标签:leveldb btree ext 参数 操作 structure 时间 译文 received
什么是跳跃表?
SkipList在leveldb、redis以及lucence中都广为使用,是比较高效的数据结构。由于它的代码以及原理实现的简单性,更为人们所接受。我们首先看看SkipList的定义,为什么叫跳跃表?
“ Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees. ”
译文:跳跃表使用概率均衡技术而不是使用强制性均衡,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。
跳跃表的理解

从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉搜索树,我们把一些节点提取出来,作为索引。得到如下结构:
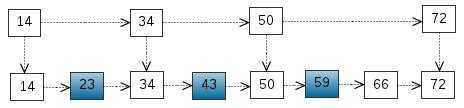
提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,三级索引…
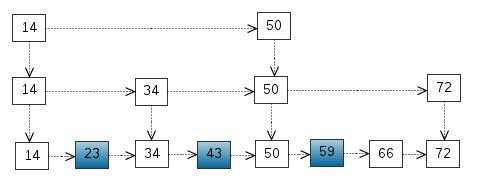
这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。
下面的结构是就是跳表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
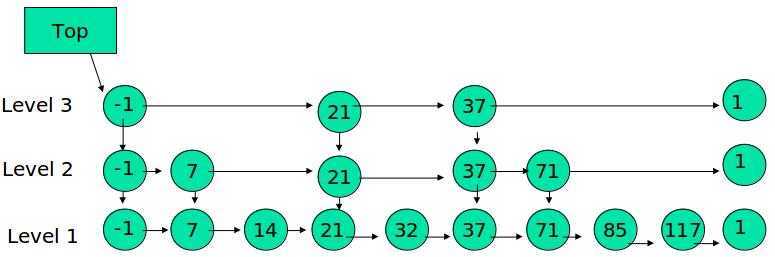
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
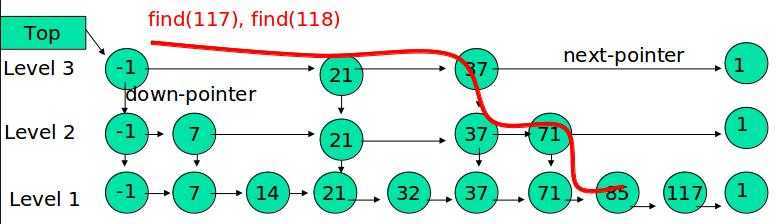
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
具体的搜索算法如下:
/* 如果存在 x, 返回 x 所在的节点, * 否则返回 x 的后继节点 */ find(x) { p = top; while (1) { while (p->next->key < x) p = p->next; if (p->down == NULL) return p->next; p = p->down; } }
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)
然后在 Level 1 … Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
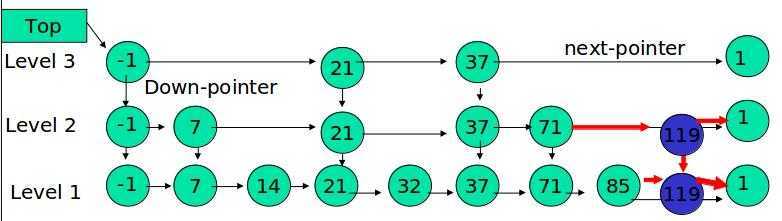
如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4
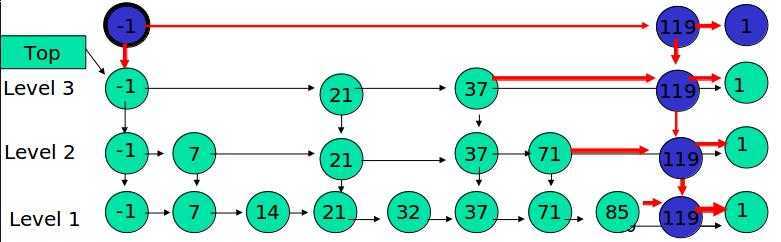
丢硬币决定 K
插入元素的时候,元素所占有的层数完全是随机的,通过一下随机算法产生:
int random_level() { K = 1; while (random(0,1)) K++; return K; }
相当与做一次丢硬币的实验,如果遇到正面,继续丢,遇到反面,则停止,
用实验中丢硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,
K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
跳表的高度。
n 个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数 K, 跳表的高度等于这 n 次实验中产生的最大 K,待续。。。
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的期望值是 2n。
跳表的删除
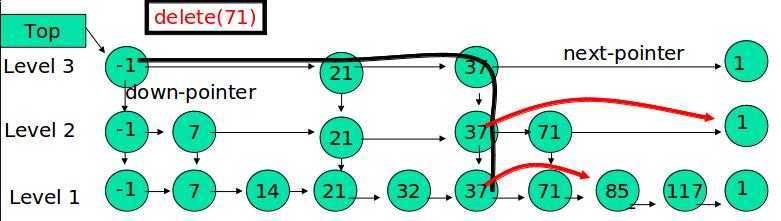
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels
will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache
locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master)
with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
资料出处:https://blog.csdn.net/u014427196/article/details/52454462
标签:leveldb btree ext 参数 操作 structure 时间 译文 received
原文地址:https://www.cnblogs.com/myseries/p/11442335.html