标签:并行 应用 并行执行 stop lis 连续 sso compact make
背景:由于CMS算法产生空间碎片和其它一系列的问题缺陷,HotSpot提供了另外一种垃圾回收策略,G1(也就是Garbage First)算法,该算法在JDK7u4版本被正式推出,官网对此描述如下:
G1 is planned as the long term replacement for the Concurrent Mark-Sweep Collector (CMS). Comparing G1 with CMS, there are differences that make G1 a better solution. One difference is that G1 is a compacting collector. G1 compacts sufficiently to completely avoid the use of fine-grained free lists for allocation, and instead relies on regions. This considerably simplifies parts of the collector, and mostly eliminates potential fragmentation issues. Also, G1 offers more predictable garbage collection pauses than the CMS collector, and allows users to specify desired pause targets.
G1 Collector 是一种server风格的垃圾回收器,针对具有大内存、多cpu的机器。它在满足高吞吐量的同时,又尽可能的实现较低的GC时间,G1 Collector 主要针对以下场景:
对于之前的garbage collectors来说(比如最早的serial、后来的parallel、CMS),它们都将堆划分成了三个部分:新生代,老年代,永久代(元空间)
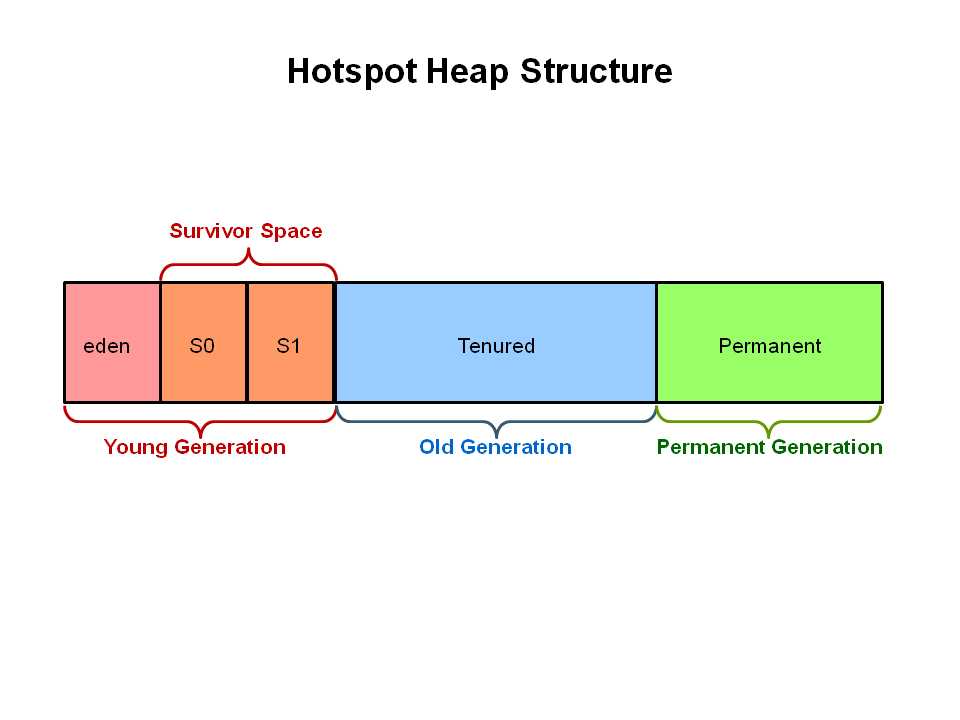
G1不同,G1算法将堆划分为若干个Region,它仍然是划分代的。并且默认情况下是将堆内存划分2048份,每个region的大小也就是heap size/2048,但是region的大小只能为1M、2M、4M、8M、16M和32M,总之是2的幂次方,一般会生成2000左右个region


如上图所示,这些region被定义为eden、survivor、old generation 逻辑上为连续的内存空间。其中eden、survivor、old generation跟以往的GC收集器一样,此外还有一个Humongous区是以往算法所没有的, 如果一个对象占用的空间超过了区域容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
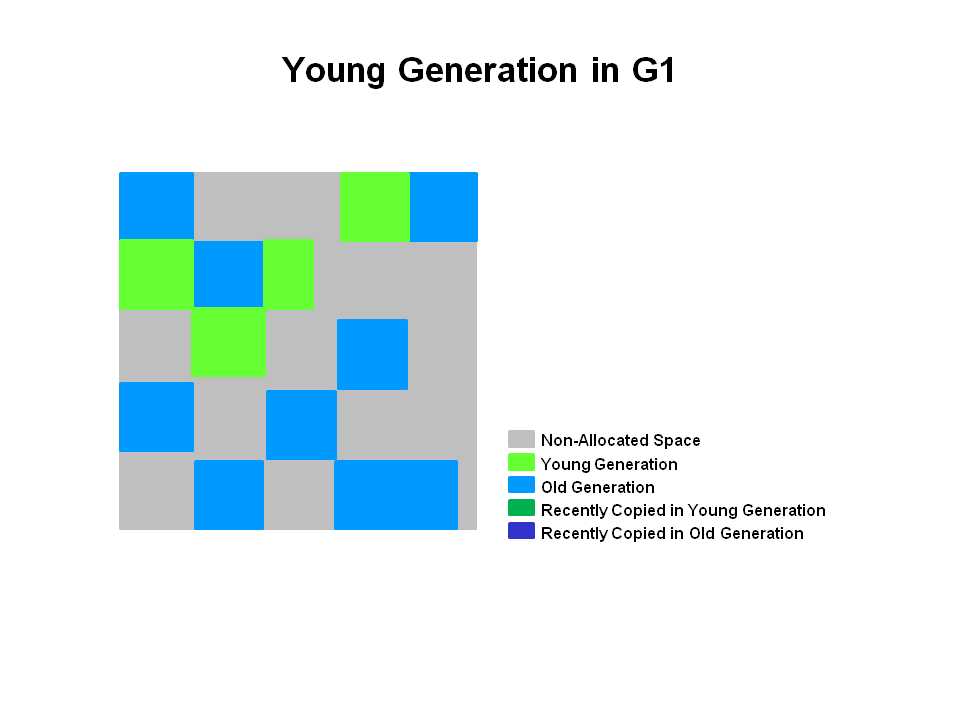
存活的对象被拷贝到一个或多个survivor region中,如果某些对象的age达到了晋升老年代要求的阀值,就会晋升到老年代。(跟之前的算法差不多),G1 young gc属于stop the world (STW)性质,并且在此期间,eden region的数量和survivor region的数量会通过新一轮的计算(也就是region的数量是在动态变化的),以适应下一轮的GC更好的达到期望的暂停时间。

存活的对象被疏散到survivor region中或者old generation region,晋升的对象由下图中暗色部分表示,蓝色的代表Survivor regions
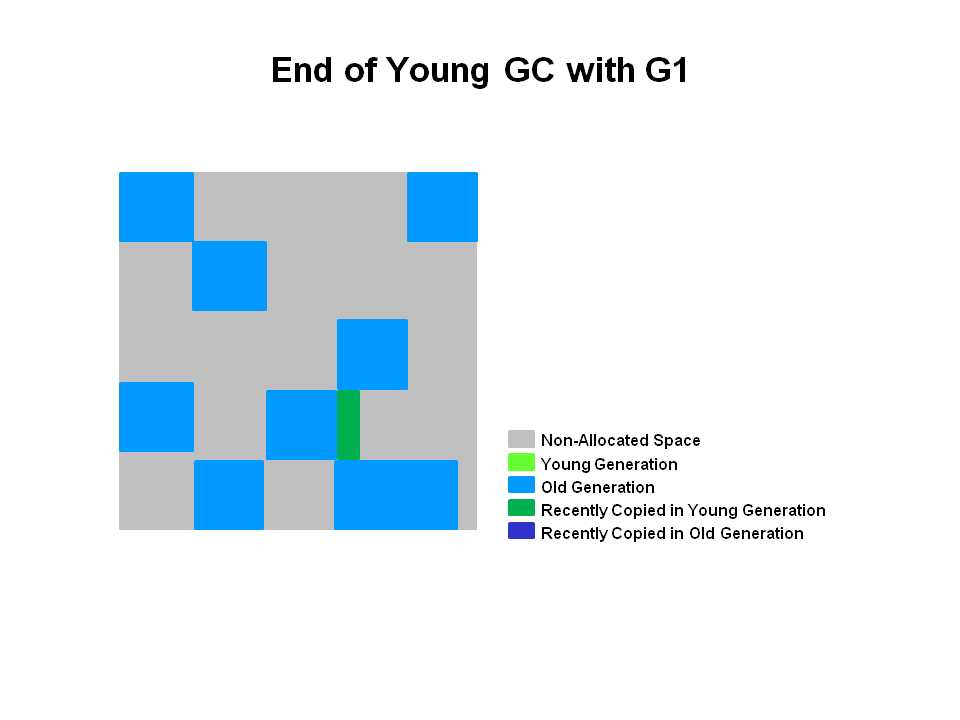
当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,会触发Old Generation Collection(也可称为mixed gc),G1的old gc跟以前算法的old gc不太一样,G1 old gc是在回收整个young region的同时,还会回收一部分的old region,这里需要注意,是一部分old region,而不是全部,G1算法选择部分old region进行回收,从而可以对垃圾回收的耗时时间进行控制。触发条件:-XX:InitiatingHeapOccupancyPercent=n 当老年代大小占整个堆大小百分比达到该阈值时,会触发一次old gc
old gc执行流程:
1. initial mark: 整个过程STW,标记了从GC Root可达的对象
2. concurrent marking: 并发标记过程,整个过程gc collector线程与应用线程并行执行,找出整个堆中的存活对象
3. remark: 整个过程STW,最终标记,使用snapshot-at-the-beginning (SATB)算法(much faster than CMS use)标记出那些在并发标记过程中遗漏的,
或者内部引用发生变化的对象
4. clean up: 该过程部分是STW处理,部分是并行处理
1.统计存活对象和完全空闲的region(STW)
2.清空Remembered Sets(STW)
3.将空region加入到空闲列表中(并发)
5.Copying:整个过程STW,拷贝存活对象到新的region中
标签:并行 应用 并行执行 stop lis 连续 sso compact make
原文地址:https://www.cnblogs.com/dtmobile-ksw/p/11421019.html