标签:app gen __init__ pes from init closed cli bre

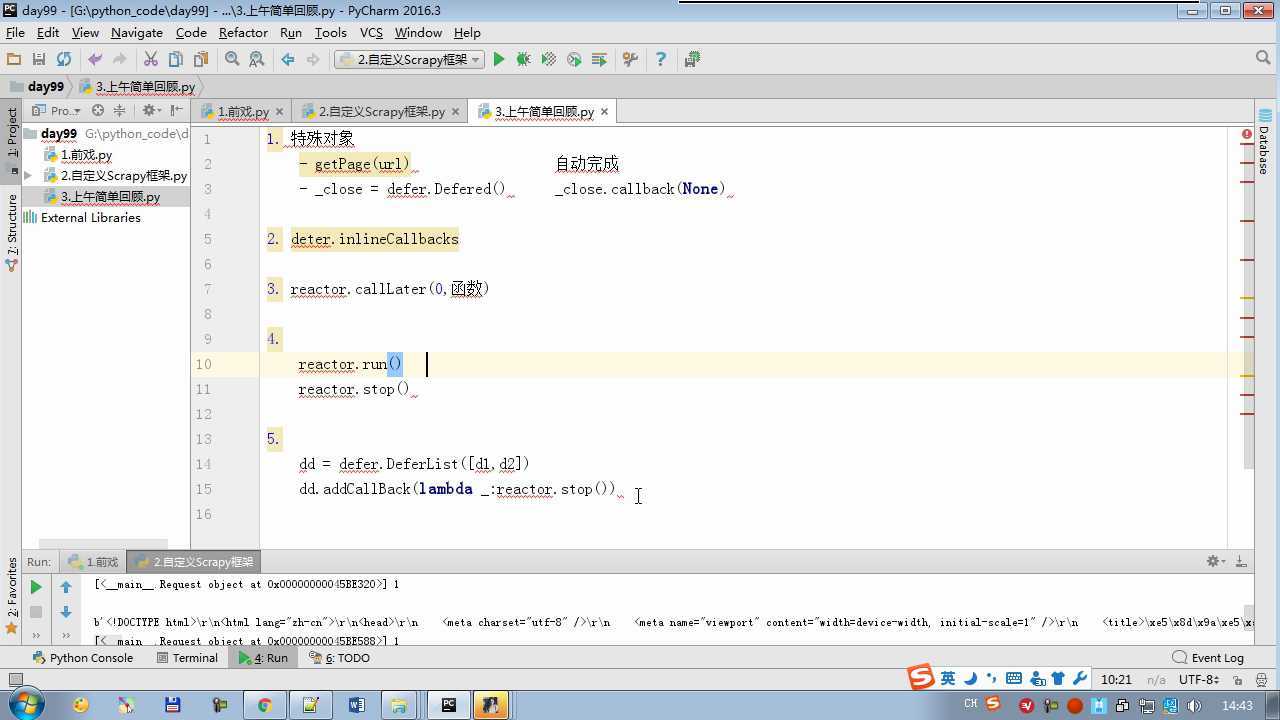
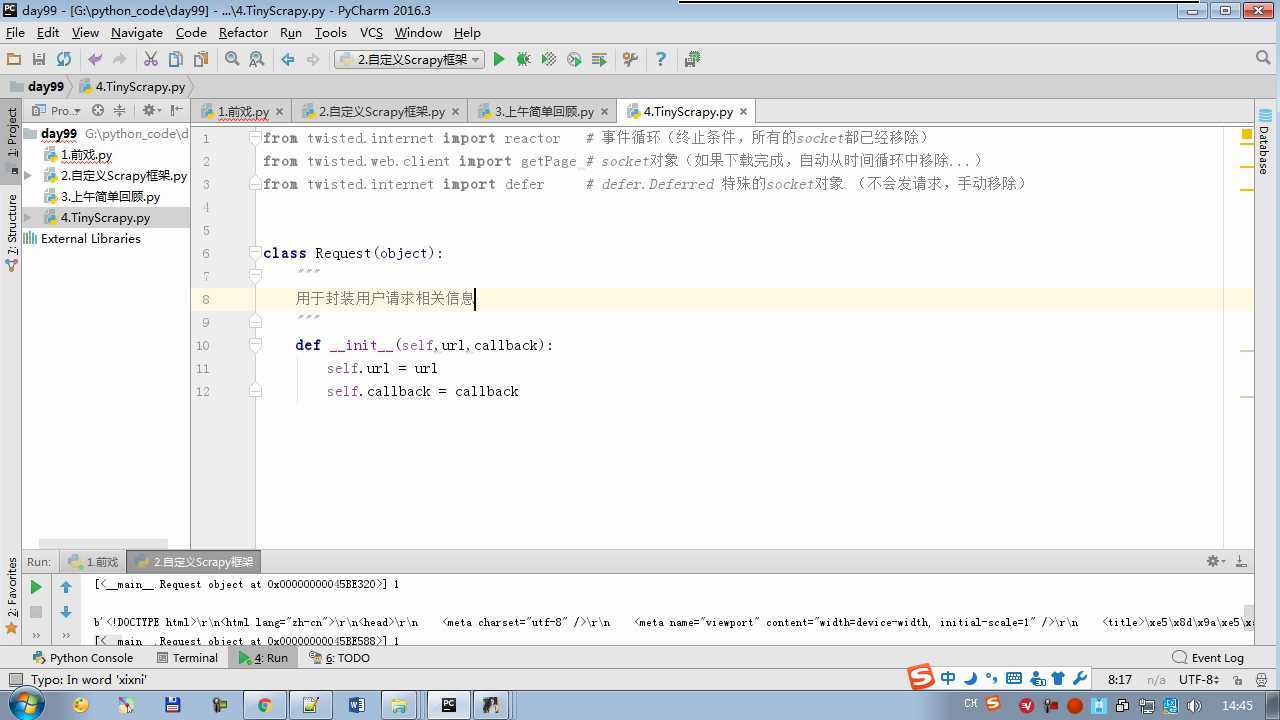
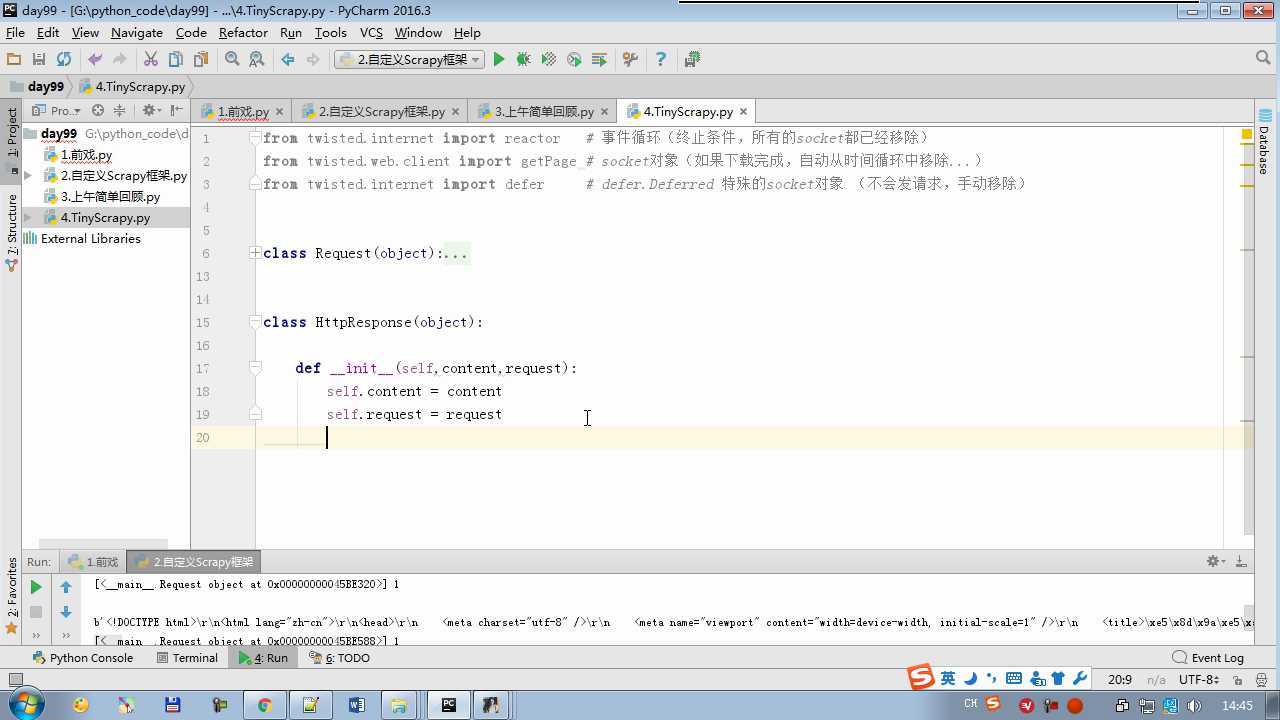
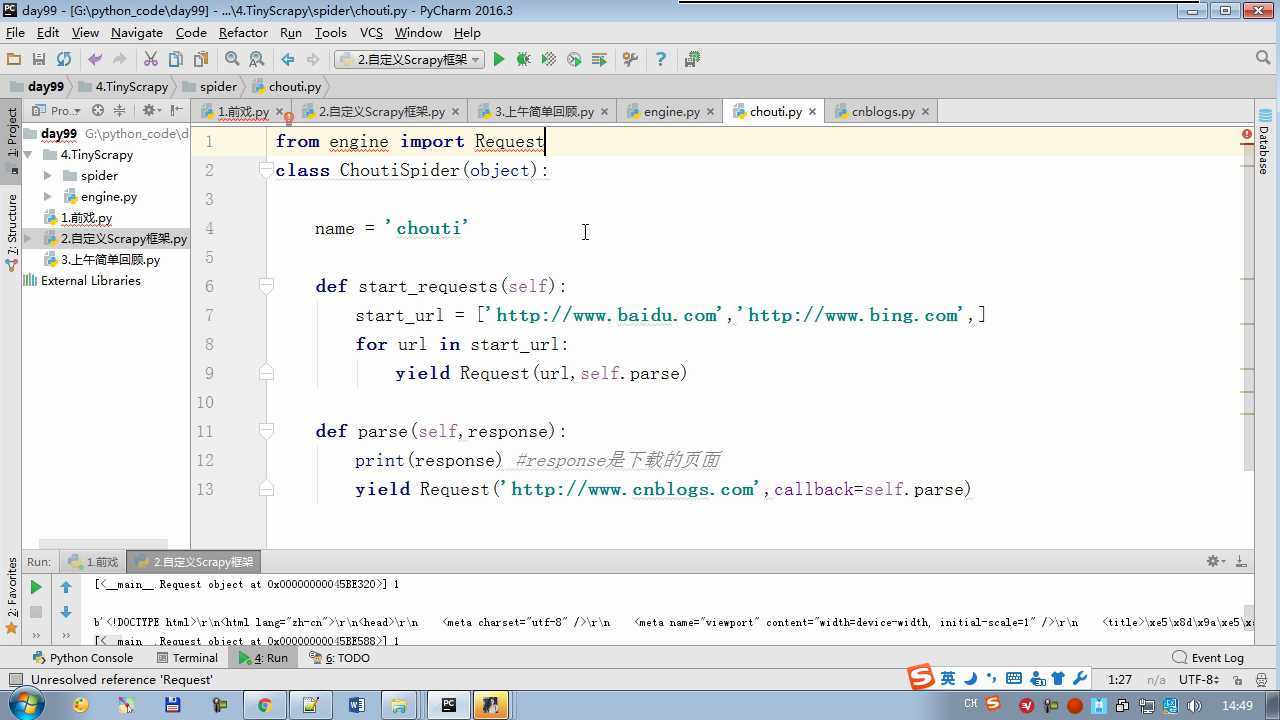
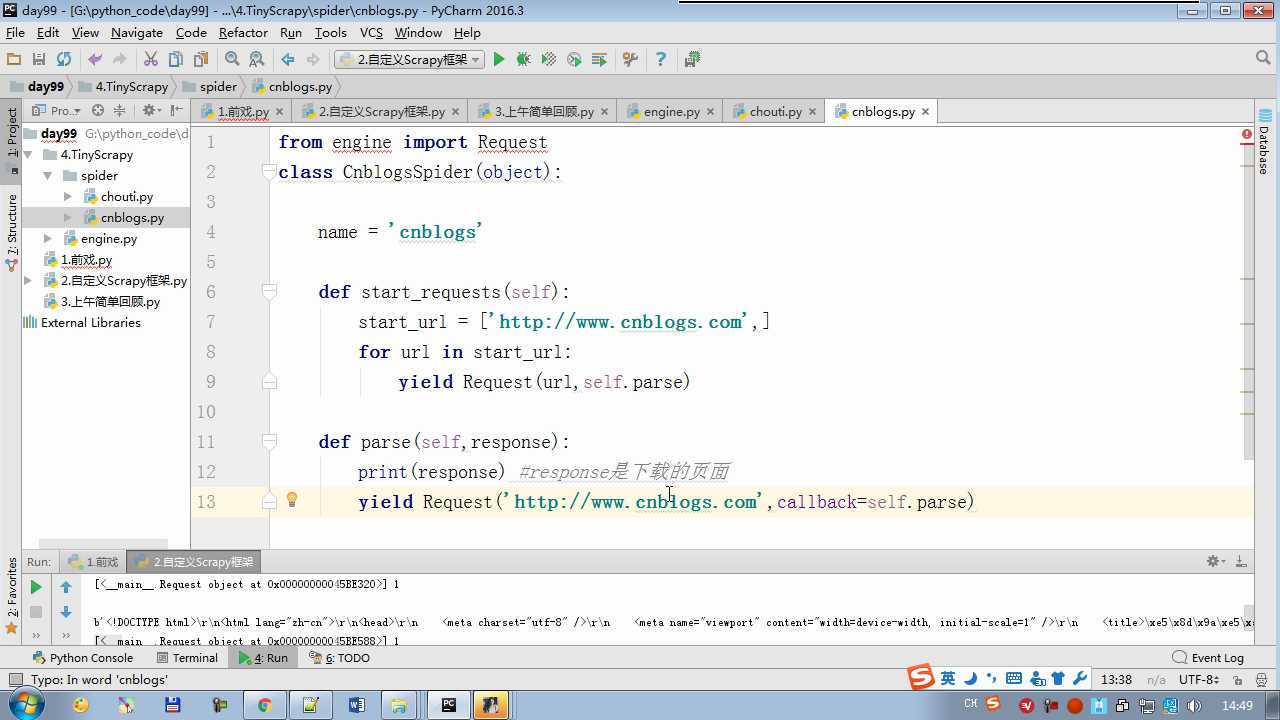
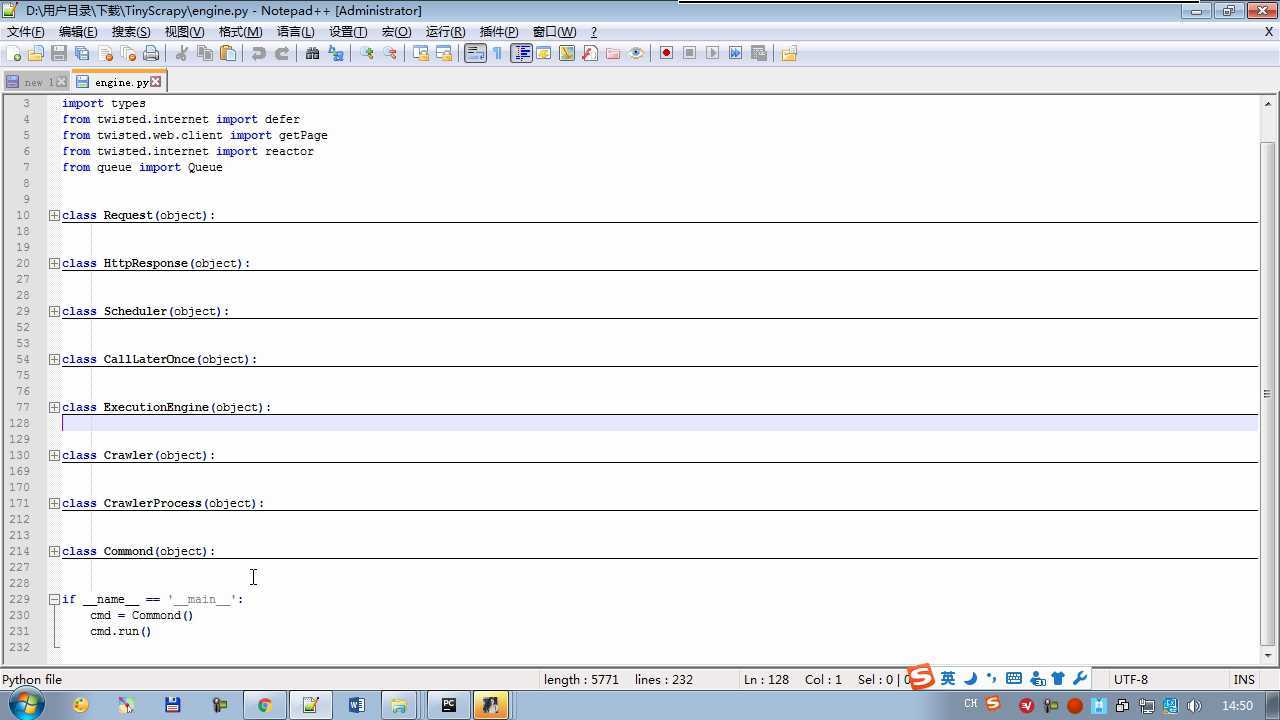
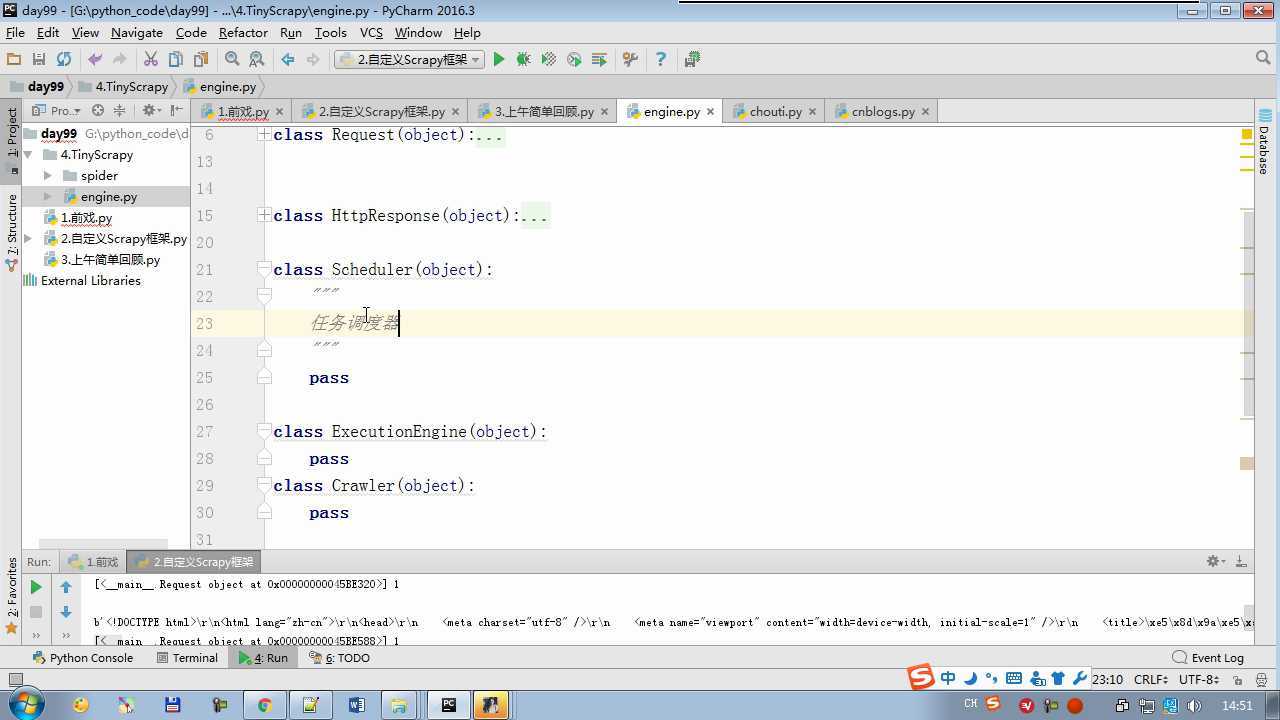
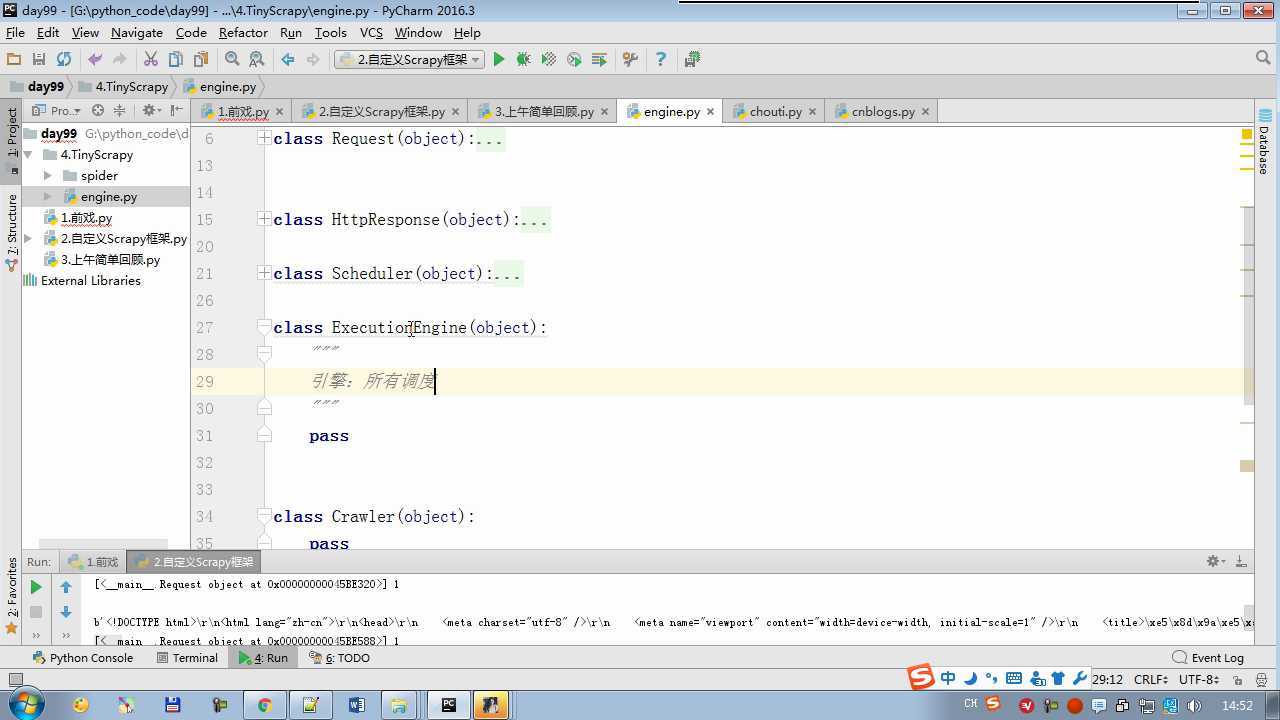
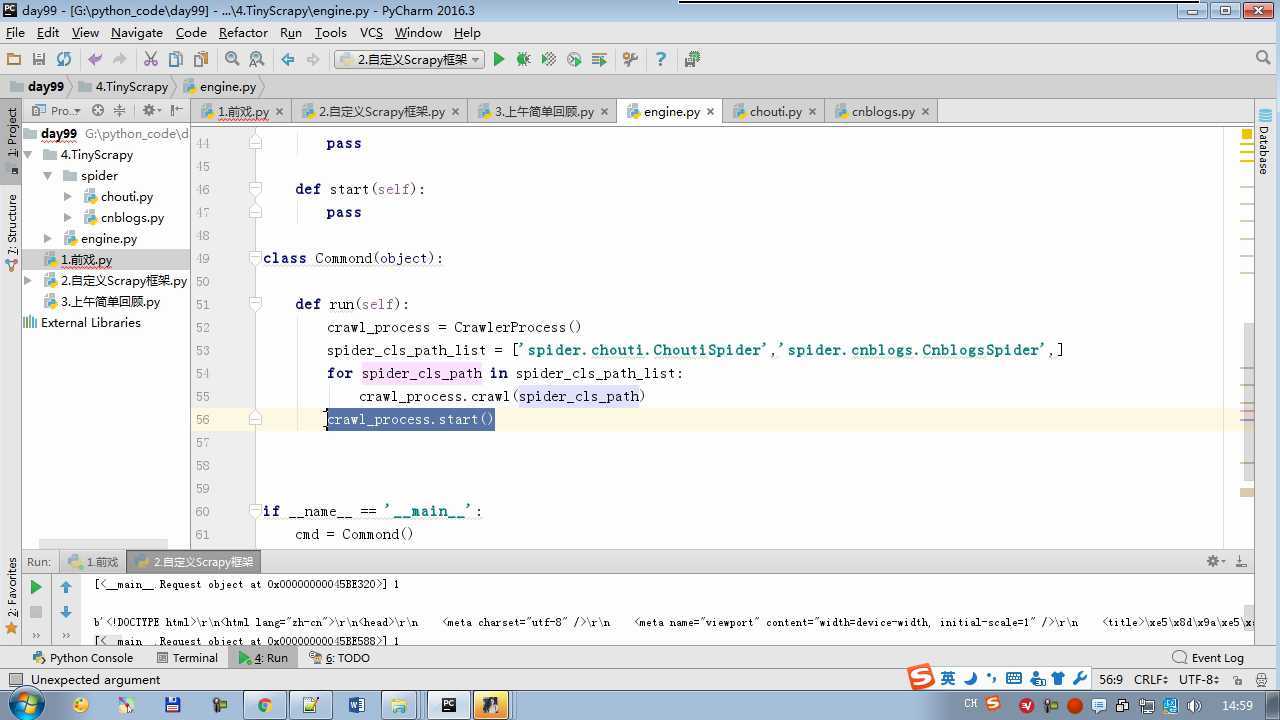
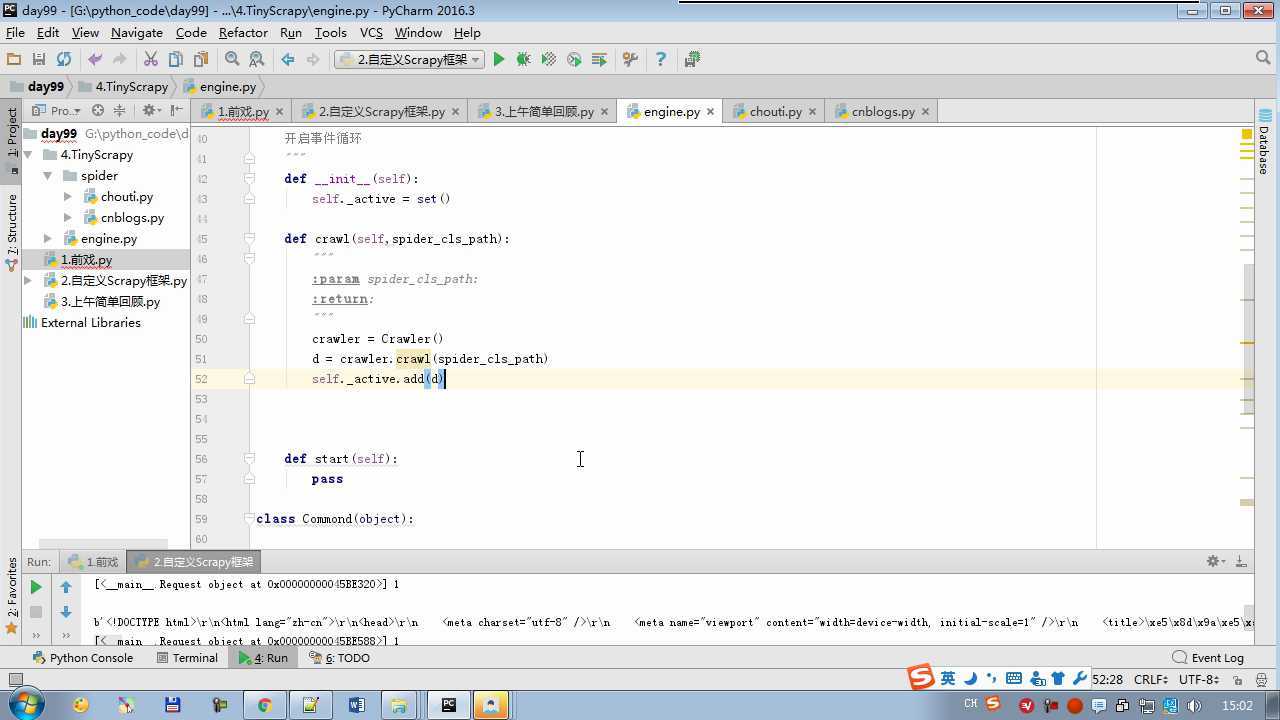
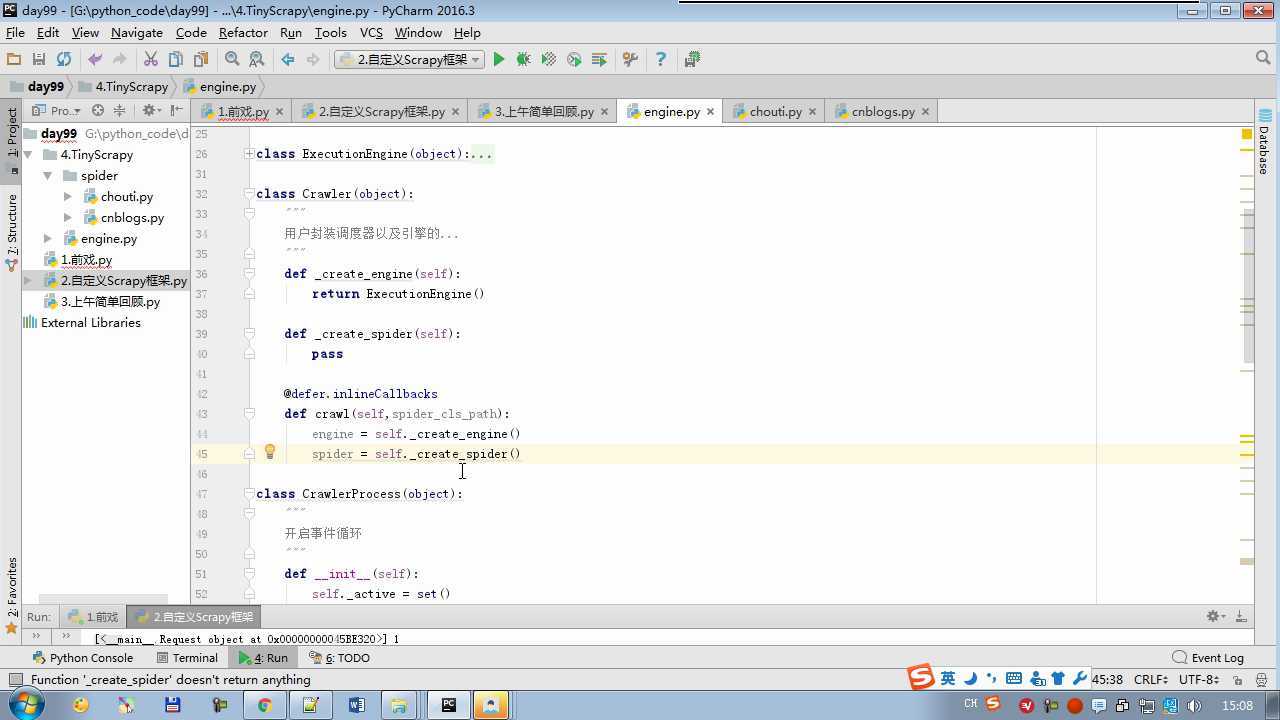
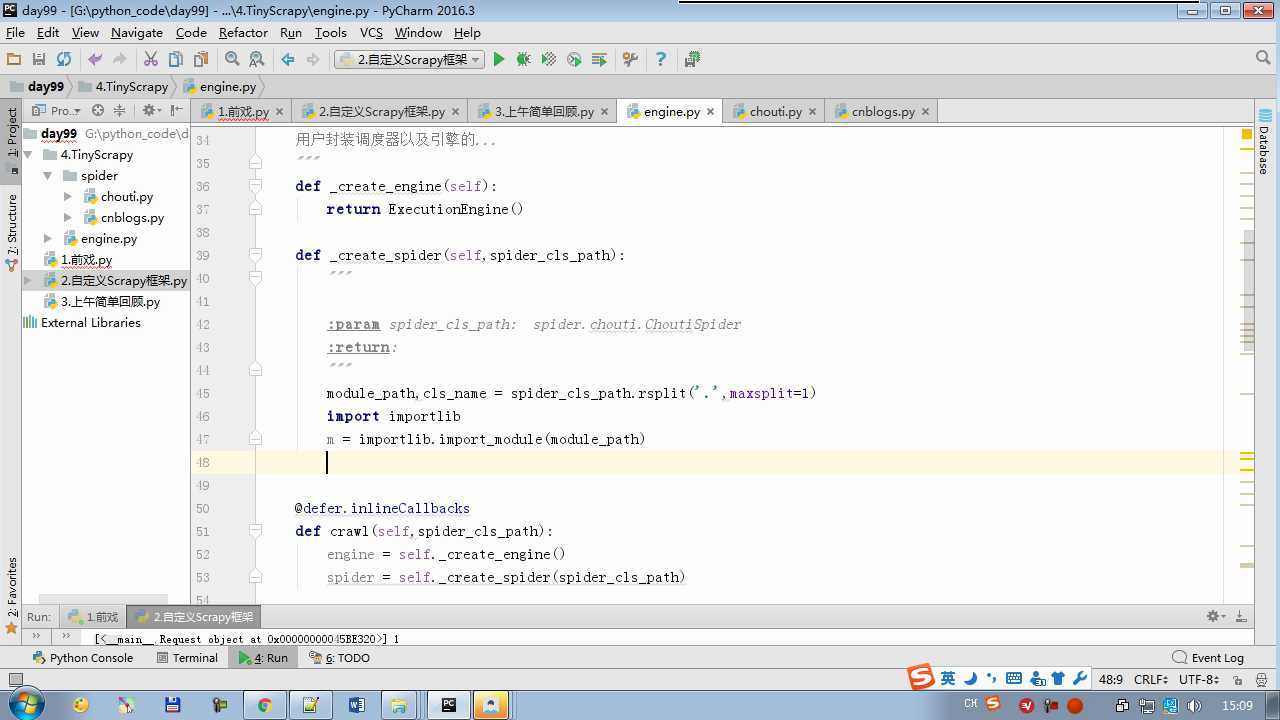
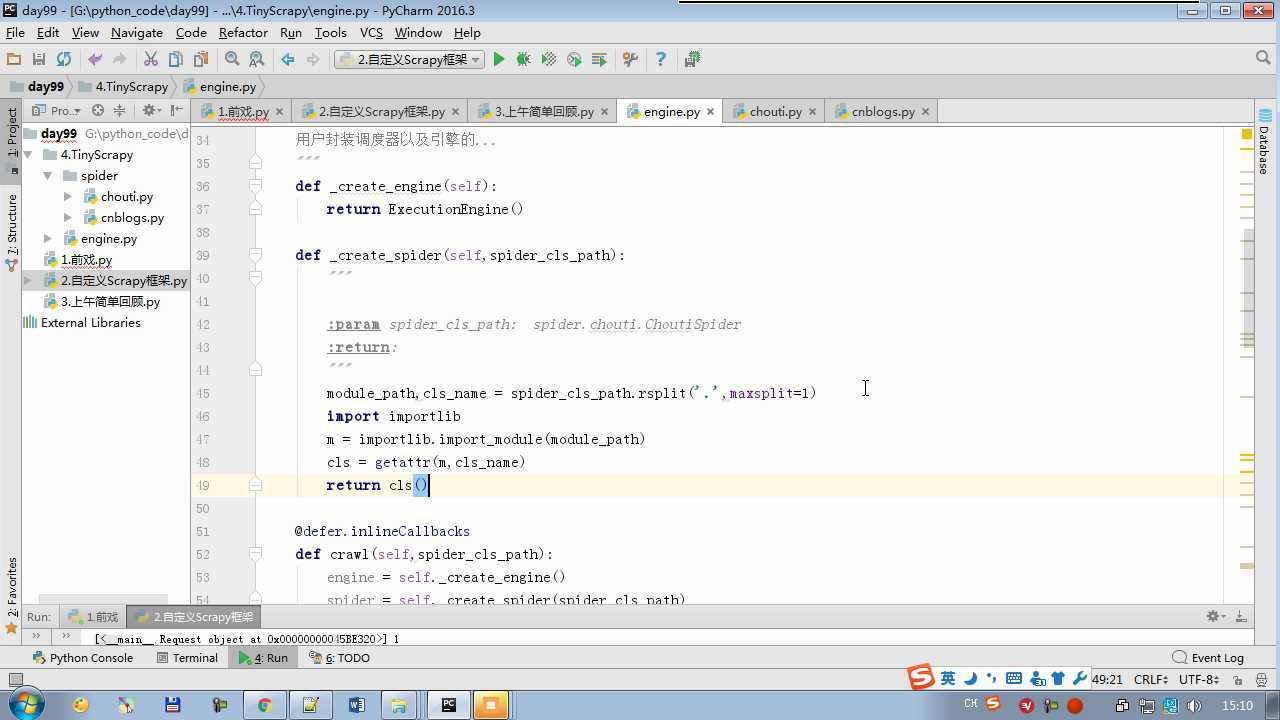
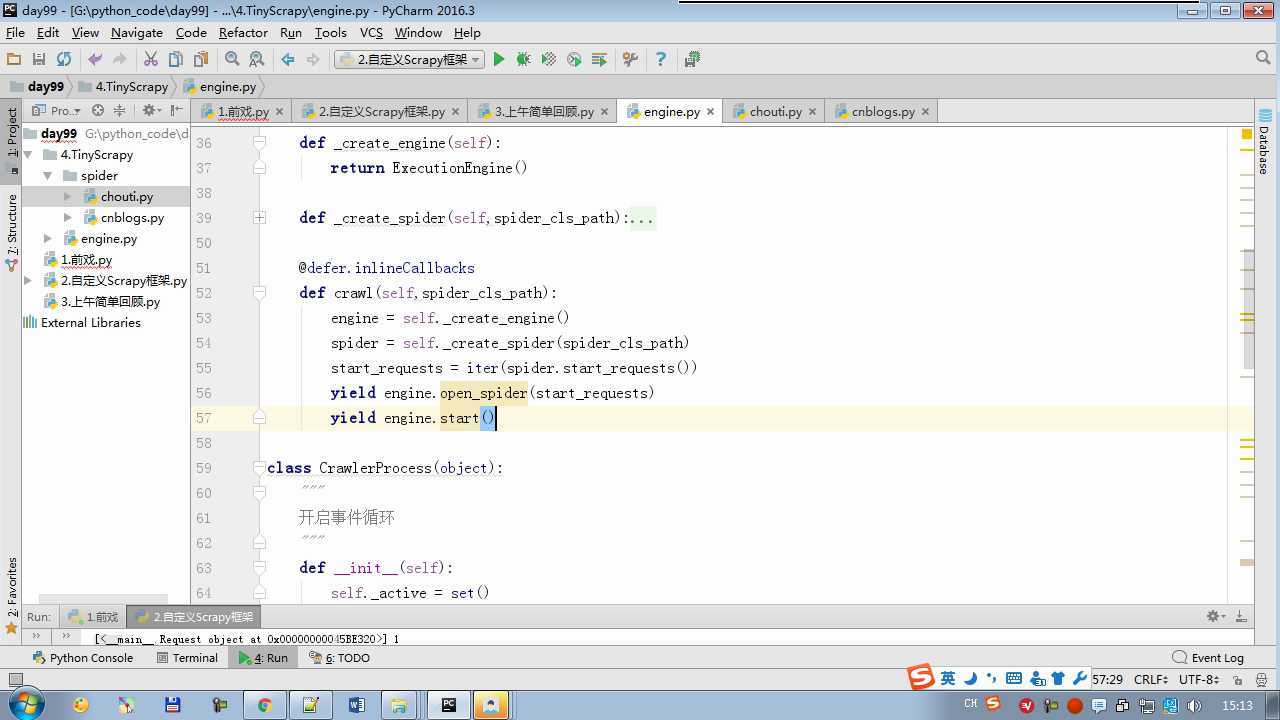
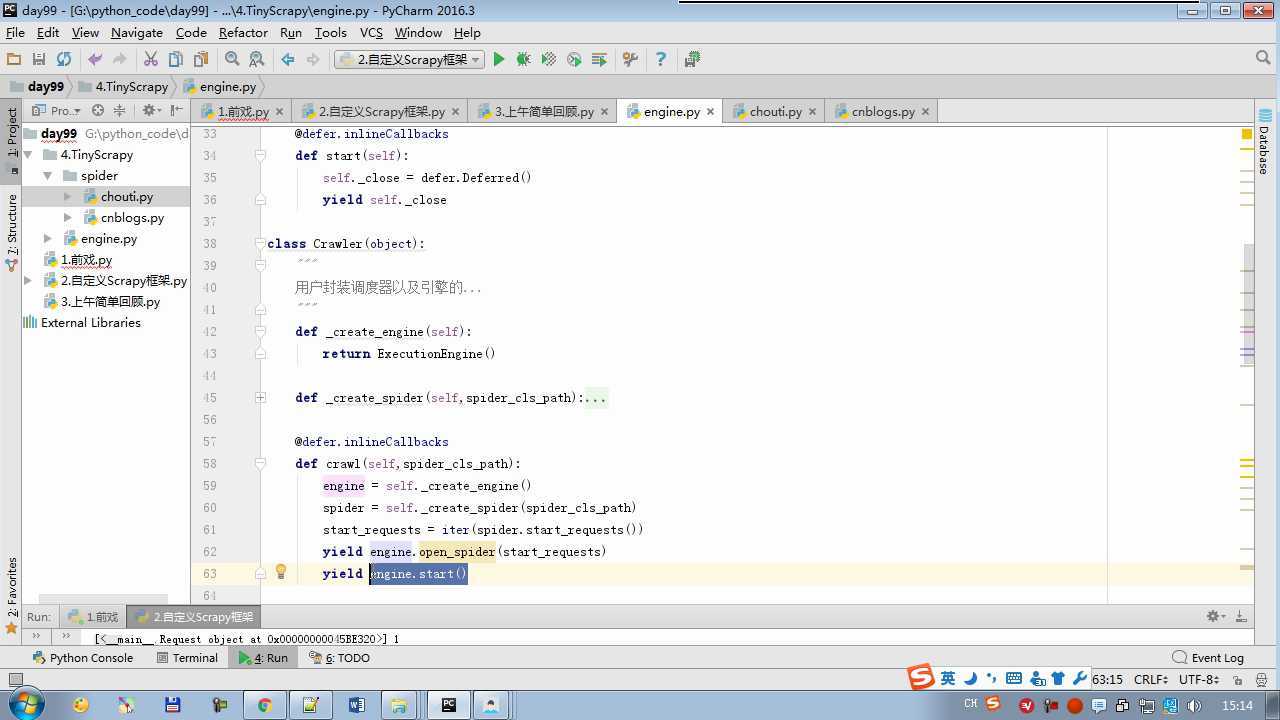
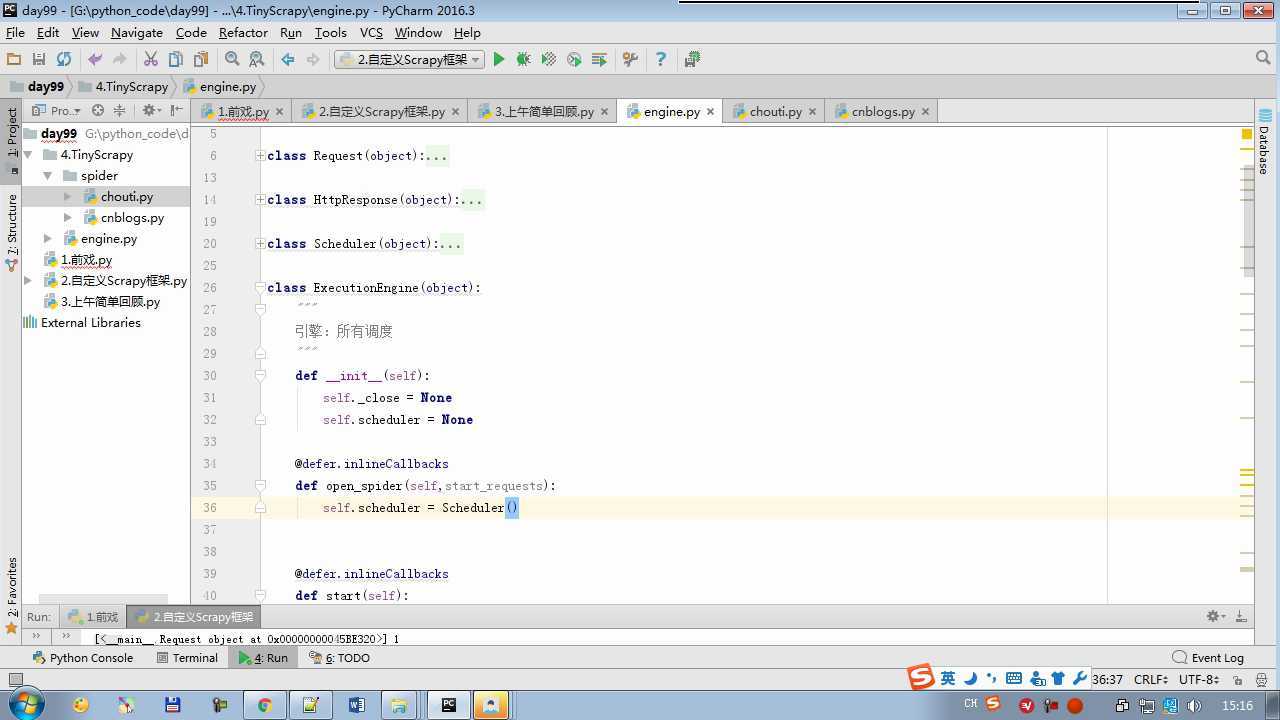
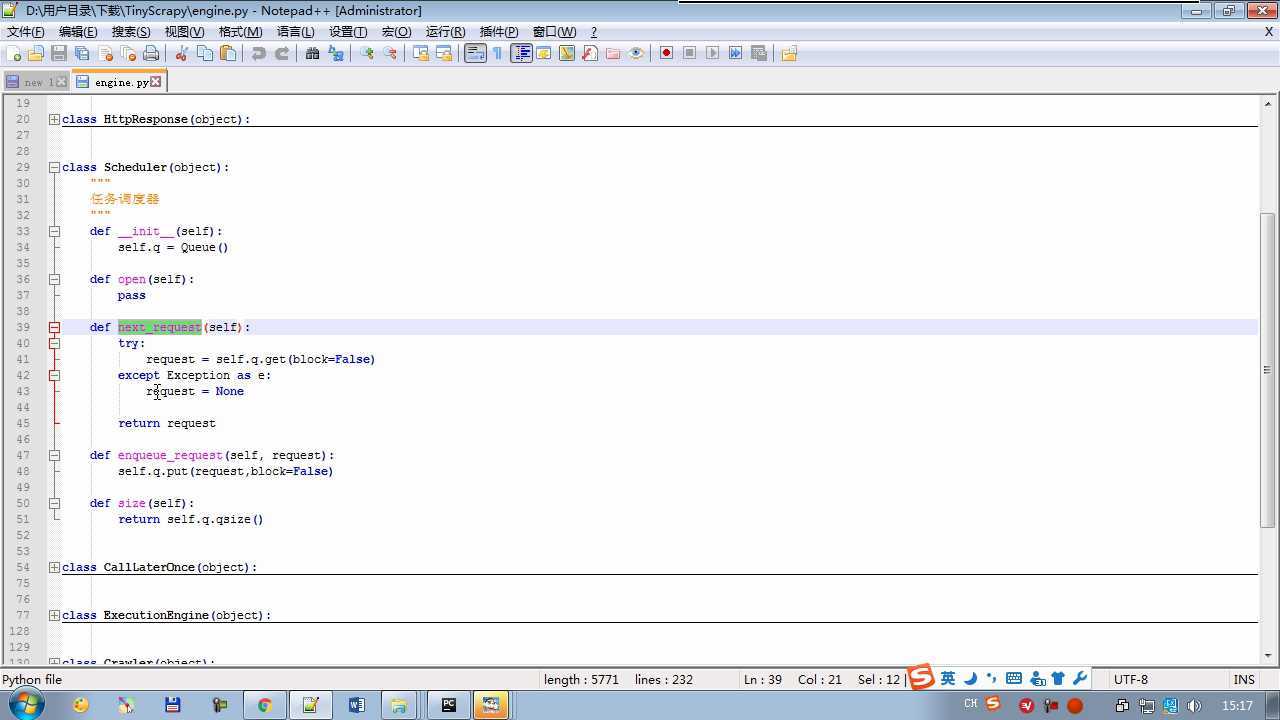
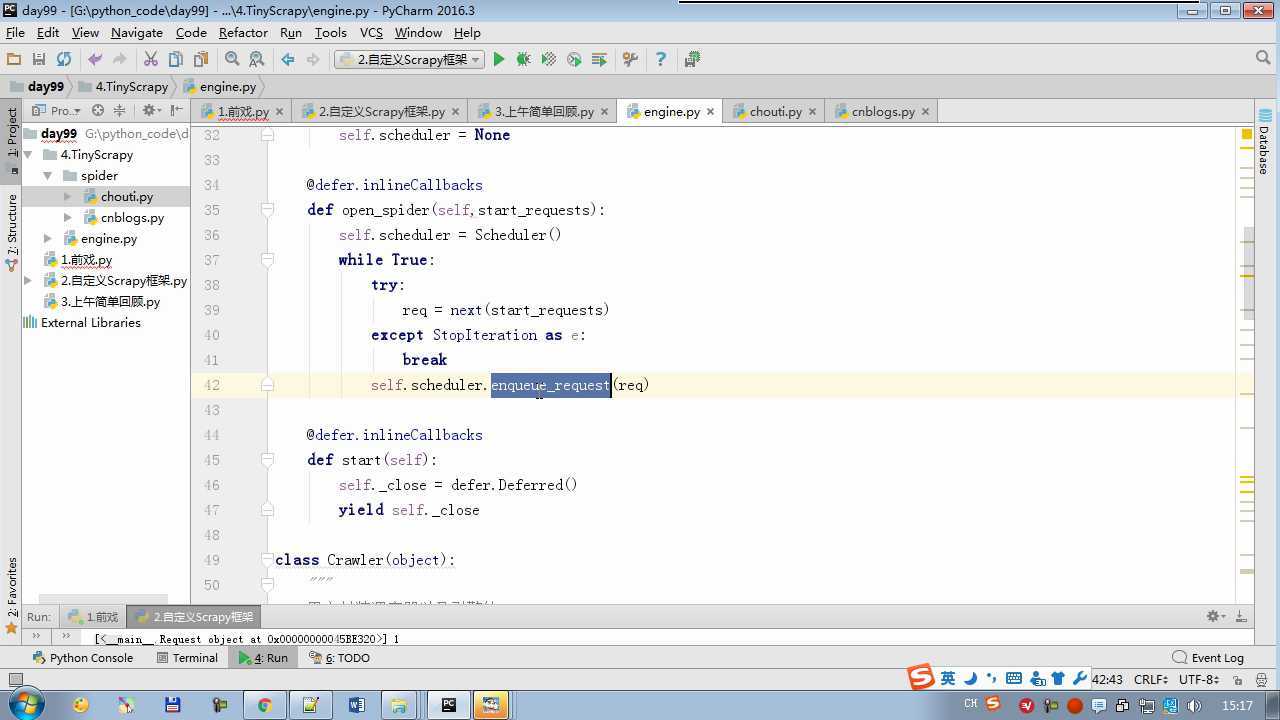
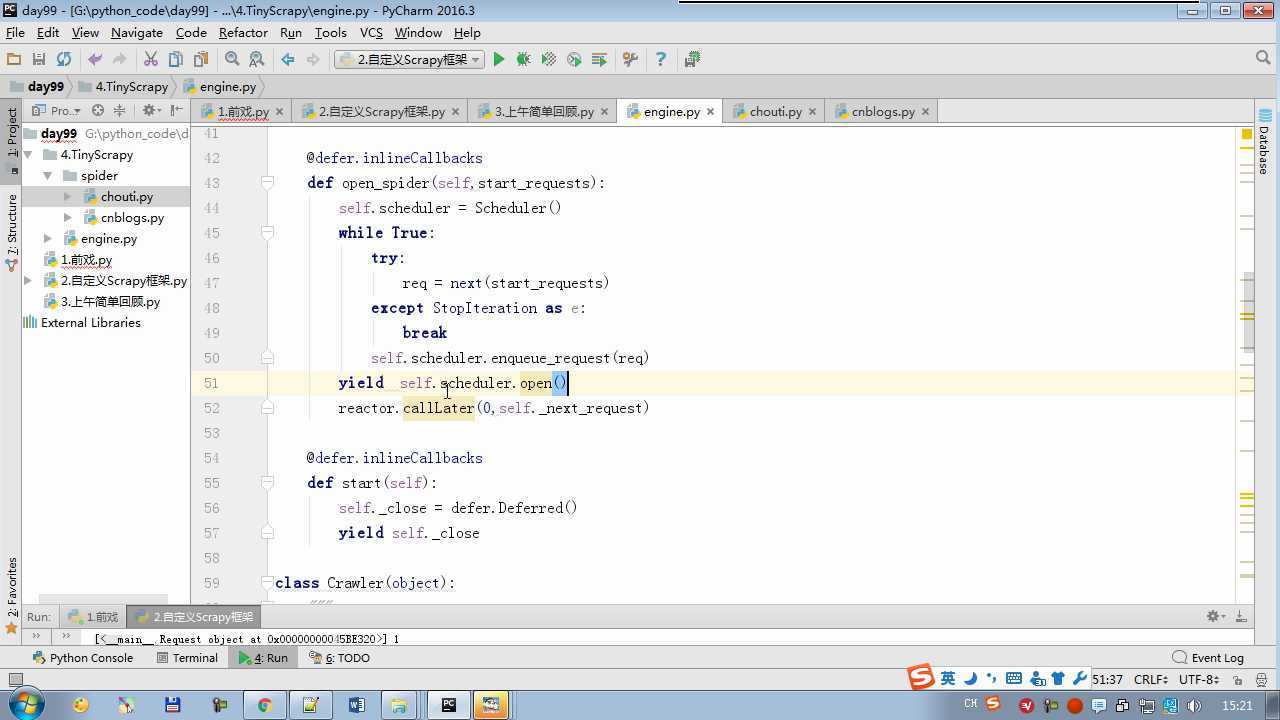
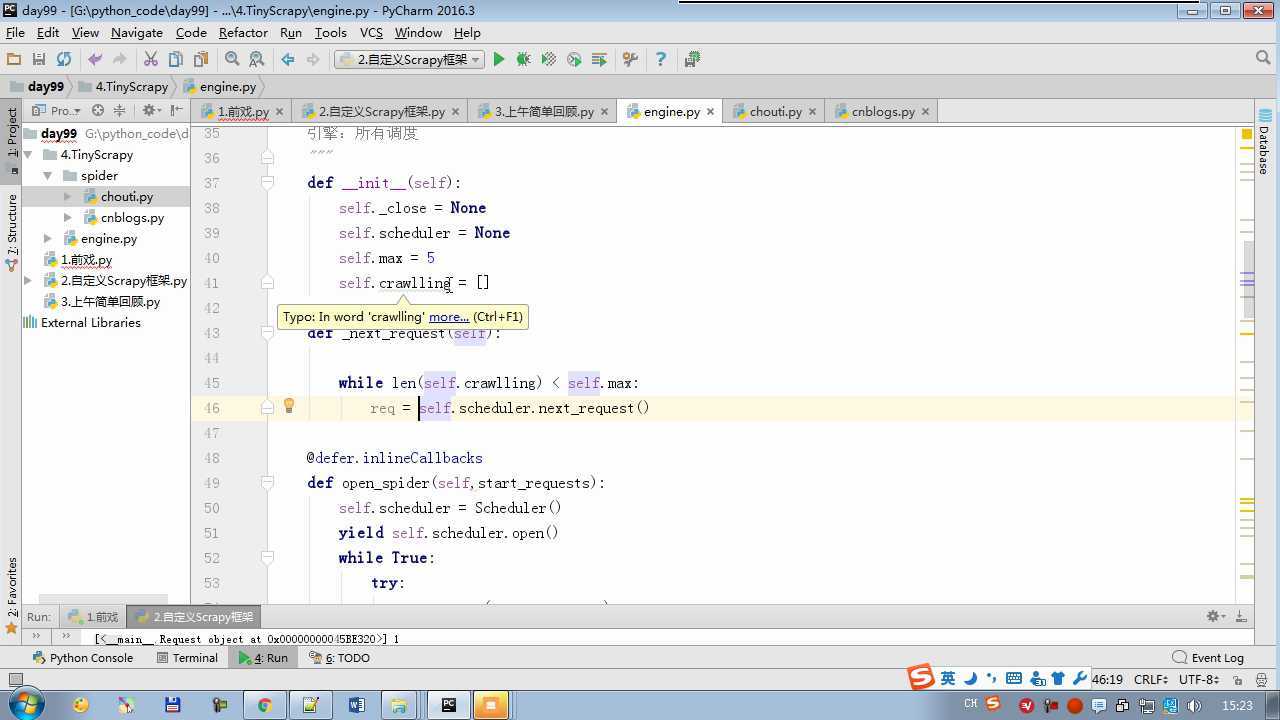
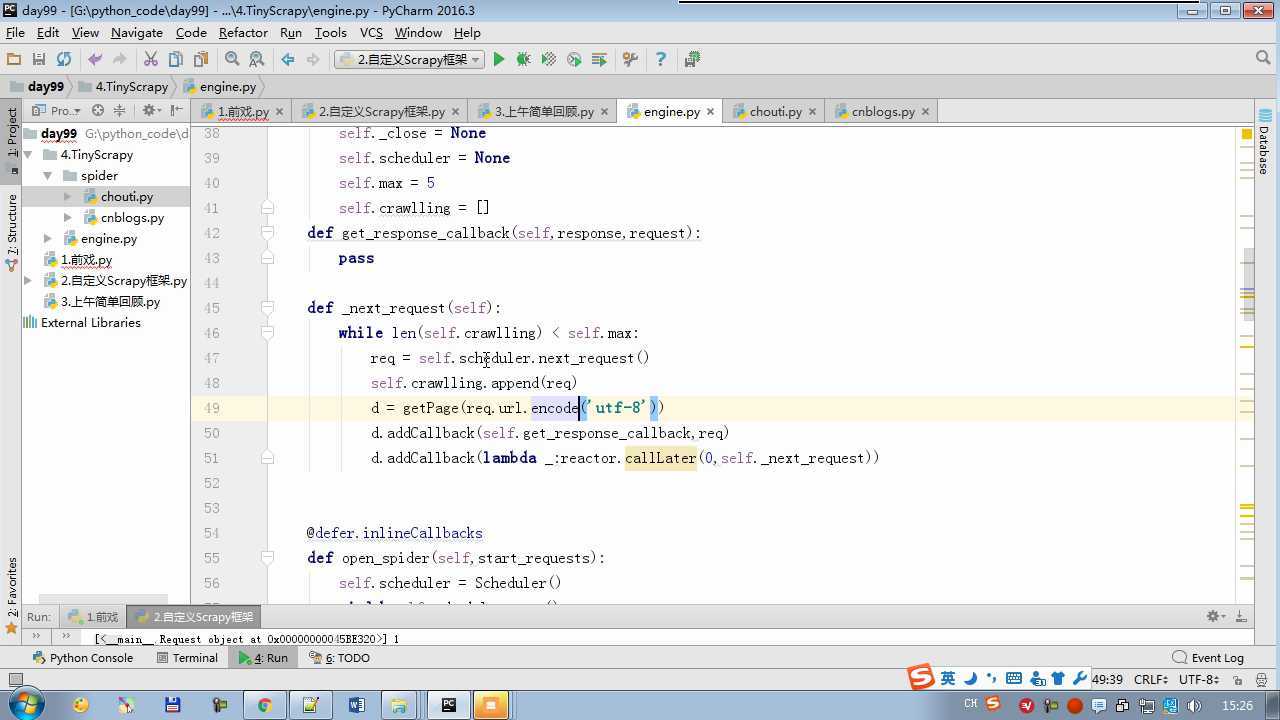
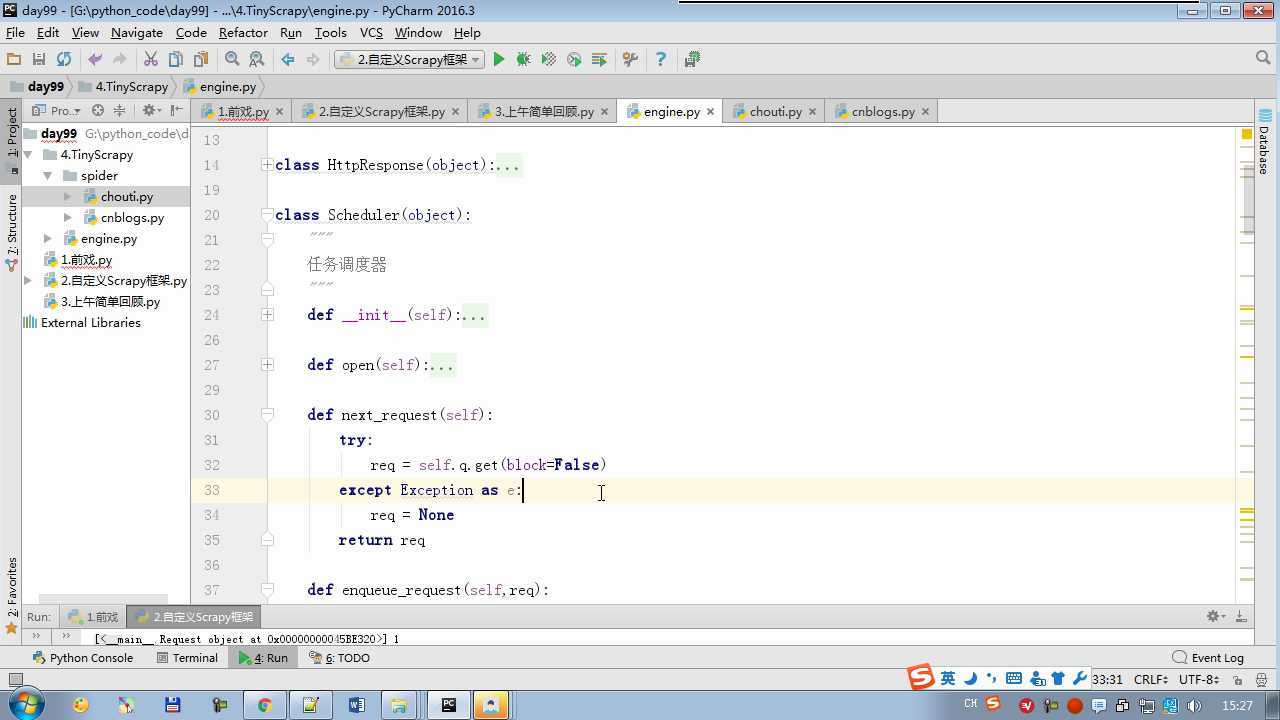
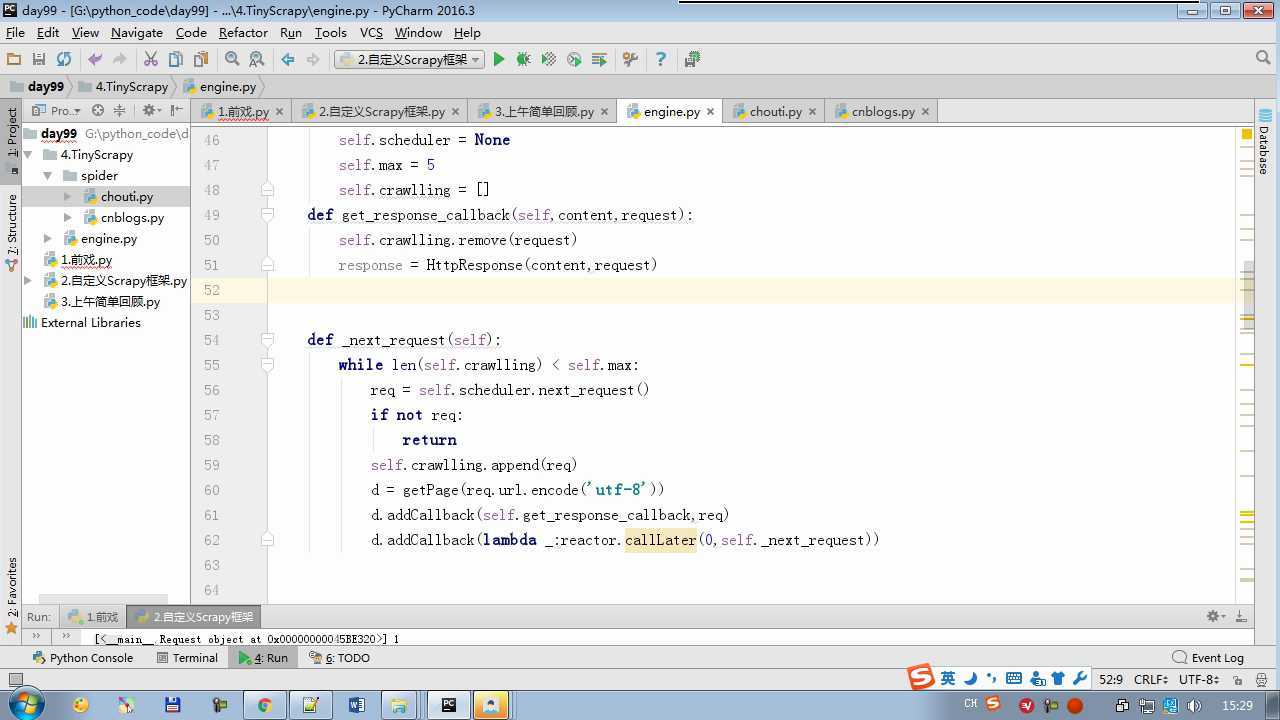
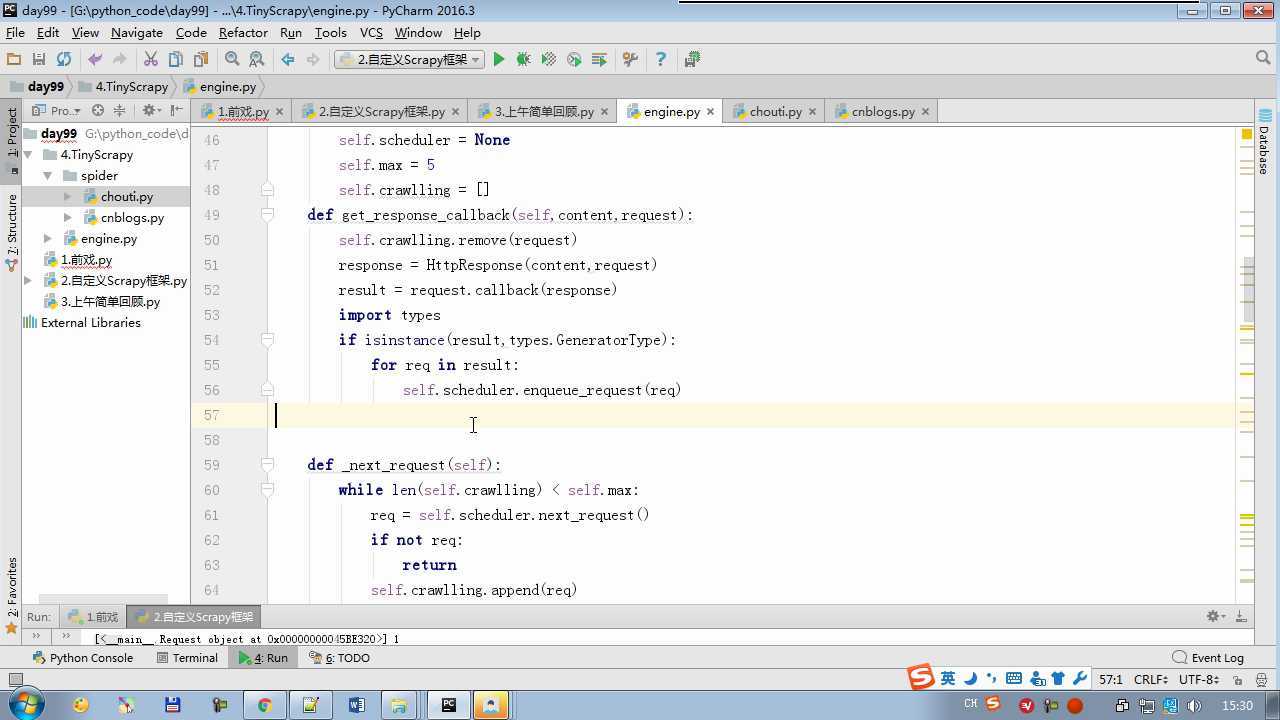
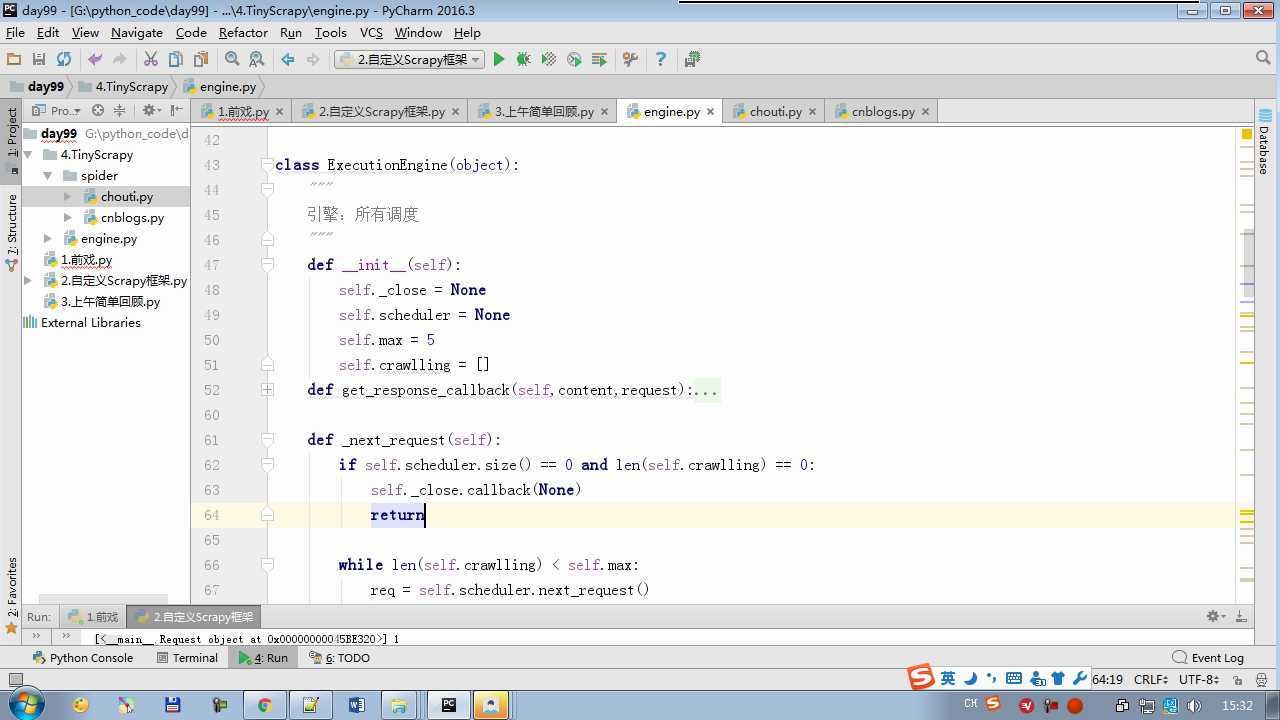
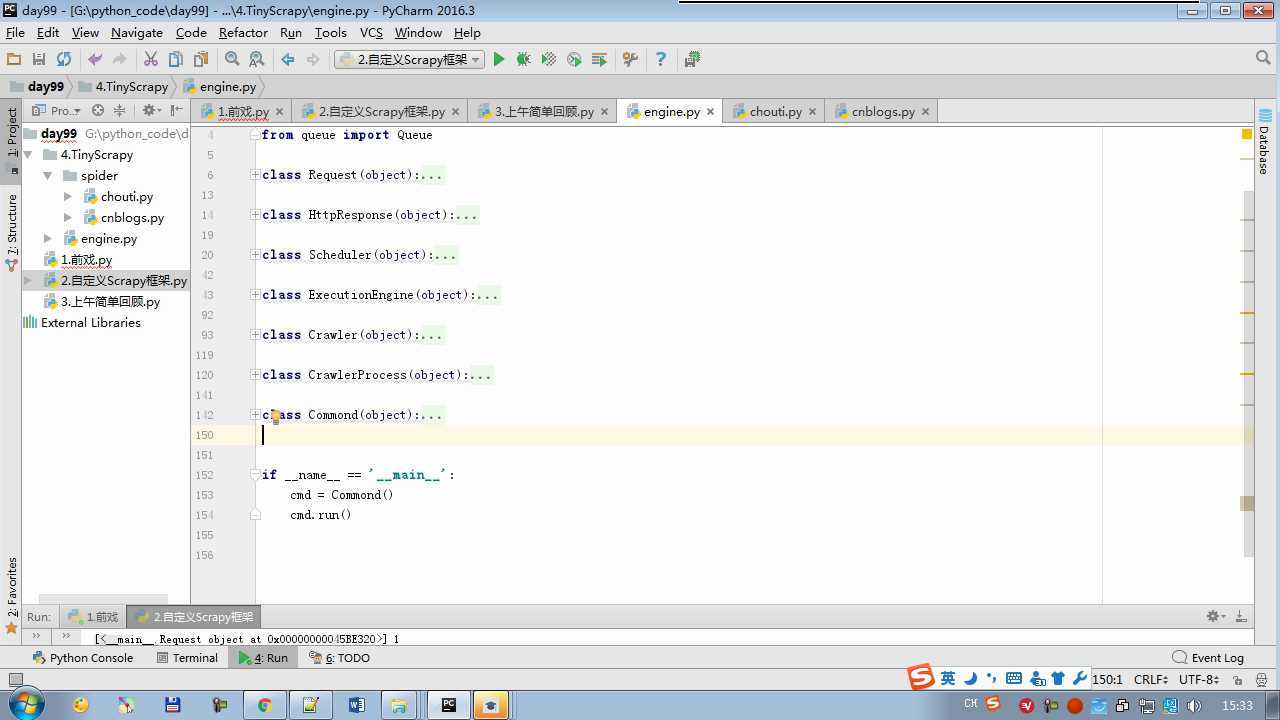
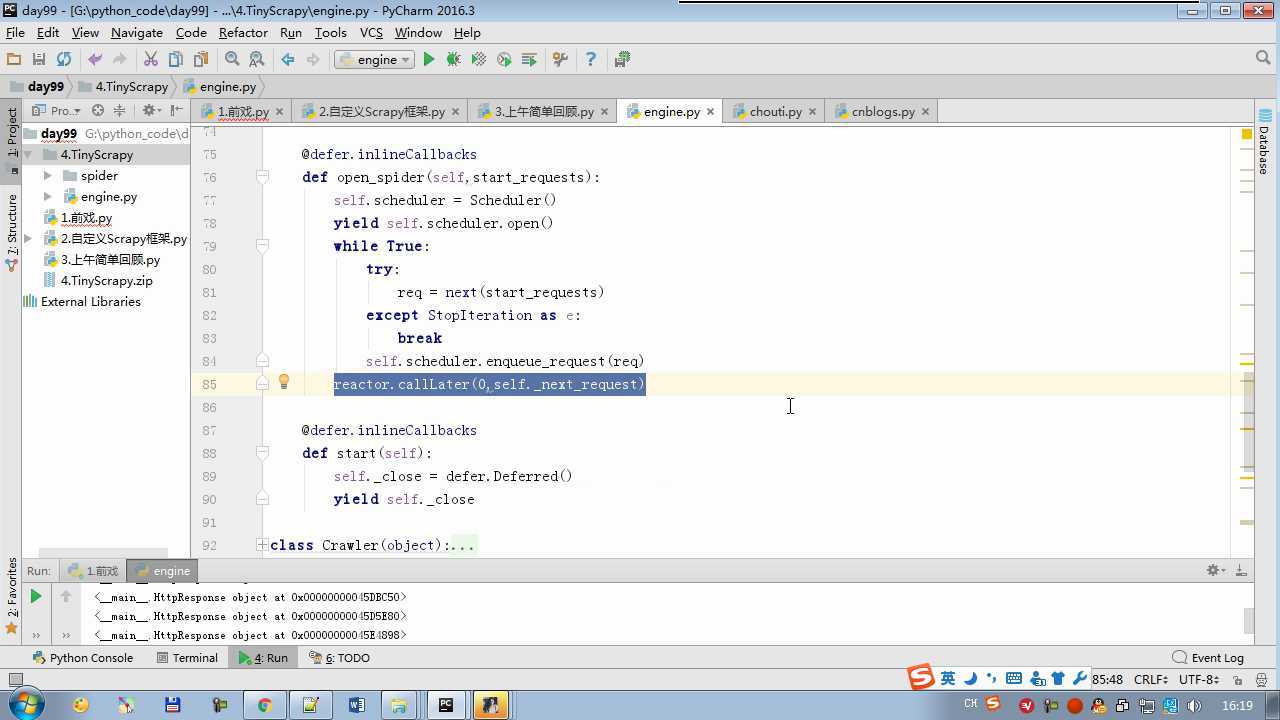
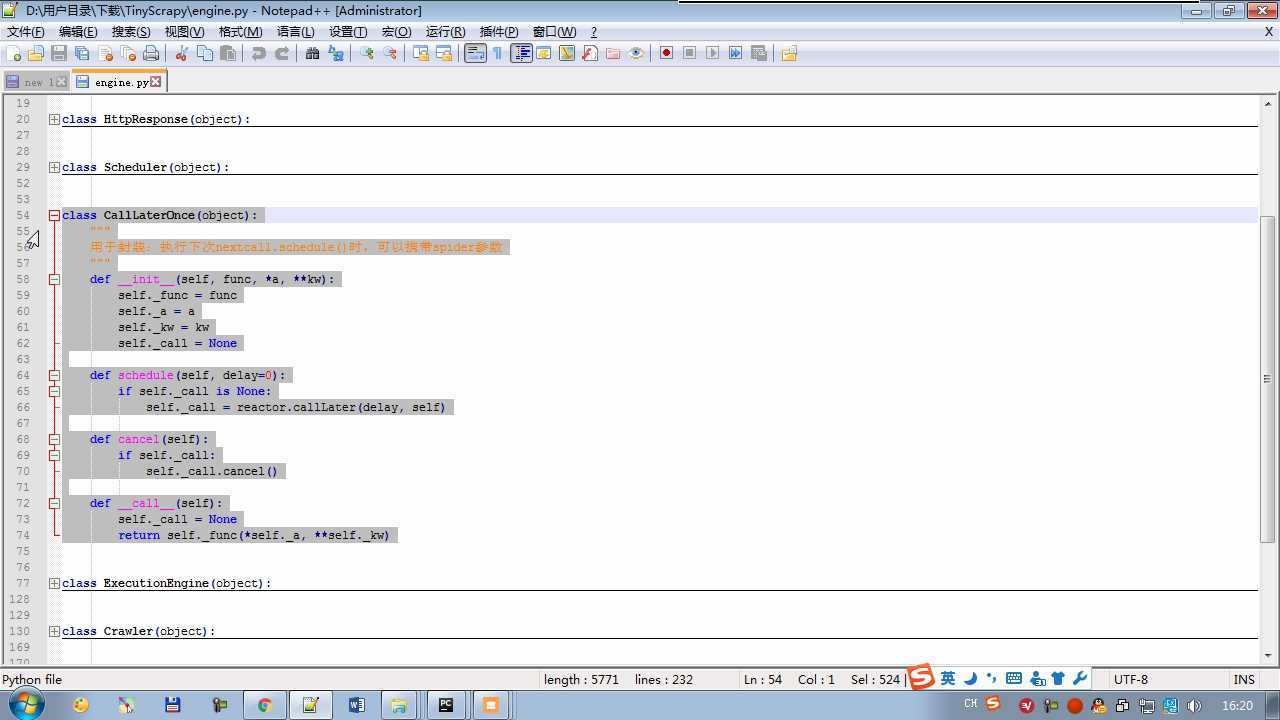
from twisted.internet import reactor # 事件循环(终止条件,所有的socket都已经移除) from twisted.web.client import getPage # socket对象(如果下载完成,自动从时间循环中移除...) from twisted.internet import defer # defer.Deferred 特殊的socket对象 (不会发请求,手动移除) from queue import Queue class Request(object): """ 用于封装用户请求相关信息 """ def __init__(self,url,callback): self.url = url self.callback = callback class HttpResponse(object): def __init__(self,content,request): self.content = content self.request = request class Scheduler(object): """ 任务调度器 """ def __init__(self): self.q = Queue() def open(self): pass def next_request(self): try: req = self.q.get(block=False) except Exception as e: req = None return req def enqueue_request(self,req): self.q.put(req) def size(self): return self.q.qsize() class ExecutionEngine(object): """ 引擎:所有调度 """ def __init__(self): self._close = None self.scheduler = None self.max = 5 self.crawlling = [] def get_response_callback(self,content,request): self.crawlling.remove(request) response = HttpResponse(content,request) result = request.callback(response) import types if isinstance(result,types.GeneratorType): for req in result: self.scheduler.enqueue_request(req) def _next_request(self): if self.scheduler.size() == 0 and len(self.crawlling) == 0: self._close.callback(None) return while len(self.crawlling) < self.max: req = self.scheduler.next_request() if not req: return self.crawlling.append(req) d = getPage(req.url.encode(‘utf-8‘)) d.addCallback(self.get_response_callback,req) d.addCallback(lambda _:reactor.callLater(0,self._next_request)) @defer.inlineCallbacks def open_spider(self,start_requests): self.scheduler = Scheduler() yield self.scheduler.open() while True: try: req = next(start_requests) except StopIteration as e: break self.scheduler.enqueue_request(req) reactor.callLater(0,self._next_request) @defer.inlineCallbacks def start(self): self._close = defer.Deferred() yield self._close class Crawler(object): """ 用户封装调度器以及引擎的... """ def _create_engine(self): return ExecutionEngine() def _create_spider(self,spider_cls_path): """ :param spider_cls_path: spider.chouti.ChoutiSpider :return: """ module_path,cls_name = spider_cls_path.rsplit(‘.‘,maxsplit=1) import importlib m = importlib.import_module(module_path) cls = getattr(m,cls_name) return cls() @defer.inlineCallbacks def crawl(self,spider_cls_path): engine = self._create_engine() spider = self._create_spider(spider_cls_path) start_requests = iter(spider.start_requests()) yield engine.open_spider(start_requests) yield engine.start() class CrawlerProcess(object): """ 开启事件循环 """ def __init__(self): self._active = set() def crawl(self,spider_cls_path): """ :param spider_cls_path: :return: """ crawler = Crawler() d = crawler.crawl(spider_cls_path) self._active.add(d) def start(self): dd = defer.DeferredList(self._active) dd.addBoth(lambda _:reactor.stop()) reactor.run() class Commond(object): def run(self): crawl_process = CrawlerProcess() spider_cls_path_list = [‘spider.chouti.ChoutiSpider‘,‘spider.cnblogs.CnblogsSpider‘,] for spider_cls_path in spider_cls_path_list: crawl_process.crawl(spider_cls_path) crawl_process.start() if __name__ == ‘__main__‘: cmd = Commond() cmd.run()


标签:app gen __init__ pes from init closed cli bre
原文地址:https://www.cnblogs.com/jintian/p/11442980.html
