标签:运维 改名 break version 动态 size 定时任务 结构 基本概念
概述
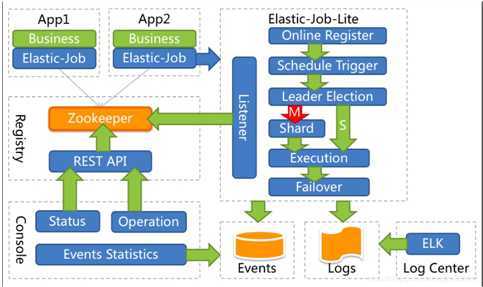
Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。
功能列表
分布式调度协调
弹性扩容缩容
失效转移
错过执行作业重触发
作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
自诊断并修复分布式不稳定造成的问题
支持并行调度
支持作业生命周期操作
丰富的作业类型
Spring整合以及命名空间提供
运维平台
基本概念
1. 分片概念
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
例如:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
2. 分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系。
3. 个性化参数的适用场景
个性化参数即shardingItemParameter,可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库A是北京的数据;数据库B是上海的数据;数据库C是广州的数据。 如果仅按照分片项配置,开发者需要了解0表示北京;1表示上海;2表示广州。 合理使用个性化参数可以让代码更可读,如果配置为0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
核心理念
1. 分布式调度
Elastic-Job-Lite并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。
注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
2. 作业高可用
Elastic-Job-Lite提供最安全的方式执行作业。将分片总数设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。
一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业执行时崩溃,备机立即启动替补执行。
3. 最大限度利用资源
Elastic-Job-Lite也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
整体架构图
引入依赖
<!-- 引入elastic-job-lite核心模块 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${latest.release.version}</version>
</dependency>
作业开发
public class MyElasticJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
switch (context.getShardingItem()) {
case 0:
// do something by sharding item 0
break;
case 1:
// do something by sharding item 1
break;
case 2:
// do something by sharding item 2
break;
// case n: ...
}
}
}
作业配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<!--配置作业注册中心 -->
<reg:zookeeper id="regCenter" server-lists="yourhost:2181" namespace="dd-job" base-sleep-time-milliseconds="1000" max-sleep-time-milliseconds="3000" max-retries="3" />
<!-- 配置作业-->
<job:simple id="oneOffElasticJob" class="xxx.MyElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
</beans>
实现原理
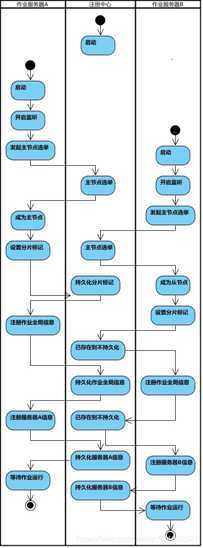
弹性分布式实现
第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
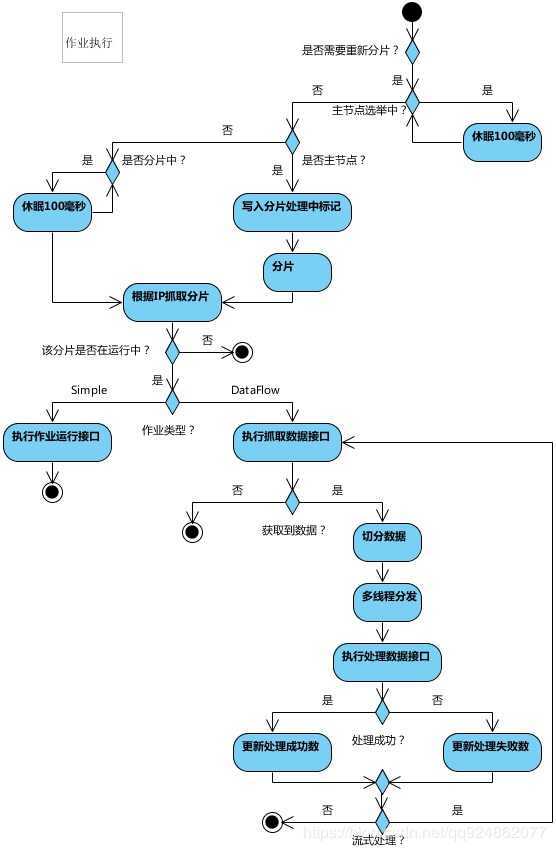
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
注册中心数据结构
注册中心在定义的命名空间下,创建作业名称节点,用于区分不同作业,所以作业一旦创建则不能修改作业名称,如果修改名称将视为新的作业。作业名称节点下又包含4个数据子节点,分别是config, instances, sharding, servers和leader。
config节点
作业配置信息,以JSON格式存储
instances节点
作业运行实例信息,子节点是当前作业运行实例的主键。作业运行实例主键由作业运行服务器的IP地址和PID构成。作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心监控这些节点的变化来协调分布式作业的分片以及高可用。 可在作业运行实例节点写入TRIGGER表示该实例立即执行一次。
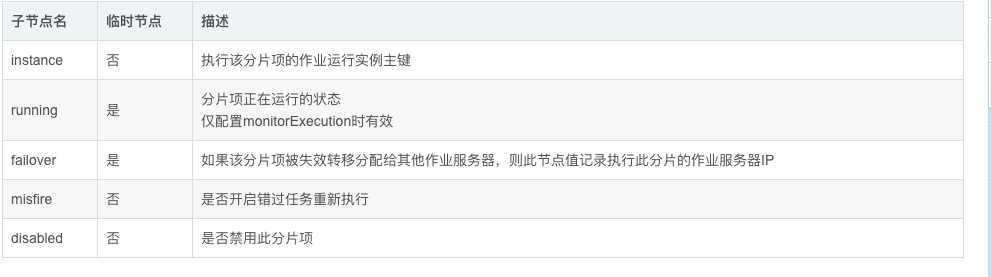
sharding节点
作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。节点详细信息说明
servers节点
作业服务器信息,子节点是作业服务器的IP地址。可在IP地址节点写入DISABLED表示该服务器禁用。 在新的cloud native架构下,servers节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。为了更加纯粹的实现job核心,servers功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
leader节点
作业服务器主节点信息,分为election,sharding和failover三个子节点。分别用于主节点选举,分片和失效转移处理。
leader节点是内部使用的节点。

流程图
启动
作业分片策略
框架提供的分片策略
AverageAllocationJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。如:
如果有3台服务器,分成9片,则每台服务器分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
OdevitySortByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.OdevitySortByNameJobShardingStrategy
策略说明:
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP升序。
作业名的哈希值为偶数则IP降序。
用于不同的作业平均分配负载至不同的服务器。
AverageAllocationJobShardingStrategy的缺点是,一旦分片数小于作业服务器数,作业将永远分配至IP地址靠前的服务器,导致IP地址靠后的服务器空闲。而OdevitySortByNameJobShardingStrategy则可以根据作业名称重新分配服务器负载。如:
如果有3台服务器,分成2片,作业名称的哈希值为奇数,则每台服务器分到的分片是:1=[0], 2=[1], 3=[]
如果有3台服务器,分成2片,作业名称的哈希值为偶数,则每台服务器分到的分片是:3=[0], 2=[1], 1=[]
RotateServerByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.RotateServerByNameJobShardingStrategy
策略说明:
根据作业名的哈希值对服务器列表进行轮转的分片策略。
自定义分片策略
实现JobShardingStrategy接口并实现sharding方法,接口方法参数为作业服务器IP列表和分片策略选项,分片策略选项包括作业名称,分片总数以及分片序列号和个性化参数对照表,可以根据需求定制化自己的分片策略。
欢迎将分片策略以插件的形式贡献至com.dangdang.ddframe.job.lite.api.strategy包。
配置分片策略
与配置通常的作业属性相同,在spring命名空间或者JobConfiguration中配置jobShardingStrategyClass属性,属性值是作业分片策略类的全路径。
参考:https://blog.csdn.net/qq924862077/article/details/82956790
标签:运维 改名 break version 动态 size 定时任务 结构 基本概念
原文地址:https://www.cnblogs.com/xyj179/p/11451680.html