integer.MAX_VALUE, end-start));
}
this.pos = start;
}
public boolean nextKeyValue() throws IOException {
if(key == null) {
key = new LongWritable();
}
// key 即为偏移量
key.set(pos);
if(value == null){
value = new Text();
}
int newSize = 0;
while(pos < end){
newSize = in.readLine(value, maxLineLength, Math.max((int) Math.min(Integer.MAX_VALUE, end-pos), maxLineLength));
// 读取数据长度为 0,则说明已经读完
if(newSize == 0){
break;
}
pos += newSize;
// 读取的数据长度小于最大行长度,也说明已经读取完毕
if(newSize < maxLineLength){
break;
}
// 执行到此处,说明改行数据没读完,继续读入
}
if(newSize == 0){
key = null;
value = null;
return false;
} else {
return true;
}
}
}主要是读取InputSplit 的每一个Key-Value对,并进行处理。
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* 预处理,仅在 map task 启动时运行一次
*/
protected void setup(Context context) throws IOException, InterruptedException{
}
/**
* 对于InputSplit中的每一对<key, value>都会运行一次
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* 扫尾工作,比如关闭流等
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
}
/**
* map task的驱动器
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
public class MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends TaskInputOutputContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
private RecordReader<KEYIN, VALUEIN> reader;
private InputSplit split;
/**
* Get the input split for this map.
*/
public InputSplit getInputSplit() {
return split;
}
@Override
public KEYIN getCurrentKey() throws IOException, InterruptedException {
return reader.getCurrentKey();
}
@Override
public VALUEIN getCurrentValue() throws IOException, InterruptedException {
return reader.getCurrentValue();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
return reader.nextKeyValue();
}
}对 Map 的结果进行排序并传输到 Reduce 进行处理。Map 的结果并不直接存放到硬盘,而是利用缓存做一些预排序处理。Map 会调用 Combiner 进行压缩,按 Key 进行分区、排序等,尽量减少结果的大小。每个 Map 完成后都会通知 Task,然后 Reduce 就可以进行处理。
io.sort.mb 的值mapred.inmem.merge.threshold 设置为 0,mapred.job.reduce.input.buffer.percent 设成 1.0。io.file.buffer.size,默认4kb)。| 属性 | 默认值 | 描述 |
|---|---|---|
| io.sort.mb | 100 | 映射输出分类时所使用缓冲区的大小. |
| io.sort.record.percent | 0.05 | 剩余空间用于映射输出自身记录.在1.X发布后去除此属性.随机代码用于使用映射所有内存并记录信息. |
| io.sort.spill.percent | 0.80 | 针对映射输出内存缓冲和记录索引的阈值使用比例. |
| io.sort.factor | 10 | 文件分类时合并流的最大数量。此属性也用于reduce。通常把数字设为100. |
| min.num.spills.for.combine | 3 | 组合运行所需最小溢出文件数目. |
| mapred.compress.map.output | false | 压缩映射输出. |
| mapred.map.output.compression.codec | DefaultCodec | 映射输出所需的压缩解编码器. |
| mapred.reduce.parallel.copies | 5 | 用于向reducer传送映射输出的线程数目. |
| mapred.reduce.copy.backoff | 300 | 时间的最大数量,以秒为单位,这段时间内若reducer失败则会反复尝试传输 |
| io.sort.factor | 10 | 组合运行所需最大溢出文件数目. |
| mapred.job.shuffle.input.buffer.percent | 0.70 | 随机复制阶段映射输出缓冲器的堆栈大小比例 |
| mapred.job.shuffle.merge.percent | 0.66 | 用于启动合并输出进程和磁盘传输的映射输出缓冲器的阀值使用比例 |
| mapred.inmem.merge.threshold | 1000 | 用于启动合并输出和磁盘传输进程的映射输出的阀值数目。小于等于0意味着没有门槛,而溢出行为由 mapred.job.shuffle.merge.percent单独管理. |
| mapred.job.reduce.input.buffer.percent | 0.0 | 用于减少内存映射输出的堆栈大小比例,内存中映射大小不得超出此值。若reducer需要较少内存则可以提高该值. |
第一种:指定依赖可以利用Public Cache
export LIBJARS=$MYLIB/commons-lang-2.3.jar, hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.aspress.prohadoop.c3. WordCountUsingToolRunner -libjars $LIBJARS第二种:包含依赖,则每次都需要拷贝
hadoop jar prohadoop-0.0.1-SNAPSHOT-jar-with-dependencies.jar org.aspress.prohadoop.c3. WordCountUsingToolRunner The dependent libraries are now included inside the application JAR file重点:压缩和拆分一般是冲突的(压缩后的文件的 Block 是不能很好地拆分独立运行,很多时候某个文件的拆分点是被拆分成两个压缩文件中,这是 Map 任务就无法处理,所以对于这些压缩,Hadoop 往往是直接使用一个 Map 任务处理整个文件的分析。Map 的输出结果也可以进行压缩,这样可以减少 Map 结果到 Reduce 的传输的数据量,加快传输速率
单节点安装
所有服务都运行在一个 JVM 中,适合调试、单元测试
伪集群
所有服务运行在一台机器中,每个服务都在独立的 JVM 中,适合做简单、抽样测试
多节点集群
服务运行在不同的机器中,适合生产环境
方便主从服务器进行无密钥通信,主要使用公钥/私钥机制。
ssh-keygen -t rsa 生成密钥对。xxx-default.xml:只读,默认的配置xxx-site.xml:替换 default 中的配置
core-site.xml:配置公共属性hdfs-site.xml:配置HDFSyarn-site.xml:配置YARNmapred-site.xml:配置MapReducexxx-site.xml中的配置xxx-site.xml 中的配置xxx-default.xml 中的配置如果某个属性不想被覆盖,可以将其设置为 final
<property>
<name>{PROPERTY_NAME}</name>
<value>{PROPERTY_VALUE}</value>
<final>true</final>
</property>标签:diff too record require sid nal eve 总结 并发
原文地址:https://www.cnblogs.com/jianminglin/p/11437597.html