标签:现在 原因 引入 没有 框架 分割 pre 聚合 com

Flink对于流处理架构的意义十分重要,Kafka让消息具有了持久化的能力,而处理数据,甚至穿越时间的能力都要靠Flink来完成。
在Streaming-大数据的未来一文中我们知道,对于流式处理最重要的两件事,正确性,时间推理工具。而Flink对两者都有非常好的支持。
对于连续的事件流数据,由于我们处理时可能有事件暂未到达,可能导致数据的正确性受到影响,现在采取的普遍做法的通过高延迟的离线计算保证正确性,但是也牺牲了低延迟。
Flink的正确性体现在计算窗口的定义符合数据产生的自然规律。比如点击流事件,追踪3个用户A,B,C的访问情况。我们看到数据是可能有间隙的,这也就是session窗口。
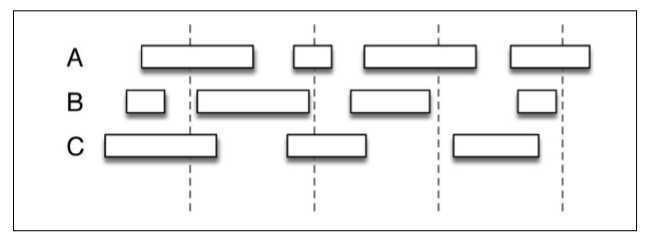
用SparkStreaming的微批处理方式(虚线为计算窗口,实线是会话窗口),很难做到计算窗口与会话窗口的吻合。而使用Flink的流处理API,可以灵活的定义计算窗口。比如可以设置一个值,如果超出这个值就认为活动结束。
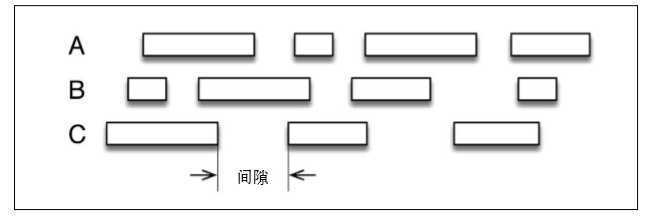
不同于一般的流处理,Flink可以采用事件时间,这对于正确性非常有用。
对于发生故障性的正确性保证,必须要跟踪计算状态,现在大部分时候状态性的保证是靠开发人员完成的,但是连续的流处理计算没有终点。Flink采用检查点-checkpoint技术解决了这个问题。在每个检查点,系统都会记录中间计算状态,从而在故障发生时准确地重 置。这一方法使系统以低开销的方式拥有了容错能力——当一切正常时, 检查点机制对系统的影响非常小。
Flink提供的接口,包括了跟踪计算的任务,并用同一种技术来实现流处理和批处理,简化了运维开发工作,这也是对正确性的一种保证。
用流处理和批处理最大的区别就是对时间的处理。
在该架构中,我们可以每隔一段时间存储数据,比如存在HDFS中,由调度程序定时的执行,将结果输出。
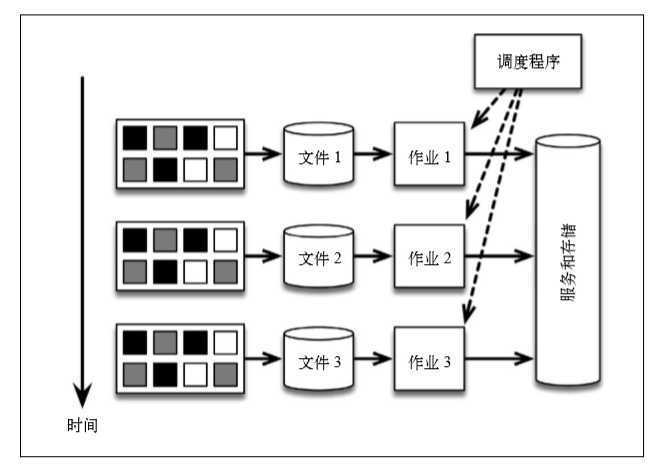
这种架构可行但是有几个问题:
太多独立的部分。为了计算数据中的事件数,这种架构动用了太多系统。 每一个系统都有学习成本和管理成本,还可能存在 bug。
对时间的处理方法不明确。假设需要改为每 30 分钟计数一次。这个变动涉及工作流调度逻辑(而不是应用程序代码逻辑),从而使 DevOps 问题 与业务需求混淆。
预警。假设除了每小时计数一次外,还需要尽可能早地收到计数预警( 如在事件数超过10 时预警)。为了做到这一点,可以在定期运行的批处理作业之外,引入 Storm 来采集消息流。 Storm 实时提供近似的计数,批处理作业每小时提供准确的计数。但是这样一来,就向架构增加了一个系统,以及与之相关的新编程模型。上述架构叫作 Lambda 架构。
?
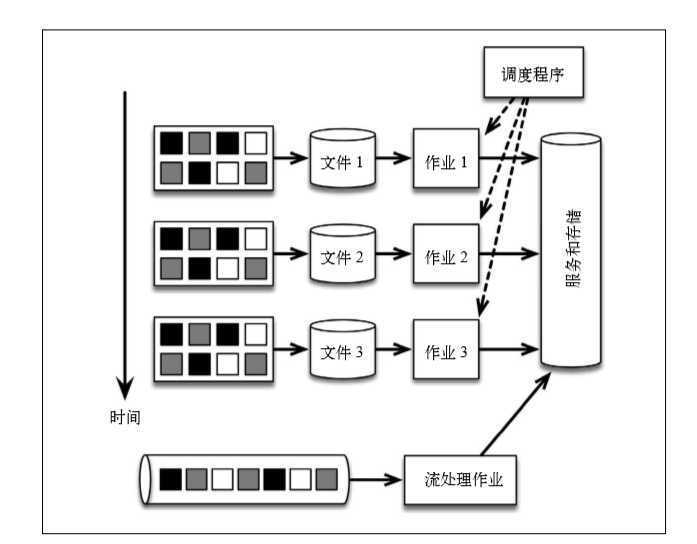
首先将消息集中写入消息传输系统kafka,事件流由消息传输系统提供,并且只被单一的 Flink 作业处理。
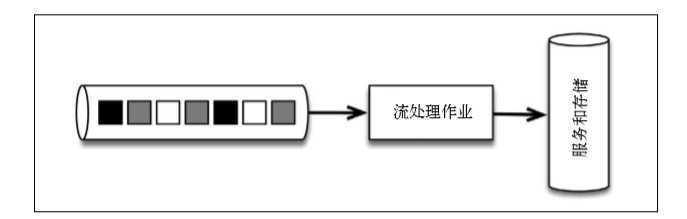
以时间为单位把事件流分割为一批批任务,这种逻辑完全嵌入在 Flink 程序的应用逻辑中。预警由同一个程序生成,乱序事件由 Flink 自行处理。要从以固定时间分组改为根据产生数据的时间段分组,只需在 Flink 程序中修改对窗口的定义即可。此外,如果应用程序的代码有过改动,只需重播 Kafka 主题,即可重播应用程序。采用流处理架构,可以大幅减少需要学习、管理和编写代码的系统。Flink 应用程序代码示例:
DataStream<LogEvent> stream = env
// 通过Kafka生成数据流
.addSource(new FlinkKafkaConsumer(...))
// 分组
.keyBy("country")
// 将时间窗口设为60分钟
.timeWindow(Time.minutes(60))
// 针对每个时间窗口进行操作
.apply(new CountPerWindowFunction());在流处理中,主要有两个时间概念 :
事件时间,即事件实际发生的时间。更准确地说,每一个事件都有一个与它相关的时间戳,并且时间戳是数据记录的一部分。
处理时间,即事件被处理的时间。处理时间其实就是处理事件的机器所测量的时间。

以《星球大战》系列电影为例。首先上映的 3 部电影是该系列中的第 4、5、 6 部(这是事件时间),它们的上映年份分别是 1977 年、1980 年和 1983 年 (这是处理时间)。之后按事件时间上映的第 1、2、3、7 部,对应的处理时间分别是 1999 年、2002 年、2005 年和 2015 年。由此可见,事件流的顺序可能是乱的(尽管年份顺序一般不会乱)
通常还有第 3 个时间概念,即摄取时间,也叫作进入时间。它指的是事件进入流处理框架的时间。缺乏真实事件时间的数据会被流处理器附上时间戳,即流处理器第一次看到它的时间(这个操作由 source 函数完成,它是程序的第一个处理点)。
在现实世界中,许多因素(如连接暂时中断,不同原因导致的网络延迟, 分布式系统中的时钟不同步,数据速率陡增,物理原因,或者运气差)使 得事件时间和处理时间存在偏差(即事件时间偏差)。事件时间顺序和处理 时间顺序通常不一致,这意味着事件以乱序到达流处理器。
Flink 允许用户根据所需的语义和对准确性的要求选择采用事 件时间、处理时间或摄取时间定义窗口。
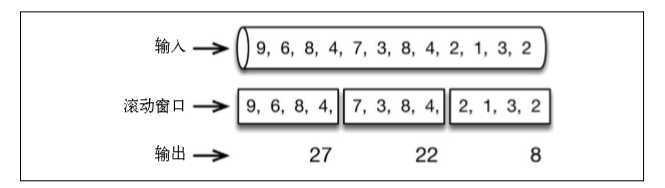
时间窗口是最简单和最有用的一种窗口。它支持滚动和滑动。
比如一分钟滚动窗口收集最近一分钟的数值,并在一分钟结束时输出总和:
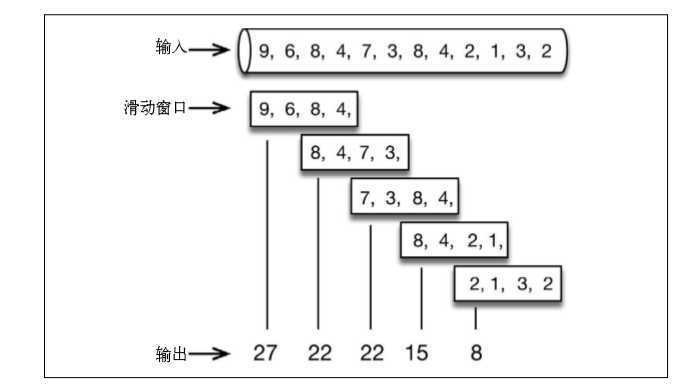
一分钟滑动窗口计算最近一分钟的数值总和,但每半分钟滑动一次并输出 结果:
在 Flink 中,一分钟滚动窗口的定义如下。
stream.timeWindow(Time.minutes(1))每半分钟(即 30 秒)滑动一次的一分钟滑动窗口如下所示。
stream.timeWindow(Time.minutes(1), Time.seconds(30))Flink 支持的另一种常见窗口叫作计数窗口。采用计数窗口时,分组依据不 再是时间戳,而是元素的数量。
滑动窗口也可以解释为由 4 个元素组成的计数窗口,并且每两个元素滑动一次。滚动和滑动的计数窗 口分别定义如下。
stream.countWindow(4)
stream.countWindow(4, 2)虽然计数窗口有用,但是其定义不如时间窗口严谨,因此要谨慎使用。时 间不会停止,而且时间窗口总会“关闭”。但就计数窗口而言,假设其定义 的元素数量为 100,而某个 key 对应的元素永远达不到 100 个,那么窗口就 永远不会关闭,被该窗口占用的内存也就浪费了。
Flink 支持的另一种很有用的窗口是会话窗口。会话窗口由超时时间设定,即希望等待多久才认为会话已经结束。
示例如下:
stream.window(SessionWindows.withGap(Time.minutes(5))除了窗口之外,Flink 还提供触发机制。触发器控制生成结果的时间,即何时聚合窗口内容并将结果返回给用户。每一个默认窗口都有一个触发器。 例如,采用事件时间的时间窗口将在收到水印时被触发。对于用户来说, 除了收到水印时生成完整、准确的结果之外,也可以实现自定义的触发器。
流处理架构的一个核心能力是时间的回溯机制。意味着将数据流倒回至过去的某个时间,重新启动处理程序,直到处理至当前时间为止。 Kafka支持这种能力。
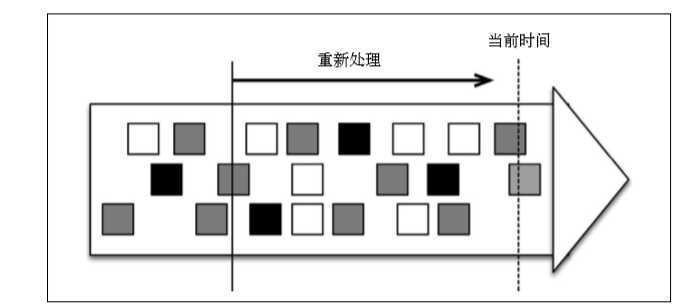
实时流处理总是在处理最近的数据(即图中“当前时间”的数据),历史流处理 则从过去开始,并且可以一直处理至当前时间。流处理器支持事件时间, 这意味着将数据流“倒带”,用同一组数据重新运行同样的程序,会得到相同的结果。
Flink 通过水印来推进事件时间。水印是嵌在流中的常规记录,计算程序通 过水印获知某个时间点已到。收到水印的窗口就知道 不会再有早于该时间的记录出现,因为所有时间戳小于或等于该时间的事 件都已经到达。这时,窗口可以安全地计算并给出结果(总和)。水印使事 件时间与处理时间完全无关。迟到的水印(“迟到”是从处理时间的角度而言)并不会影响结果的正确性,而只会影响收到结果的速度。
水印由应用程序开发人员生成,这通常需要对相应的领域有 一定的了解。完美的水印永远不会错:时间戳小于水印标记时间的事件不会再出现。
如果水印迟到得太久,收到结果的速度可能就会很慢,解决办法是在水印 到达之前输出近似结果(Flink 可以实现)。如果水印到达得太早,则可能收到错误结果,不过 Flink 处理迟到数据的机制可以解决这个问题。
相关文章:
Streaming-大数据的未来
以上为Flink对于时间的处理,更多实时计算,Flink,Kafka等相关技术博文,欢迎关注实时流式计算:

标签:现在 原因 引入 没有 框架 分割 pre 聚合 com
原文地址:https://www.cnblogs.com/tree1123/p/11445851.html