标签:文本相似度 coding 去掉 style 频率 总数 import 马云 category
假设有一份文本数据如下,数据量很大,现在要对整个语料库进行文本分析,category代表新闻种类,theme代表新闻主题,URL代表新闻链接地址,content代表新闻主题内容
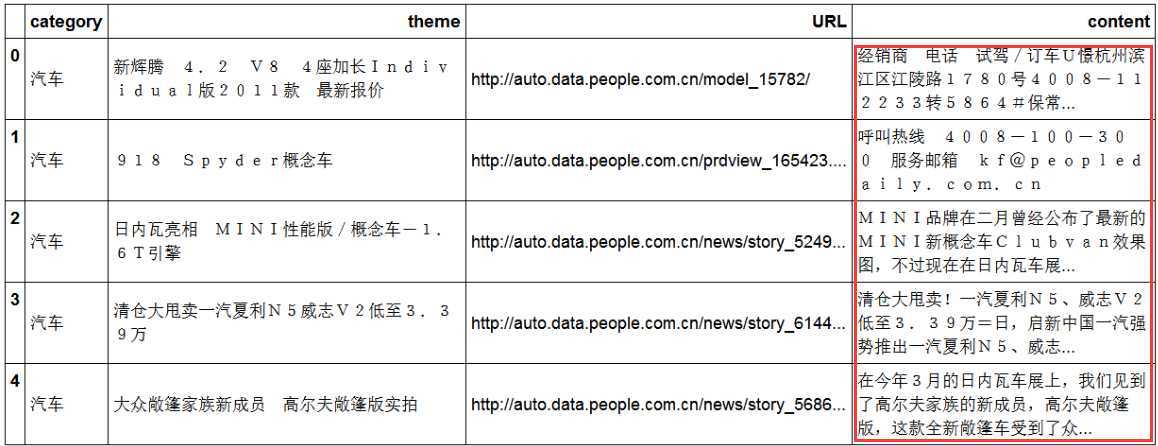
停用词:在content这一列,在数据量很大的情况,很容易发现某些似乎与新闻本身意义不大的词大量出现,而我们就把这些在语料库中大量出现但是又没啥大用的词叫做停用词,在数据集链接中包含一份常见的停用词,如下所示:

TF-IDF:用于关键词提取。比如在一篇名叫《中国的蜜蜂养殖》这篇文章中进行词频(Term Frequency,缩写为TF)统计出现次数最多的词是“的”、“是”、“在”等这一类最常用的词(停用词,一般来说是要去掉的),在删除掉停用词过后我们发现“中国”、“蜜蜂”、“养殖”这三个词的出现次数一样多,那么这三个词的重要性是一样的吗?一般来说"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。这时就需要引入一个叫做逆文档频率来进行衡量。"逆文档频率"(Inverse Document Frequency,缩写为IDF)如果某个词相比较于整个语料库来说比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,那它正是我们所需要的关键词。
计算公式

TF-IDF = 词频(TF) * 逆文档频率(IDF)。还是在《中国的蜜蜂养殖》这篇文章中:假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数(也就是语料库)。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。
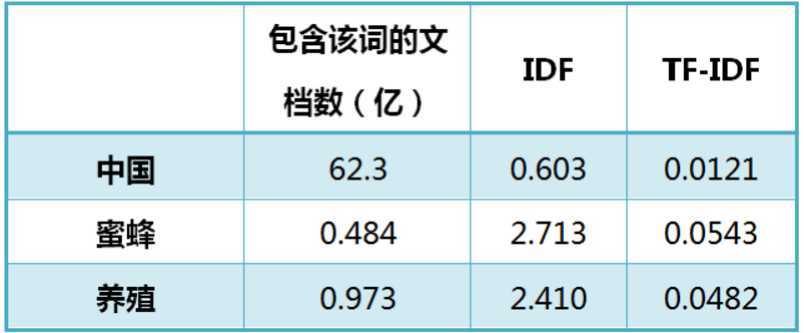
可以看出蜜蜂和养殖的TF-IDF值比中国这个词大,那么这篇文章的关键词重要性依次为蜜蜂、养殖和中国。
文本相似度:假设有如下两个句子A、B,我们该怎么判断这两个句子的相似度呢
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
先进行分词来看一下。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
可以得到整个语料库:我,喜欢,看,电视,电影,不,也。
然后进行词频的统计
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
这样就可以得出词频向量
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
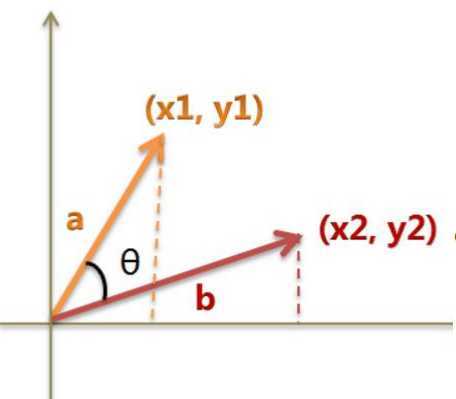
相似度计算方法:最常用通过余弦进行计算
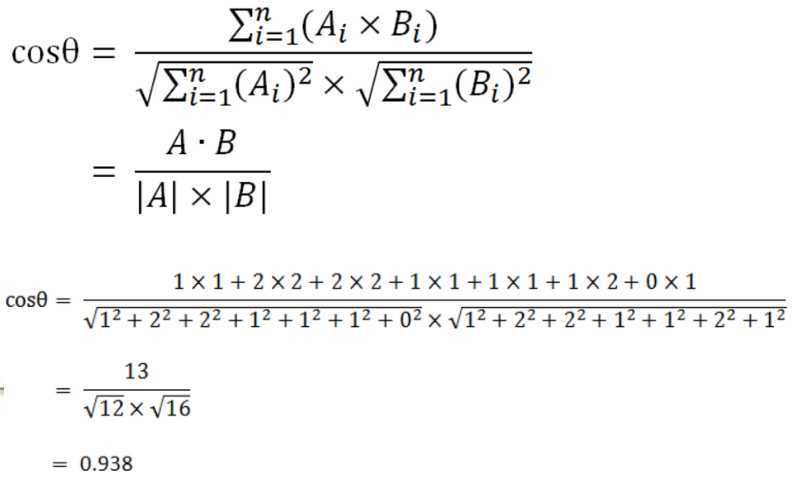
现在我们手里一份新闻数据,数据里面包含新闻的内容以及新闻的种类等等,我们要做的就是对新闻进行一个分类任务,比如说汽车类时尚类等等。
数据集链接:https://pan.baidu.com/s/1fG_oagJT69bIgCZgasn_Ig 提取码:yzd0
导入相关的python库
import pandas as pd import jieba # 如果没有这个库可能需要手动安装
读取数据集并删除缺失的数据集(缺失的数据很少,所以可以删除)
# read_table()读取以‘/t’分割的文件到DataFrame # 在实际使用中可以通过对sep参数的控制来对任何文本文件读取 df_news = pd.read_table(‘./data/val.txt‘,names=[‘category‘,‘theme‘,‘URL‘,‘content‘],encoding=‘utf-8‘) df_news = df_news.dropna() # 删除缺失数据 df_news.head()
content为新闻的主体内容
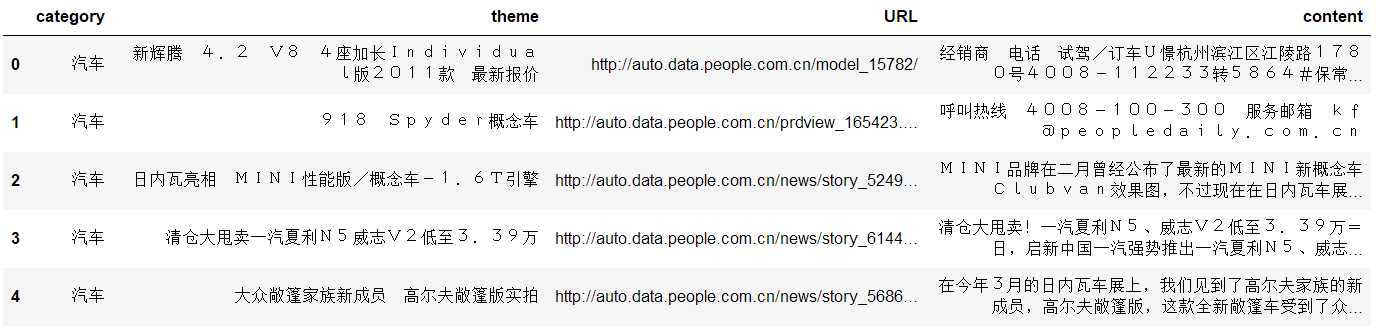
查看数据集维度
df_news.shape
得到的结果
(5000, 4)
将新闻内容转换为list方便进行分词并查看第1000条数据内容
content = df_news.content.values.tolist() # 转换为list 实际上是二维list print(content[1000])
内容为:
阿里巴巴集团昨日宣布,将在集团管理层面设立首席数据官岗位(Chief Data Officer),阿里巴巴B2B公
司CEO陆兆禧将会出任上述职务,向集团CEO马云直接汇报。>菹ぃ和6月初的首席风险官职务任命相同,首席数据官亦为阿
里巴巴集团在完成与雅虎股权谈判,推进“one company”目标后,在集团决策层面新增的管理岗位。0⒗锛团昨日表示
,“变成一家真正意义上的数据公司”已是战略共识。记者刘夏
下面使用python中的jieba库进行分词
content_S = []
for line in content:
# jieba分词 精确模式。返回一个列表类型,建议使用
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != ‘\r\n‘:
content_S.append(current_segment)
查看第1000条数据分词后的内容
content_S[1000]

转为pandas支持的DataFrame格式
df_content = pd.DataFrame({‘content_S‘:content_S}) # 转换为DataFrame
df_content.head()
分完词后的结果为:

可以发现数据里面包含很多无用的词汇,所以我们需要对这些数据进行清洗,就是删除掉里面包含的停用词
读取停用词表
# 读取停词表 stopwords = pd.read_csv(‘./data/stopwords.txt‘,index_col=False,sep=‘\t‘,quoting=3,names=[‘stopword‘],encoding=‘utf-8‘) stopwords.head()
结果为:
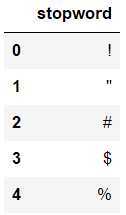
删除语料库中的停用词,这里面的all_words是为了后面的词云展示。
# 删除新闻中的停用词
def drop_stopwords(contents, stopwords):
contents_clean = [] # 删除后的新闻
all_words = [] # 构造词云所用的数据
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean, all_words
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
# 得到删除停用词后的新闻以及词云数据
contents_clean, all_words = drop_stopwords(contents, stopwords)
# df_content.content_S.isin(stopwords.stopword)
# df_content=df_content[~df_content.content_S.isin(stopwords.stopword)]
# df_content.head()
查看删除停用词后的新闻内容
df_content = pd.DataFrame({‘contents_clean‘:contents_clean})
df_content.head()
从结果可以看出,这次的数据对比上面的数据来说质量提高了很多。

查看一下出现的所有的词汇,也就是删除停用词后的all_words。
df_all_words = pd.DataFrame({‘all_words‘:all_words})
df_all_words.head()
结果为:
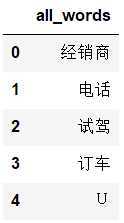
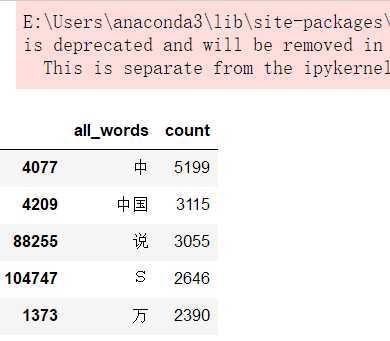
统计all_words每个词的词频,统计这个词频也是为了方便后面的词云展示。
import numpy
# 分组统计
words_count = df_all_words.groupby(by=[‘all_words‘])[‘all_words‘].agg({‘count‘:numpy.size})
# 根据count排序
words_count = words_count.reset_index().sort_values(by=[‘count‘],ascending=False)
words_count.head()
结果为:
导入wordcloud库以及画图展示
from wordcloud import WordCloud # 词云库
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams[‘figure.figsize‘] = (10.0,5.0)
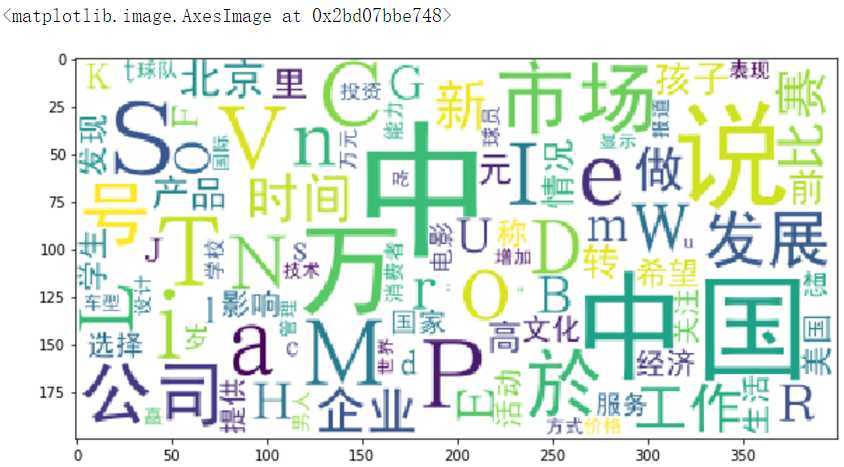
wordcloud = WordCloud(font_path=‘./data/simhei.ttf‘,background_color=‘white‘,max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values} # 这里只显示词频前100的词汇
wordcloud = wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
可视化结果为:
未完待续。。。
标签:文本相似度 coding 去掉 style 频率 总数 import 马云 category
原文地址:https://www.cnblogs.com/xiaoyh/p/11450479.html