标签:process tps 发送数据 项目 结束 意义 重复 状态 ssi
Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理。通常用于实时分析,在线机器学习、持续计算、分布式 RPC、ETL 等场景。Storm 具有以下特点:
Hadoop 采用 MapReduce 处理数据,而 MapReduce 主要是对数据进行批处理,这使得 Hadoop 更适合于海量数据离线处理的场景。而 Strom 的设计目标是对数据进行实时计算,这使得其更适合实时数据分析的场景。
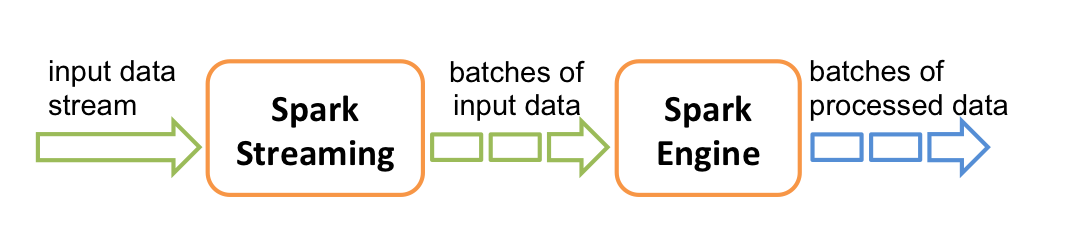
Spark Streaming 并不是真正意义上的流处理框架。 Spark Streaming 接收实时输入的数据流,并将数据拆分为一系列批次,然后进行微批处理。只不过 Spark Streaming 能够将数据流进行极小粒度的拆分,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
storm 和 Flink 都是真正意义上的实时计算框架。其对比如下:
| storm | flink | |
|---|---|---|
| 状态管理 | 无状态 | 有状态 |
| 窗口支持 | 对事件窗口支持较弱,缓存整个窗口的所有数据,窗口结束时一起计算 | 窗口支持较为完善,自带一些窗口聚合方法, 并且会自动管理窗口状态 |
| 消息投递 | At Most Once At Least Once |
At Most Once At Least Once Exactly Once |
| 容错方式 | ACK 机制:对每个消息进行全链路跟踪,失败或者超时时候进行重发 | 检查点机制:通过分布式一致性快照机制, 对数据流和算子状态进行保存。在发生错误时,使系统能够进行回滚。 |
注 : 对于消息投递,一般有以下三种方案:
- At Most Once : 保证每个消息会被投递 0 次或者 1 次,在这种机制下消息很有可能会丢失;
- At Least Once : 保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失;
- Exactly Once : 每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
在流处理之前,数据通常存储在数据库或文件系统中,应用程序根据需要查询或计算数据,这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
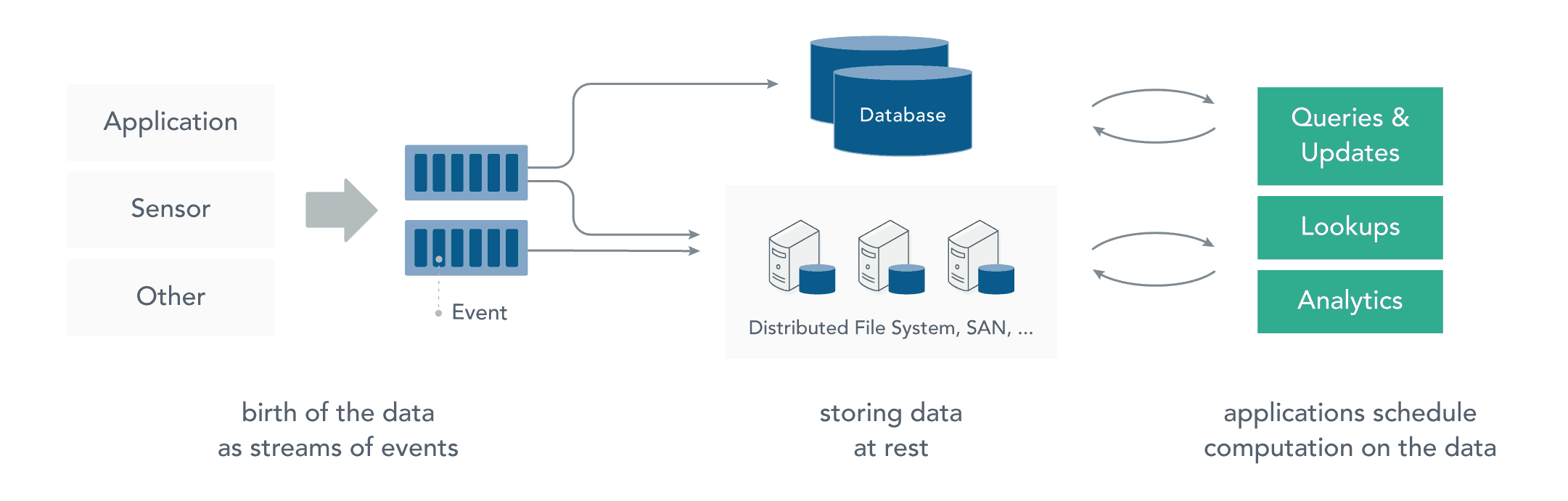
而流处理则是直接对运动中数据的处理,在接收数据的同时直接计算数据。实际上,在真实世界中的大多数数据都是连续的流,如传感器数据,网站用户活动数据,金融交易数据等等 ,所有这些数据都是随着时间的推移而源源不断地产生。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
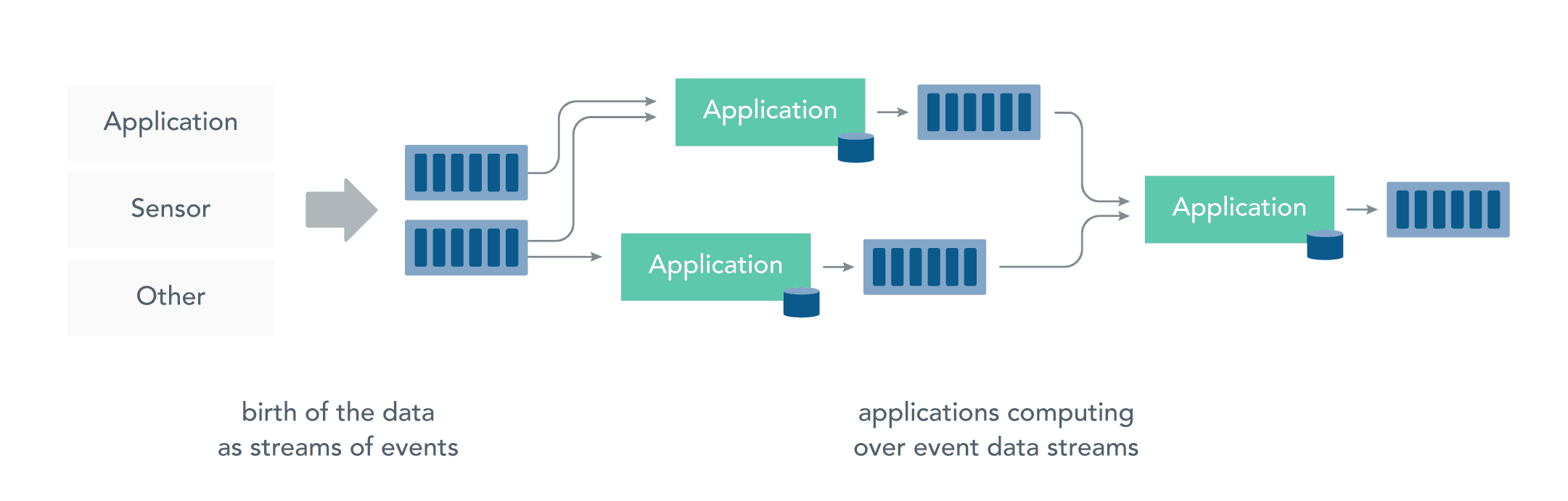
流处理带来了很多优点:
可以立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,然后将其传送到下一个处理单元,通过逐级过滤数据,从而降低实际需要处理的数据量;
更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,想要通过历史数据推断未来的趋势,必须保证数据的不断输入和模型的持续修正,典型的就是金融市场、股票市场,流处理能更好地处理这些场景下对数据连续性和及时性的需求;
分散和分离基础设施:流式处理减少了对大型数据库的需求。每个流处理程序通过流处理框架维护了自己的数据和状态,这使其更适合于当下最流行的微服务架构。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
标签:process tps 发送数据 项目 结束 意义 重复 状态 ssi
原文地址:https://www.cnblogs.com/heibaiying/p/11450828.html