标签:mic 如何 取数据 lxml path 换行 man 初始化 rom
在上一节,我们介绍了正则表达式的使用,但是当我们提取数据的限制条件增多的时候,正则表达式会变的十分的复杂,出一丁点错就提取不出来东西了。但python已经为我们提供了许多用于解析数据的库,接下来几篇博客就给大家简单介绍一下xpath、beautiful soup以及pyquery的使用。今天首先进入xpath的学习。
在引入实例之前,我们先编写一个html,如下所示:
<div>
<url>
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-inactive"><a href="link3.html">second item</a></li>
<li class="item-1"><a href="link4.html">third item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</url>
</div>接下来我们都将围绕这段进行尝试
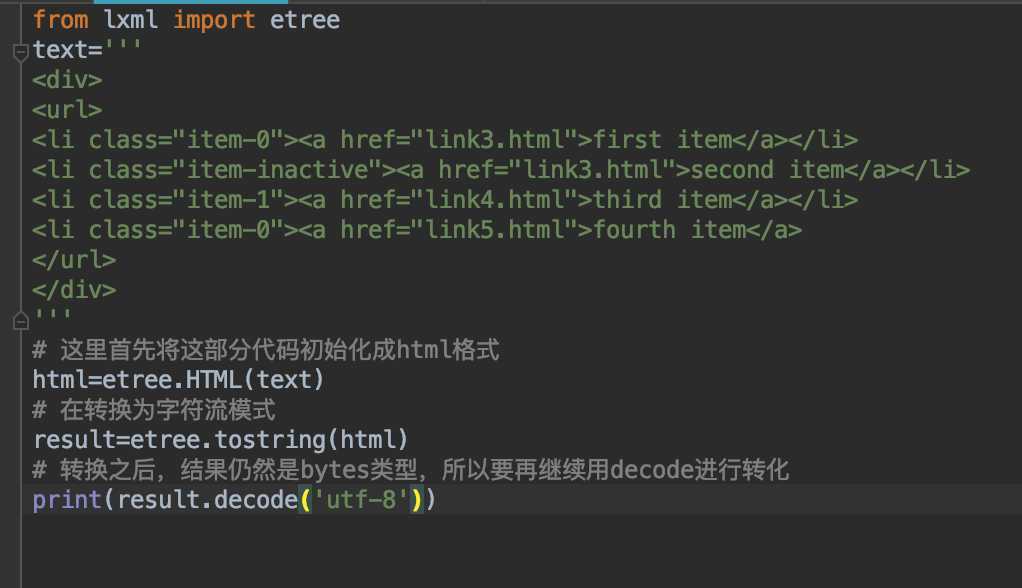
首先我们使用lxml库
第一步先将这段文本转换为一个etree的对象,再进行转换,输出结果,我们输出之后发现,愿文本中缺失的闭标签被自动的补齐,所以输出的是一段完整的html,如下所示:
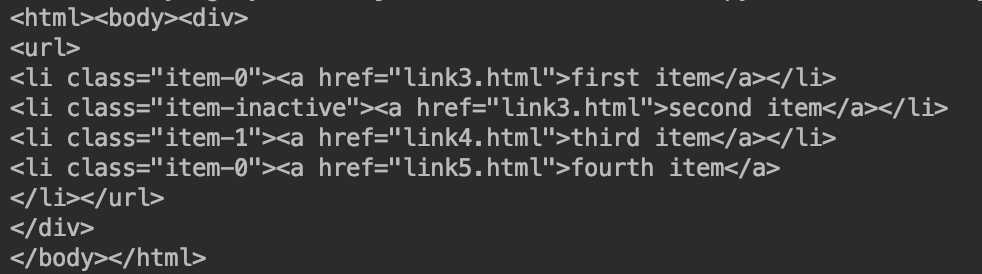
我们可以看到最后一个li标签 被补齐了,又多出来了html和body
这就变成了一段完整的html啦~
下面主要介绍一下用xpath寻找需要的节点
与正则表达式相同,xpath也拥有一个书写表达式的准则,如下所示:
/ 直接的子节点
// 所有的子节点
.. 父节点
* 所有节点
@ 属性
[] 中括内是约束条件
接下来先介绍一下如何查找子节点
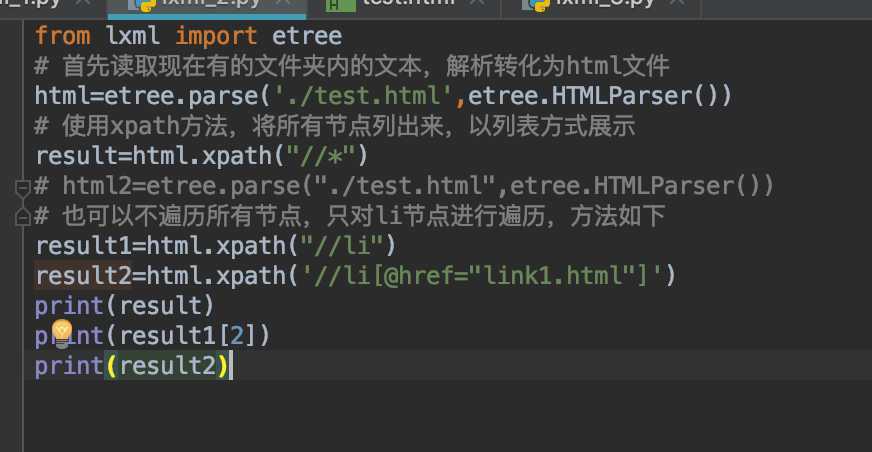
首先看result的值,用//表示所有的子节点,后面跟*代表把所有节点。
再看result1的值,用//表示所有子节点,后面跟li,代表所有的 li 节点。
这里还需要注意一点的是,找到的内容都是一个列表的形式,那么当然也可以用数组的方式去找啦~
第三个我们暂且不看,这就是找对应的子节点的方法。
下面我们看一下如何找父节点
其实规则和之前的一样,我们只需先找到 需要父节点的节点,然后用 .. 就可以定位到上一层的父节点了。就是这么简单。
上面那个代码片的result2,就是在找到需要找的节点类型 li 之后,后面跟了[]来表示约束条件,括号里的内容也很好理解,就是属性href为link1.html的 li 节点
那么有人可能会问了,如果要对一个节点有多个属性同时进行限制呢?
其实也很简单,因为逻辑运算符在这里当然适用,只用在中括号中,用and or 不等号进行连接,就能同时对多属性进行筛选
假如说现在有一段html是这样的
<li class="item-0 item"><a href="link3.html">first item</a></li>
如果再用
之前的方法对class值为item-0的节点进行筛选,就找不到这个了,因为,里面不是一个属性,还有另外一个item呢,所以我们这里要用到contains这个方法,
改为
etree.xpath(‘//li[contains(class,"item-0")]‘)即可
在前面,我们知道了如何找到需要的节点,肯定也想知道如何找到节点的内容(不然找他们干嘛呢),这里py为我们提供了一个text()的用法,我们可以看下面的一段代码

还是上面的文本,这段代码,首先找到class为item-0的节点,有两个,分别是
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
但是又一点要注意的是,在初始化的时候,这段文本已经被自动补齐了,变成如下所示:
<li class="item-0"><a href="link3.html">first item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</li>
先看看这段代码的输出结果
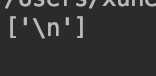
这是因为,我们用的是/ 这个符号,也就是说,只能找到 li 节点自己的文本,所以一个为空,一个为换行符
那么要找到我们想找到的,有两个途径,首先尝试第一个
先找到a节点,再输出其中的内容,代码以及结果如下:

结果:

可以看到输出了我们期待的结果直接// 输出所有的text
代码以及结果如下:
再看第二种方法,也就是

结果:

可以看到,这里还输出了换行符,也是可以理解的。
还是上面的那段文本,有很多 li 节点,其实在筛选的时候,我们可以直接用 节点?下标来查找节点,但是需要注意的是,这里的下标顺序就是从1开始的
以上就是对于xpath使用的简单介绍,博主也在学习,想通过博客记录成长,有问题欢迎提出,一起讨论!下一篇介绍Beautifu Soup的使用
标签:mic 如何 取数据 lxml path 换行 man 初始化 rom
原文地址:https://www.cnblogs.com/HiangXuUp/p/11445233.html