标签:分而治之 context strong col 技术 bsp value code 统计
MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
MapReduce的工作原理
在分布式计算中,MapReduce框架负责处理了并行编程里分布式存储、工作调度,负载均衡、容错处理以及网络通信等复杂问题,现在我们把处理过程高度抽象为Map与Reduce两个部分来进行阐述,其中Map部分负责把任务分解成多个子任务,Reduce部分负责把分解后多个子任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中输入的value值存储的是文本文件中的一行(以回车符为行结束标记),而输入的key值存储的是该行的首字母相对于文本文件的首地址的偏移量。然后用StringTokenizer类将每一行拆分成为一个个的字段,把截取出需要的字段(本实验为买家id字段)设置为key,并将其作为map方法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出的<key,value>键值对先经过shuffle过程把key值相同的所有value值聚集起来形成values,此时values是对应key字段的计数值所组成的列表,然后将<key,values>输入到reduce方法中,reduce方法只要遍历values并求和,即可得到某个单词的总次数。
在main()主函数中新建一个Job对象,由Job对象负责管理和运行MapReduce的一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。本实验是设置使用将继承Mapper的doMapper类完成Map过程中的处理和使用doReducer类完成Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由字符串指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务,其余的工作都交由MapReduce框架处理。
实现内容:现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t”【注:实际代码中改成了四个空格】分割,样本数据及格式如下:
买家id 商品id 收藏日期 10181 1000481 2010-04-04 16:54:31 20001 1001597 2010-04-07 15:07:52 20001 1001560 2010-04-07 15:08:27 20042 1001368 2010-04-08 08:20:30 20067 1002061 2010-04-08 16:45:33 20056 1003289 2010-04-12 10:50:55 20056 1003290 2010-04-12 11:57:35 20056 1003292 2010-04-12 12:05:29 20054 1002420 2010-04-14 15:24:12 20055 1001679 2010-04-14 19:46:04 20054 1010675 2010-04-14 15:23:53 20054 1002429 2010-04-14 17:52:45 20076 1002427 2010-04-14 19:35:39 20054 1003326 2010-04-20 12:54:44 20056 1002420 2010-04-15 11:24:49 20064 1002422 2010-04-15 11:35:54 20056 1003066 2010-04-15 11:43:01 20056 1003055 2010-04-15 11:43:06 20056 1010183 2010-04-15 11:45:24 20056 1002422 2010-04-15 11:45:49 20056 1003100 2010-04-15 11:45:54 20056 1003094 2010-04-15 11:45:57 20056 1003064 2010-04-15 11:46:04 20056 1010178 2010-04-15 16:15:20 20076 1003101 2010-04-15 16:37:27 20076 1003103 2010-04-15 16:37:05 20076 1003100 2010-04-15 16:37:18 20076 1003066 2010-04-15 16:37:31 20054 1003103 2010-04-15 16:40:14 20054 1003100 2010-04-15 16:40:16
编写MapReduce程序,统计每个买家收藏商品数量。统计结果数据如下:
买家id 商品数量 10181 1 20001 2 20042 1 20054 6 20055 1 20056 12 20064 1 20067 1 20076 5
该mapreduce的执行过程:
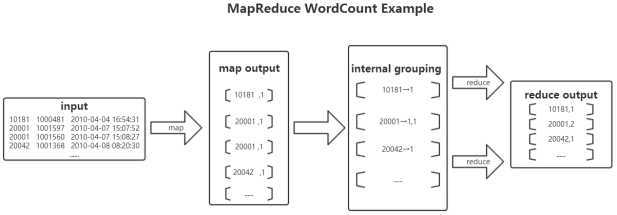
实现思路:将hdfs上的文本作为输入,MapReduce通过InputFormat会将文本进行切片处理(按行读入),并将每行的首字母相对于文本文件的首地址的偏移量作为输入键值对的key,文本内容作为输入键值对的value,经过在map函数处理,输出中间结果<word,1>的形式,并在reduce函数中完成对每个单词的词频统计。
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { // Mapper四个参数:第一个Object表示输入key的类型;第二个Text表示输入value的类型;第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型。map这里的输出是指输出到reduce public static class doMapper extends Mapper<Object, Text, Text, IntWritable> { public static final IntWritable one = new IntWritable(1);//这里的IntWritable相当于Int类型 public static Text word = new Text();//Text相当于String类型 // map参数<keyIn key,valueIn value,Context context>,将处理后的数据写入context并传给reduce protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { //StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分 StringTokenizer tokenizer = new StringTokenizer(value.toString(), " "); //返回当前位置到下一个分隔符之间的字符串 word.set(tokenizer.nextToken()); //将word存到容器中,记一个数 context.write(word, one); } } //参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型。这里的输入是来源于map,所以类型要与map的输出类型对应 。 public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; //for循环遍历,将得到的values值累加 for (IntWritable value : values) { sum += value.get(); } result.set(sum); context.write(key, result);//将结果保存到context中,最终输出形式为"key" + "result" } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { System.out.println("start"); Job job = Job.getInstance(); job.setJobName("wordCount"); Path in = new Path("hdfs://***:9000/user/hadoop/input/buyer_favorite1.txt");//设置这个作业输入数据的路径(***部分为自己liunx系统的localhost或者ip地址) Path out = new Path("hdfs://***:9000/user/hadoop/output/wordCount"); //设置这个作业输出结果的路径 FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); job.setJarByClass(WordCount.class);// 设置运行/处理该作业的类 job.setMapperClass(doMapper.class);//设置实现了Map步的类 job.setReducerClass(doReducer.class);//设置实现了Reduce步的类 job.setOutputKeyClass(Text.class);//设置输出结果key的类型 job.setOutputValueClass(IntWritable.class);//设置输出结果value的类型 ////执行作业 System.exit(job.waitForCompletion(true) ? 0 : 1); System.out.println("end"); } }
最后附上林子雨大数据教程中的WordCount例子示意图以加深理解


标签:分而治之 context strong col 技术 bsp value code 统计
原文地址:https://www.cnblogs.com/ssyh/p/11447559.html