标签:mysq 消息 互联网公司 tor com 效率 轻量 图片 稳定性
大数据也是构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等
storm,在做热数据这块,如果要做复杂的热数据的统计和分析,亿流量,高并发的场景下,最合适的技术就是storm,没有其他
举例说明:
Storm:实时缓存热点数据统计->缓存预热->缓存热点数据自动降级
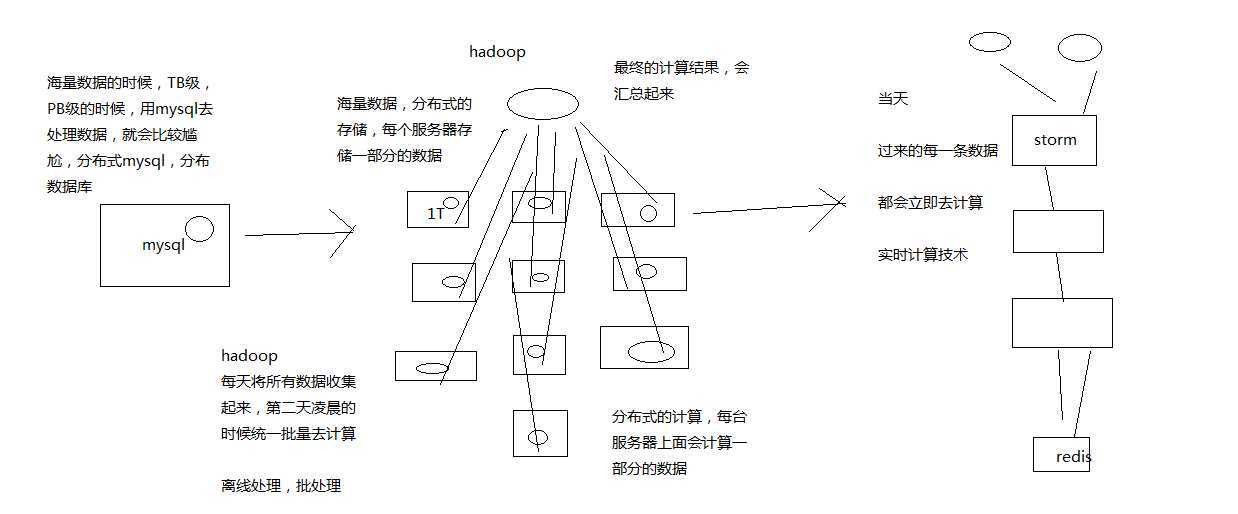
Hive:Hadoop生态栈里面,做数据仓库的一个系统,高并发访问下,海量请求日志的批量统计分析,日报周报月报,接口调用情况,业务使用情况,等等
我所知,在一些大公司里面,是有些人是将海量的请求日志打到hive里面,做离线的分析,然后反过来去优化自己的系统
Spark:离线批量数据处理,比如从DB中一次性批量处理几亿数据,清洗和处理后写入Redis中供后续的系统使用,大型互联网公司的用户相关数据
ZooKeeper:分布式系统的协调,分布式锁,分布式选举->高可用HA架构,轻量级元数据存储
HBase:海量数据的在线存储和简单查询,替代MySQL分库分表,提供更好的伸缩性
java底层,对应的是海量数据,然后要做一些简单的存储和查询,同时数据增多的时候要快速扩容
mysql分库分表就不太合适了,mysql分库分表扩容,还是比较麻烦的
Elasticsearch:海量数据的复杂检索以及搜索引擎的构建,支撑有大量数据的各种企业信息化系统的搜索引擎,电商/新闻等网站的搜索引擎,等等
mysql的like "%xxxx%",更加合适一些,性能更加好
hystrix,分布式系统的高可用性的限流,熔断,降级,等等,一些措施,缓存雪崩的方案,限流的技术
一、Storm到底是什么?
1、mysql,hadoop与storm
mysql:事务性系统,面临海量数据的尴尬
hadoop:离线批处理
storm:实时计算
3、storm的特点是什么?
(1)支撑各种实时类的项目场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进行并行化,基于DRPC,即分布式RPC调用,单表30天数据,并行化,每个进程查询一天数据,最后组装结果
storm做各种实时类的项目都ok
(2)高度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
扩容起来,超方便
(3)数据不丢失的保证:storm的消息可靠机制开启后,可以保证一条数据都不丢
数据不丢失,也不重复计算
(4)超强的健壮性:从历史经验来看,storm比hadoop、spark等大数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧
特别的健壮,稳定性和可用性很高
(5)使用的便捷性:核心语义非常的简单,开发起来效率很高
用起来很简单,开发API还是很简单的
标签:mysq 消息 互联网公司 tor com 效率 轻量 图片 稳定性
原文地址:https://www.cnblogs.com/sunliyuan/p/11443699.html