标签:alert plain serve 搭建 文件 min trunc root efault
随着zabbix的广泛应用,少数人的zabbix服务器在性能上出现瓶颈,或者在未来会出现性能方面的瓶颈,接下来讨论几个有效并且简单的优化方案。
想通过几个简单的配置让服务器提高成倍的性能,想法很好,但是基本不太现实。简单的说,你需要搭配更好的CPU、更大的内存,更快的硬盘:条件允许的花,可以考虑购买SSD,它比更大的cpu和更大的内存带来的效果更好,或者考虑使用SAS 15K硬盘,组raid等等,总之一句话,配置优化不动的情况,增加硬件投入,别绞尽脑汁搜索:zabbix如何优化之类的文章,你在浪费时间。
使用最新的操作系统,优化、定制化操作系统内核。应该会有些作用,但是肯定不大。
DBsock优化
如果MySQL和zabbix server在同一台服务器上,socket连接要比tcp连接要更快。
数据库分离
将数据库服务器独立,数据库和zabbix资源互相独立,例如:可以购买一台RDS
数据库引擎
使用MySQL5.6或者更高版本,自从MySQL被Oracle收购了,它的性能确实有不少的提升。请一定选择innodb,别选择myisam,因为zabbix在innodb的性能比在myisam快1.5倍,而且myisam不安全,zabbix监控数据量很大,一旦表坏了,那就是一个悲剧。
mysql分区,history等等表数据量较大,可以试着分区替身性能。
1、减少history保存时间
2、减少item获取间隔时间
3、减少不必要的监控项
在条件不允许或者以上方法都无效的情况下,请一定考虑以上建议。在监控环境中,以上三点是大家都在犯的错误,大部分item是不需要保存太长的数据,有些监控项根本无意义,有些监控项的间隔时间太短。一直以来我都在犯这个错,但是因为zabbix性能一直不错,暂时不纠正,数据多点总比少点好,是不是~
a.通过Zabbix agent采集数据的设备处于moniting的状态但是此时机器死机或其他原因导致zabbix agent死掉server获取不到数据,此时unreachable poller
就会升高。
b.通过Zabbix agent采集数据的设备处于moniting的状态但是server向agent获取数据时时间过长,经常超过server甚至的timeout时间,此时unreachable poller就会升高。
如何度量Zabbix性能:
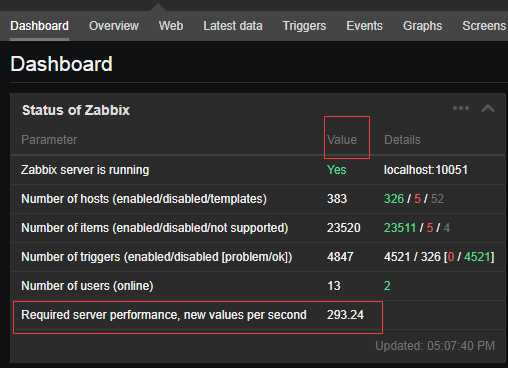
通过Zabbix的NVPS(每秒处理数值数)来衡量其性能。在Zabbix的dashboard上有一个错略的估值。

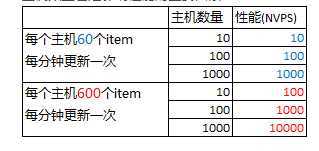
获得zabbix内部状态
zabbix[wcache,values,all]
zabbix[queue,1m] ----延迟超过1分钟的item
获得zabbix内部组件工作状态(该组件处于BUSY状态的时间百分比)
zabbix[process,type,mode,state]
其中可用的参数为:
主要讲讲采用主动模式,若采用active checks模式:
①zabbix_agentd.conf配置调整
|
1
2
3
4
5
6
7
8
|
LogFile=/tmp/zabbix_agentd.logServer=xxx.xxx.xxx.xxx server端ipServerActive=xxx.xxx.xxx.xx 指定Agentd收集的数据往哪里发送Hostname=yyy.yyy.yyy.yyy agent的hostname ,必须要和Server端添加主机时的主机名对应RefreshActiveChecks=60BufferSize=10000MaxLinesPerSecond=200Timeout=30 |
比较重要的参数是ServerActive和Hostname,ServerActive是指定Agentd收集的数据往哪里发送,Hostname是必须要和Server端添加主机时的主机名对应起来,这样Server端接收到数据才能找到对应关系,这里为了兼容被动模式,没有把StartAgents设为0,如果一开始就是使用主动模式的话建议把StartAgents设为0,关闭被动模式。
②zabbix_server.conf 配置调整
StartPollers=100 减少主动收集数据进程,由原来的500---100,减小
StartTrappers=200 负责处理Agentd推送过来的数据的进程,由原来的50---100 ,变大
③模板调整
a. 以任何一个现有模板为例,clone并重命名,假如重命名模板为TEST
b. 将模板TEST里所有items和discovery rules里的items都变更type为atvice agent
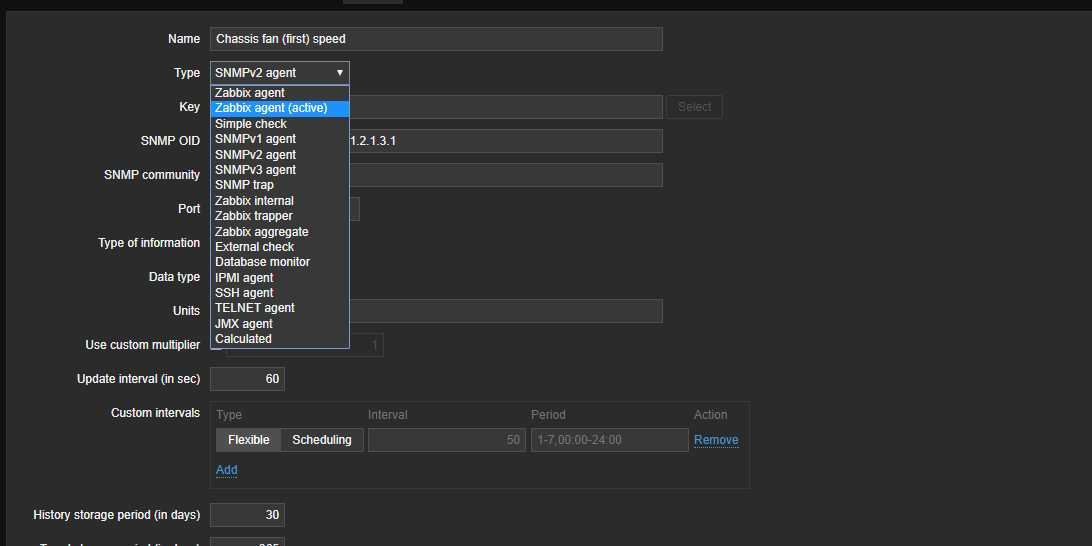
至此active-checks模式的agent部署完毕,可以在overview中查看模板中的监控项。
Tigger中正则表达式函数last()、nodata()的速度是最快的。。。Min()、max()、avg()是最慢的。。。尽量使用速度快的函数
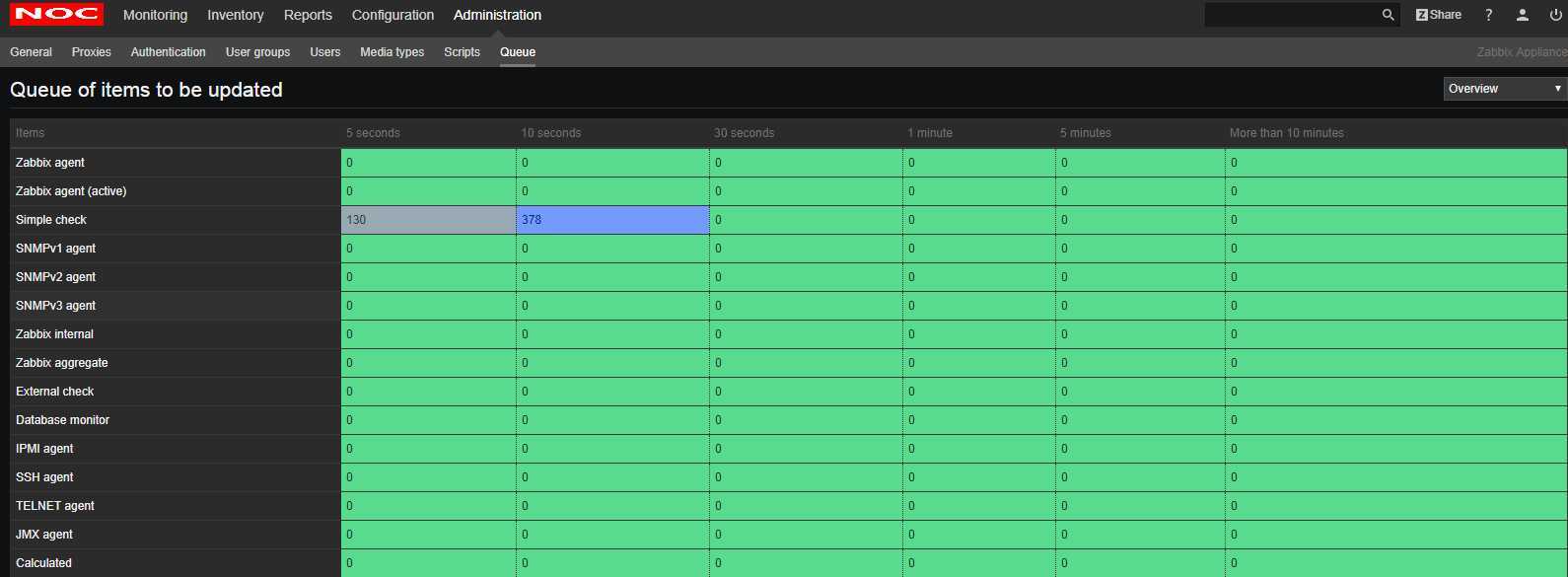
通过以下图,可看出哪个item导致慢: 若more than 10 min 有数据则表示对应的Item数据量过大。
解决办法:
备注:
调整unsupport items检查时间的方法是:在Adiministration里选择General然后在右侧下拉菜单里选择Other,然后修改Refresh unsupported items (in sec)的值,表示“每多少秒去重新检查一下那些not_supported的值”。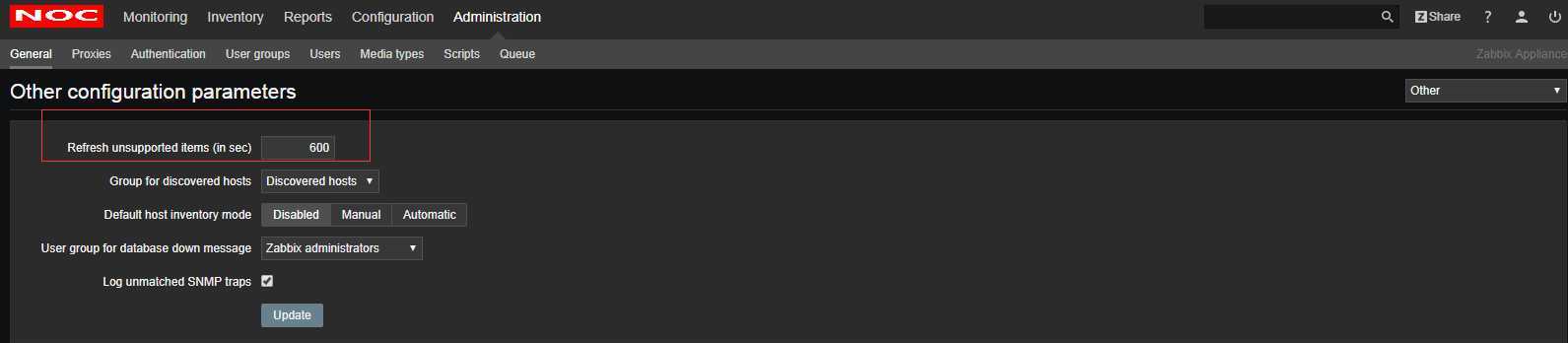
采用分布式架构,性能瓶颈的最大可能出现在数据库中。
起因:近几日zabbix报警的恢复时间变得很长,页面有卡顿的现象。抓包查看发现,确实是收到了最近正常的值,但是面板不更新,重新zabbix_server进程,才能完成面板更新。
1. Zabbix性能概述
当zabbix性能低时会出现多种状况,Zabbix前端页面出现无响应、卡顿、列队无法更新,zabbix图形中经常出现断图,无图。一些item获取不到数据。列队中出现大多被延迟的item
如何判断zabbix-server性能
首页导航中通过zabbix状态可以看到zabbix的主机数量、监控项的数目、触发器的数目。并通过zabbix的NVPS(每秒处理数值数)衡量性能标准,NVPS是通过PHP代码编写实现的计算,从总体上反映出了zabbix-server的处理速度。
NVPS与History的保留时间和Trends的保留时间都有直接关系。如下图中zabbix状态性能提升空间还很大,可以调整主机模版、修改被禁用和不支持的监控项及触发器。
我这里因为服务器比较老,再加上zabbix,mysql都是比较老的所以数字会很低
可以通过看zabbix对于本身server列队的监控,来确定是什么类型的监控项造成的性能问题,见下图。等待的列队越多、时间越长,说明zabbix-server性能越差。可以针对受影响的监控类型做调整,比如调整监控项的时间间隔,或者根据监控类型定制模版,将模版写到最简。如果以上方法还是没有效果,那么就说明zabbix server压力过大,采用搭建proxy分布式架构,将server的压力分担给proxy
上图是我调整后的
调整前
从上图可以看出有几个监控项延迟达到3年。。。。。
先将这几个延迟超长的监控项禁用掉,完事看看队列是否有变化
2. Zabbix配置文件优化
Zabbix自带模版还会监控各工作进程的状态,可对数据收集过程中的性能做分析,见下图,数据采集过程和使用缓存的空间容量。需要特别注意的有:
Zabbix busy housekeeper processes,in %##管家处理数据占缓存的百分比
Zabbix busy history syncer processes,in %##写入数据库的同步程序占缓存的百分比
Zabbix busy poller processes,in % ## zabbix轮询进程占比
Zabbix busy unreachable poller processes in %##不可达的轮询进程占比
root@localhost ~]# vim /etc/zabbix/zabbix_server.conf
#配置文件前面内容为初始安装zabbix时需要配置的基本参数。找到高级配置这一行开始,涉及优化内容用红色标识填充
############ ADVANCED PARAMETERS #################
### Option: StartPollers
# Number of pre-forked instances of pollers.
#
# Mandatory: no
# Range: 0-100
# Default:
StartPollers=5
#填写范围0-100,默认5 。轮询处理监控项的进程数,增加太大会影响服务器本身性能,保持此参数的值尽可能低,20000个监控项大概控制在80左右即可。
StartIPMIPollers=0
#IPMI轮询进程实例个数,服务器使用IPMI协议监控时需要更改此项,默认0为关闭
StartPollersUnreachable=10
#不可达主机轮询数量。此值特别耗费性能,设置在10-20之间即可,默认1
StartTrappers=5
#负责处理agents和proxy推送过来的数据的进程数,默认为5,如果zabbix-agent监控类型较多需要加大此参数
StartPingers=1
# ICMP- ping进程轮询实例数,默认为1.,建议更改为20-50之间,根据业务填写即可。
StartDiscoverers=1
#自动发现子进程实例数,默认为1,范围0-250
StartHTTPPollers=1
#HTTP进程轮询实例个数,默认1,范围0-1000,web监控不多选择默认即可
HousekeepingFrequency=1
#zabbix执行管家的频率,从数据库中删除过期的数据。为了防止 housekeeper 过载 (例如, 当历史和趋势周期大大减小时), 对于每一个item,不会在一个housek周期内删除超过4倍HousekeepingFrequency 的过时信息. 因此, 如果 HousekeepingFrequency 是 1, 一个周期内不会删除超过4小时的过时信息,为了降低server压力,kousekeeping延后server启动30分钟,默认为1,最大24,为0时关闭使用。
MaxHousekeeperDelete=5000
#执行一个Housekeeping周期时,默认删除的数据条目数。默认5000条。如果设置为0,不限制删除的行数,这种情况数据库多数会崩溃。
CacheSize=8M
#缓存大小,单位字节。用于存储主机、监控项、触发器数据的共享内存大小,默认8M最大8G。根据自身zabbix业务需求配置合理的参数。
CacheUpdateFrequency=60
#zabbix缓存更新频率,单位秒。设置范围1-3600
HistoryCacheSize=1024M
#历史数据缓存大小,单位字节
TrendCacheSize=256M
#趋势数据缓存大小,单位字节。用于存储趋势数据的共享内存大小
ValueCacheSize=1024M
#历史数据缓存大小, 单位bytes.缓存item历史数据请求的共享内存大小.0即禁止缓存(不建议这么做)
Timeout=3
#agent, SNMP 设备或外部检查的超时时长(单位秒),填写范围1-30
以上为配置优化主要参数,其他内容配置文件中均有简要说明,可根据业务需求更改优化。对配置参数进行合理的设置会使zabbix处于正常的工作状态。值越大,越高消耗的CPU和内存越多。修改配置文件后,需要重启zabbix-server进程。加载新配置生效
当以上方法不能有效时,建议清楚一下趋势数据。当然如果有保存的需求,那就只能做分片了(本文不涉及分片)。
truncate table history;
truncate table history_str;
truncate table history_uint;
truncate table trends;
truncate table trends_uint;
标签:alert plain serve 搭建 文件 min trunc root efault
原文地址:https://www.cnblogs.com/xuefy/p/11447956.html