标签:绘制 电商 优化 机器学习库 适合 搜索引擎 工程 inf 依据
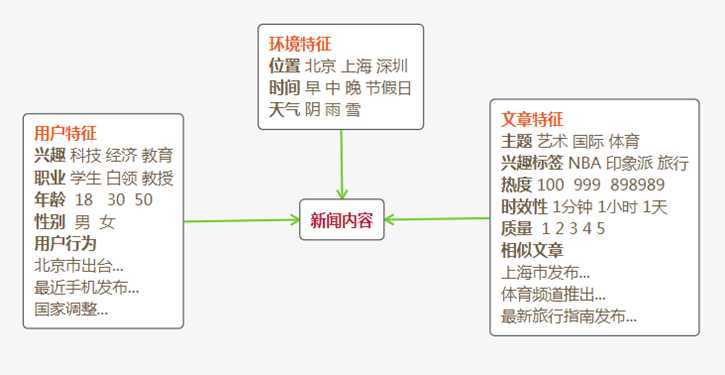
新闻推荐系统解决的是咨询、用户和环境之间的关系,如图,通过对用户特征、环境特征、文章特征做综合分析,将最合适、有效的内容推荐给用户。
正所谓巧妇难为无米之炊,不光新闻推荐系统,几乎所有人工智能模型都离不开大数据组件的支持。
要做到一个“千人千面的推荐系统“,需要大数据的支持,可能涉及的大数据组件如spark、Hadoop,支持组件ES、Kafka等,不做具体分析,各有好坏,需要再实际业务环境中选择使用,不用最好的,但要最适合的。
推荐系统在整个系统中的粗略定位如下。
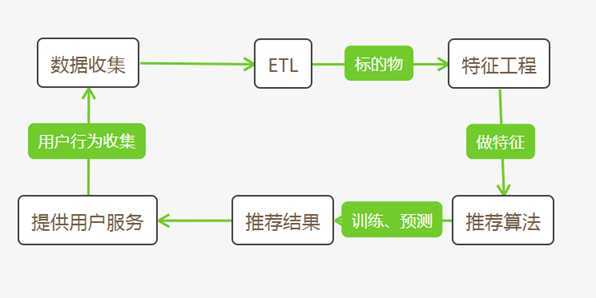
系统是个闭环,从数据收集启动,通过ETL做标的物处理,经特征工程做特征后,交由推荐算法处理训练、预测,生成推荐结果,推荐结果提交给用户后收集用户反馈,并以此作为数据不断优化更新模型。如图。
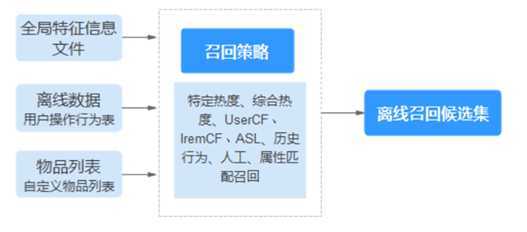
处理好特征,有助于推荐的精准度,特征一般包含相关性特征,环境变量特征,热度特征,协同特征。依据具体业务逻辑特征选取使用。

针对生成结果如何召回、排序也是一个需要考虑的问题,个人建议执行多路召回,避免了单一算法的局限性,有效解决产生推荐范围越来越单调的问题。
具体通过对不同路线召回的权重选择,时间衰减降权,惩罚热点等完成。
新闻推荐的特点,注定需要NLP的炼金石。
用户兴趣:为喜欢【游戏】相关文章的用户打上【游戏】标签。
内容推荐:把喜欢【电影】相关推荐给喜欢【电影】的用户。
频道生成:把【财经】文章归类到【财经频道】。
新闻资讯类产品的特殊性,注定了对内容实时性的需求,导致对历史数据消费不足,没有文本特征冷启动困难。
一般人为使用分类、实体词、关键字等显式特征,部分使用隐式特征(如LSA)。
细粒度启动能力强,如:【故宫旅行攻略】与【北京旅行攻略】。
无文本特征,搜索引擎无法工作。
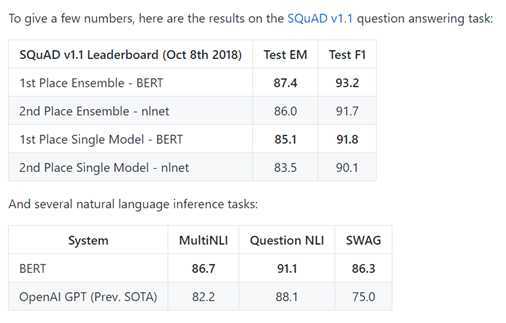
个人推荐bert,bert在问答系统、情感分析、命名实体识别、垃圾邮件过滤、文档聚类等方面成绩显著,这些对新闻推荐工作都是有帮助的。
新闻推荐主要需要:关键字获取、主题抓取、后续的垃圾新闻过滤等。
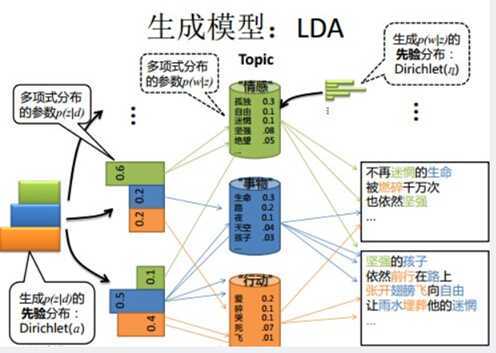
此外,LDA主题生成模型在做基于物品相似推荐上效果不错,可以考虑使用
本文重点是基于协同过滤的推荐系统,其他算法不做比较、解释。

协同过滤又可以分为基于用户的协同过滤,基于物品的协同过滤,使用场景须自行分析,会在后面做两种比较。
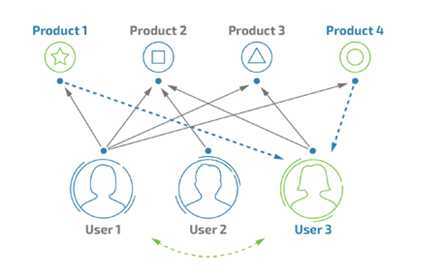
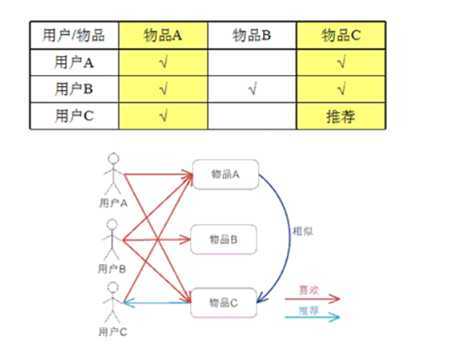
分析:电商等以物品为主的应用场景。
特点:用户数大于物品数,通过分析物品推荐用户。
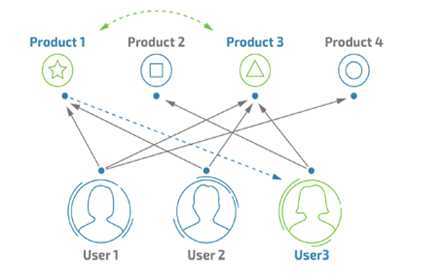
应用场景:新闻等以内容为主的平台
特点分析:内容量远大于用户数,通过分析用户推荐内容。
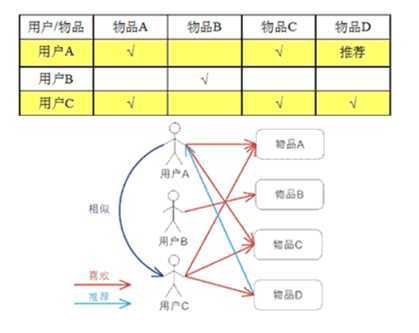
基于用户的协同过滤需对用户有一点的了解,如果深入分析,可以考虑生成人物画像。
人口属性——用户是谁(性别,年龄等)。
兴趣偏好——个人爱好、品牌偏好等。
社交属性——社交活跃度。
消费属性——消费需求、消费习惯。

介绍完以上信息,做个总结。协同过滤归根结底,是一个计算用户、物品与其他用户、物品相似的一个过程,为相似的用户、物品推荐与之相关的内容。
对于这个“相似”,一般使用一下几种方法计算
欧几里德距离:
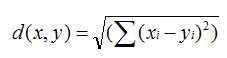
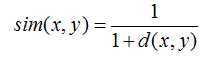
皮尔逊相关系数:
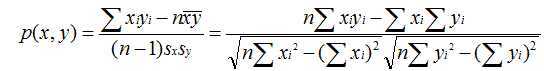
cosine相关度:
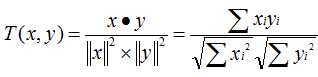
此处对两种推荐算法做个对比分析,不做其他相关赘述。
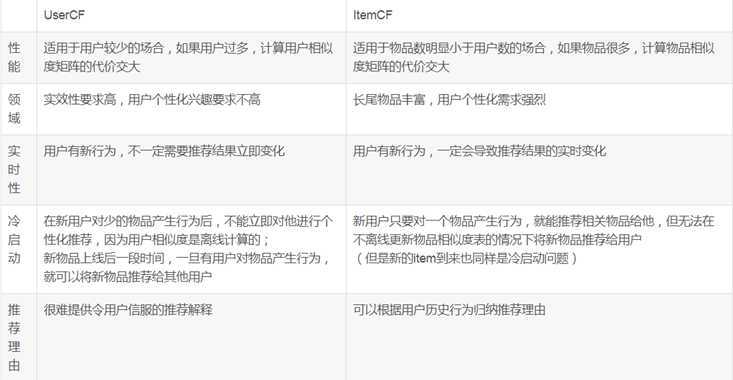
SparkMl: Mahout:
语言:Scala、Python、Java 语言:Java
定位:Spark里的机器学习库 定位:Java库
领域:常规的机器学习算法如CF、特征工程、数据处理。 领域:CF、集群、分类
这里个人推荐使用sparkMl,因为开发文档等全面,便于参考,且更成熟。
推荐系统架构的改进,召回模型改进,推荐特征增加,算法参数优化等。
一个系统搭建成功,很重要的一点是,不光看他能不能用,还要看他的实用效果如何,并不管改进。
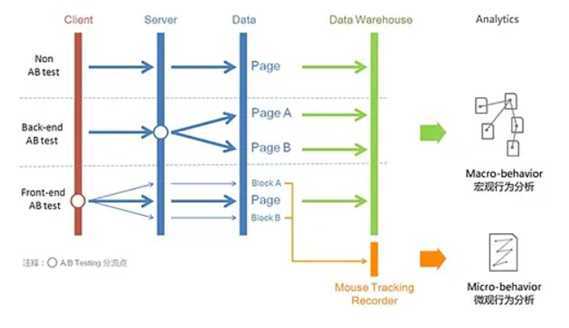
需要注意:兼顾长期与短期指标,注意协同效益的影响,必要时隔离统计。
如同推荐系统的闭环工作一样,A/B test也是一个闭环的工作流程。通过测试分析数据,提出改进想法加入测试,有效产品化使用,无效吸取经验。
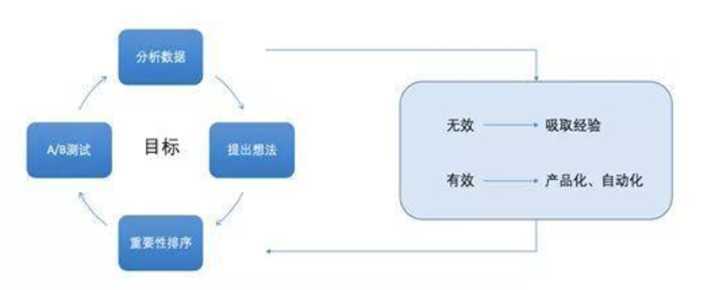
通俗的讲,遵循单一变量原则,明确自身期待目标,然后控制完成目标的单一变量,执行灰度测试,通过实施反馈修正方案。
一个新闻推荐系统在推荐的同时也需要对新闻内容进行审核,对一些低质量内容采取过滤不推荐策略,保证推荐新闻的高效且有用。需注意如一下几点:
推荐信息低质过滤(如被用户标记质量差)。
违法违规内容过滤。
低俗内容识别过滤。
标签:绘制 电商 优化 机器学习库 适合 搜索引擎 工程 inf 依据
原文地址:https://www.cnblogs.com/Hsir/p/11440983.html