标签:str 高效 保存 text 新窗口 src 效率 字体 就是
其实这个是有客户要求做的,但我完成的不够完美。过来分享出来好了~
首先,你知道抖音有一个用户分享页吧?
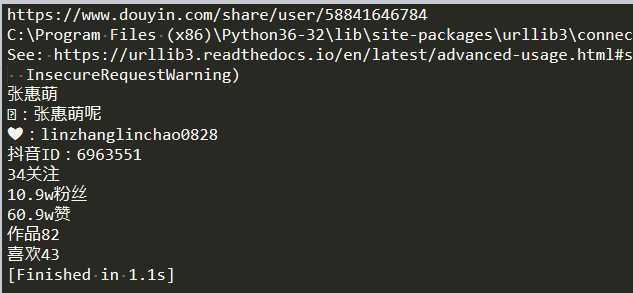
像这样的:https://www.douyin.com/share/user/58841646784
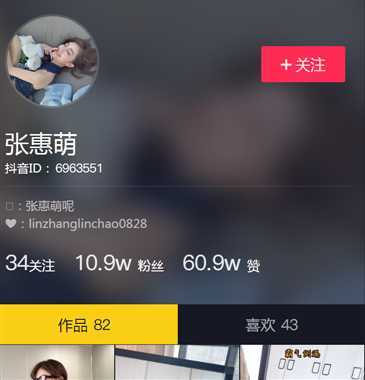
F12查看代码。
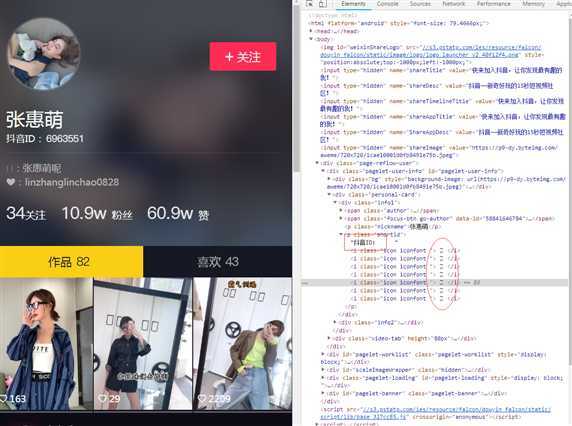
ok,可以看到有数字的地方都做了字体反爬,比如抖音id上的数字啊,粉丝数这些。
那我们这样子,先把它的这个字体文件下载下来
在开发者工具中选择Network筛选font后刷新网页就能找到这个字体了,如下图:
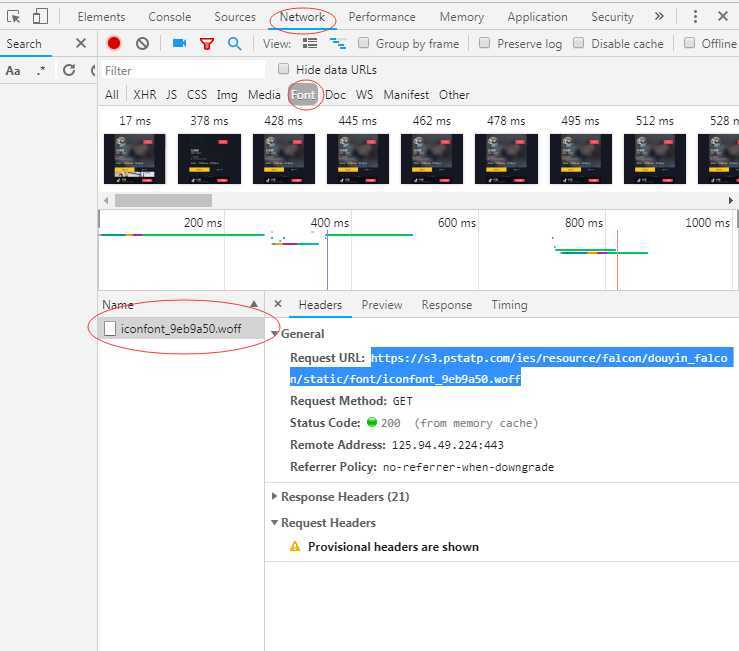
然后复制链接到新窗口打开就能下载字体了。
这是我下到的字体

下一步就是去百度网页字体编辑器
链接:http://fontstore.baidu.com/static/editor/index.html
然后选择打开,打开下载好的字体文件:
打开字体看到的效果:
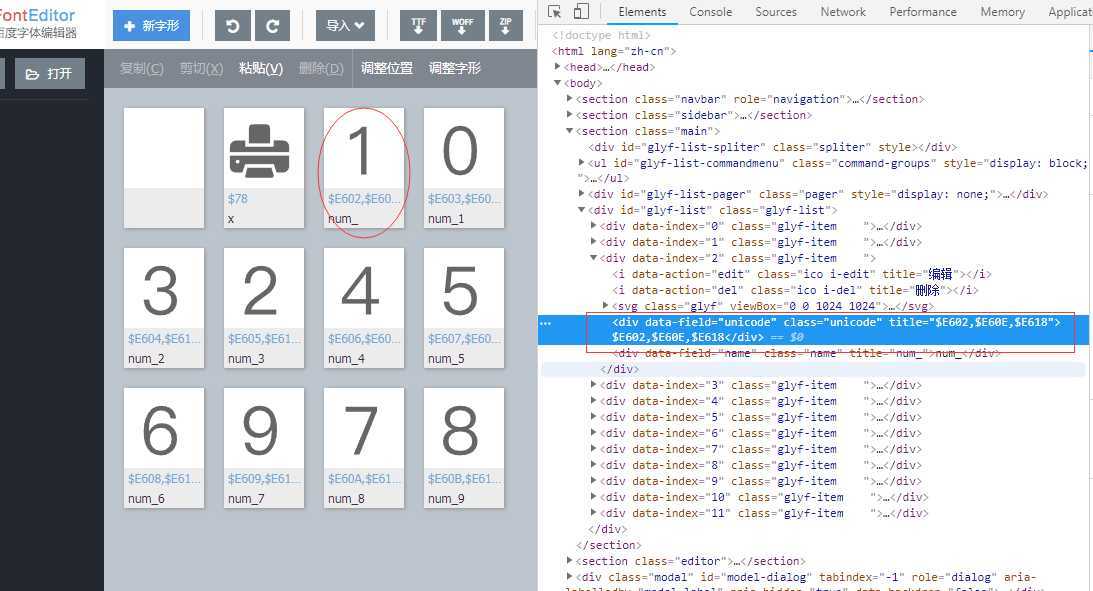
看到没,在开发者工具哪里看得到,一个数字,其实是有三个unicode编码对应的。
那我们一个个保存下来这些对应关系就好了。
这是我保存下来的:
change = {(‘\ue602‘,‘\ue60E‘,‘\ue618‘):‘1‘,(‘\ue603‘,‘\ue60d‘,‘\ue616‘):‘0‘,(‘\ue604‘,‘\ue611‘,‘\ue61a‘):‘3‘,(‘\ue605‘,‘\ue610‘,‘\ue617‘):‘2‘,(‘\ue606‘,‘\ue60c‘,‘\ue619‘):‘4‘,(‘\ue607‘,‘\ue60f‘,‘\ue61b‘):‘5‘,(‘\ue608‘,‘\ue612‘,‘\ue61f‘):‘6‘,(‘\ue609‘,‘\ue615‘,‘\ue61e‘):‘9‘,(‘\ue60a‘,‘\ue613‘,‘\ue61c‘):‘7‘,(‘\ue60b‘,‘\ue614‘,‘\ue61d‘):‘8‘}
ok,其实这个并不麻烦。麻烦的是怎么去获取链接后面那个id
分享链接的id获取的话我是抓客户端数据包拿到的,键是‘uid‘。
如果你有高效率的获取这个id的方法,欢迎过来分享,让我付费也行哦~
分享页爬取的完整代码:
import requests from bs4 import BeautifulSoup as bs id = ‘86560737726‘ change = {(‘\ue602‘,‘\ue60E‘,‘\ue618‘):‘1‘,(‘\ue603‘,‘\ue60d‘,‘\ue616‘):‘0‘,(‘\ue604‘,‘\ue611‘,‘\ue61a‘):‘3‘,(‘\ue605‘,‘\ue610‘,‘\ue617‘):‘2‘,(‘\ue606‘,‘\ue60c‘,‘\ue619‘):‘4‘,(‘\ue607‘,‘\ue60f‘,‘\ue61b‘):‘5‘,(‘\ue608‘,‘\ue612‘,‘\ue61f‘):‘6‘,(‘\ue609‘,‘\ue615‘,‘\ue61e‘):‘9‘,(‘\ue60a‘,‘\ue613‘,‘\ue61c‘):‘7‘,(‘\ue60b‘,‘\ue614‘,‘\ue61d‘):‘8‘} #将爬到的单个unicode编码放到这个函数会返回对应的数字 def change_2_num(code): for i in change: try: if code.split()[0] in i: return change[i] except: print(‘函数change_2_num出错‘,code.split()) return code #请求链接,返回soup对象 def get_html(id): url = ‘https://www.douyin.com/share/user/‘+id print(url) headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"} r = requests.get(url,headers=headers,verify=False) if not len(r.text)>10000: return soup = bs(r.text,‘lxml‘) return soup def get_num(name,attrs): fin = ‘‘ res = soup.find_all(name=name,attrs={‘class‘:attrs}) if res: mid = res[0].text.split() #将获取的文本以空格切成列表,不切的话因为空格的存在会返回‘‘而不是uincode编码 else: return for code in mid: fin+=change_2_num(code) #遍历文本内容,如果是unicode编码则返回对应数字 print(fin) return fin soup = ‘‘ def main(): global soup soup = get_html(id) if not soup: return try: nickname = soup.find(name=‘p‘,attrs={‘class‘:‘nickname‘}).string print(nickname ) signature = soup.find(name=‘p‘,attrs={‘class‘:‘signature‘}).string print(signature) dyID = get_num(‘p‘,"shortid").replace(‘抖音ID:‘,‘‘) focus = get_num(‘span‘,"focus").replace(‘关注‘,‘‘) follower = get_num(‘span‘,"follower").replace(‘粉丝‘,‘‘) liked = get_num(‘span‘,"liked-num").replace(‘赞‘,‘‘) works = get_num(‘div‘,"user-tab").replace(‘作品‘,‘‘) like = get_num(‘div‘,"like-tab").replace(‘喜欢‘,‘‘) except: return main()
The end--
标签:str 高效 保存 text 新窗口 src 效率 字体 就是
原文地址:https://www.cnblogs.com/byadmin/p/11441137.html