标签:from ade code 构建 学历 csv文件 com 获取数据 技术
今天不知道写点什么,想到金9银10了写一篇抓取拉勾网我们软件测试工程师的薪资~~
发现是请求地址:https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false
通过post形式请求的,请求参数也可以看到
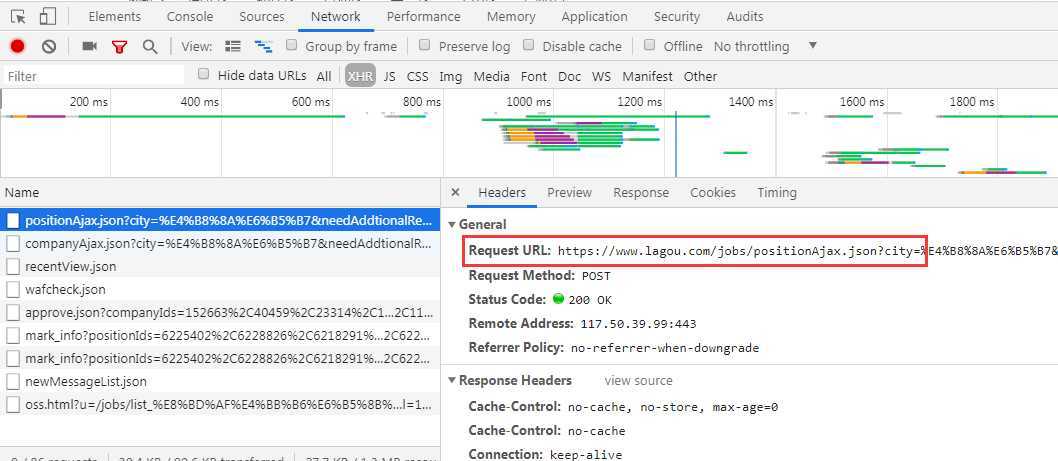
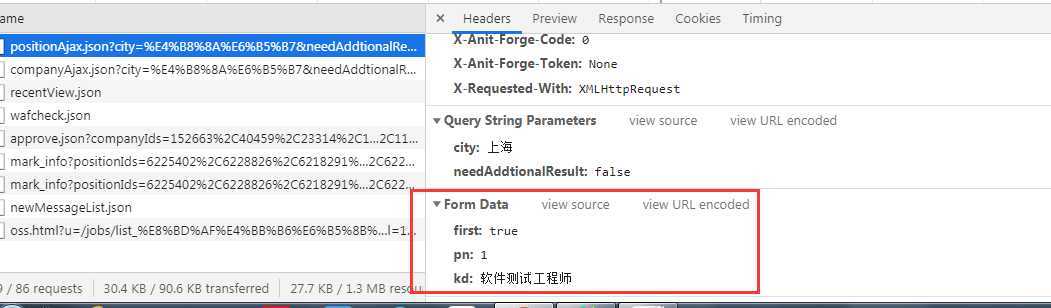
通过分析,数据已json的格式存在preview中
怎么获取数据呢? 我们可以通过获取返回的json内容,通过json的内容找到我们想要的数据
首先直接请求requests拉勾网信息,添加请求头。
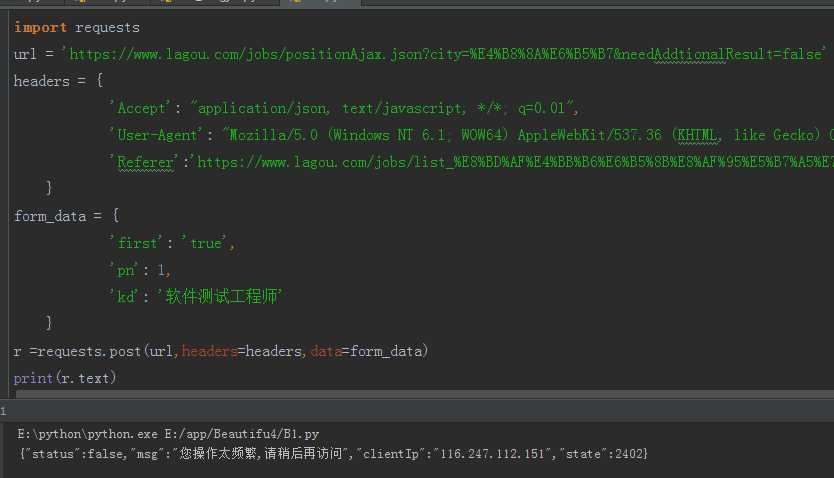
发现会提示请求频繁无法获取网站信息,那这样怎么去搞?
前面小编写过一个通过session会话请求的数据,那么我们今天来试试
首先请求我们网页显示的信息获取cookies值,携带这网页的cookies再去请求我们需要爬取的url
import requests # 请求地址 url = ‘https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false‘ # 请求头 headers = { ‘Accept‘: "application/json, text/javascript, */*; q=0.01", ‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", ‘Referer‘:‘https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=‘ } # 请求参数 form_data = { ‘first‘: ‘true‘, ‘pn‘: 1, ‘kd‘: ‘软件测试工程师‘ } # 导入session回话 s = requests.session() # 请求页面地址获取cookies url_list = ‘https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=‘ s.get(url_list, headers=headers) cookie = s.cookies # 携带cookies值继续请求 response = s.post(url, data=form_data, headers=headers,cookies=cookie) job_json = response.json() # 获取json数据 print(job_json)
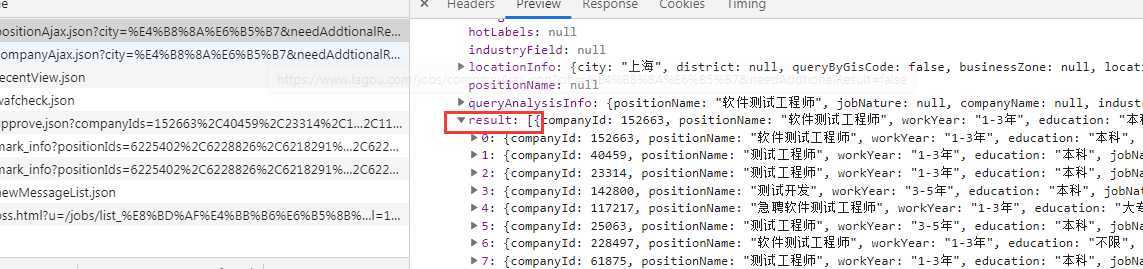
通过观察返回的json数据我们得知我们需要的数据都在result数据里面,那么通过json的方式我们可以提取出来,放到一个列表中,方便稍后我们写入csv文件中
csv_data = [] for i in job_list: job_info = [] job_info.append(i[‘positionName‘]) # 职位 job_info.append(i[‘companyShortName‘]) # 公司 job_info.append(i[‘salary‘]) # 薪资 job_info.append(i[‘education‘]) # 学历 job_info.append(i[‘district‘]) # 位置 job_info.append(i[‘workYear‘]) # 工作经验要求 job_info.append(i[‘positionAdvantage‘]) # 福利待遇 csv_data.append(job_info)
写入csv文件写过很多次了,基本上都是一样的
csvfile = open(‘软件职业.csv‘, ‘a+‘,encoding=‘utf-8-sig‘,newline=‘‘) writer = csv.writer(csvfile) writer.writerows(csv_data) csvfile.close()
通过观察分页的控制是在form_data中,我们呢就模拟分页内容,爬取全部数据
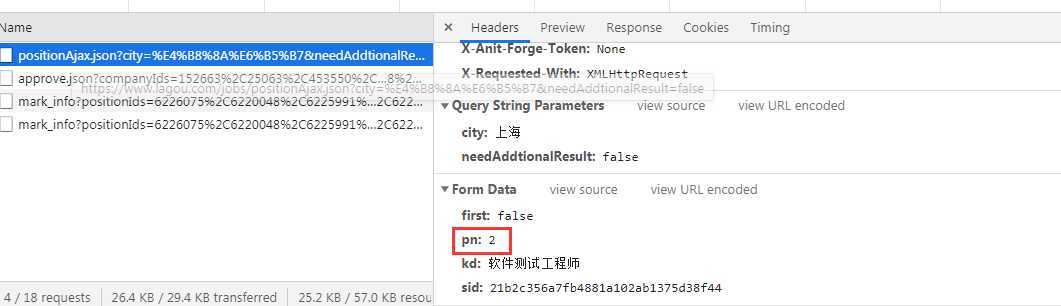
all = [] for page_num in range(1, 30): result = data(page=page_num) # 获取一共多少个数据 all += result print(‘已抓取{}页, 总职位数:{}‘.format(page_num, len(all)))
import requests # 请求地址 url = ‘https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false‘ # 请求头 headers = { ‘Accept‘: "application/json, text/javascript, */*; q=0.01", ‘User-Agent‘: "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", ‘Referer‘:‘https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=‘ } # 请求参数 form_data = { ‘first‘: ‘true‘, ‘pn‘: 1, ‘kd‘: ‘软件测试工程师‘ } # 导入session回话 s = requests.session() # 请求页面地址获取cookies url_list = ‘https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=‘ s.get(url_list, headers=headers) cookie = s.cookies # 携带cookies值继续请求 response = s.post(url, data=form_data, headers=headers,cookies=cookie) job_json = response.json() csv_data = [] for i in job_list: job_info = [] job_info.append(i[‘positionName‘]) # 职位 job_info.append(i[‘companyShortName‘]) # 公司 job_info.append(i[‘salary‘]) # 薪资 job_info.append(i[‘education‘]) # 学历 job_info.append(i[‘district‘]) # 位置 job_info.append(i[‘workYear‘]) # 工作经验要求 job_info.append(i[‘positionAdvantage‘]) # 福利待遇 csv_data.append(job_info) # 写入列表中 print(csv_data) csvfile = open(‘软件职业.csv‘, ‘a+‘,encoding=‘utf-8-sig‘,newline=‘‘) writer = csv.writer(csvfile) writer.writerows(csv_data) csvfile.close() return csv_data if __name__ == ‘__main__‘: a = [(‘职位‘,‘公司‘,‘薪资‘,‘学历‘,‘位置‘,‘工作经验要求‘,‘福利待遇‘)] csvfile = open(‘软件职业.csv‘, ‘a+‘,encoding=‘utf-8-sig‘,newline=‘‘) writer = csv.writer(csvfile) writer.writerows(a) csvfile.close() all = [] for page_num in range(1, 30): result = data(page=page_num) all += result print(‘已抓取{}页, 总职位数:{}‘.format(page_num, len(all))) # 控制时间,防止网站认为爬虫 time.sleep(15)
抓取的结果:
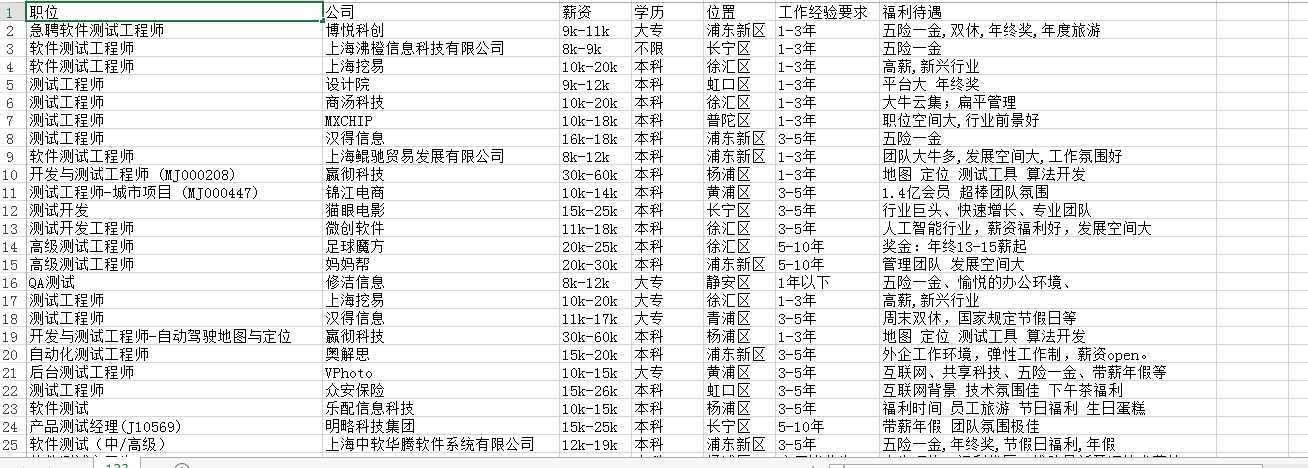
看到我们测试工资这么高,好心动,~~~~~
注意,不要请求太过于频繁,会认为爬虫封IP的。
如果感觉喜欢的话,右下角点个关注~~~
标签:from ade code 构建 学历 csv文件 com 获取数据 技术
原文地址:https://www.cnblogs.com/qican/p/11283954.html