标签:查找 二维 trie树 特定 com cond 技术 大小 title
• 一段文字不仅仅在于字面上是什么,还在于怎么切分和理解。
• 例如:
– 阿三炒饭店:
– 阿三 / 炒饭 / 店 阿三 / 炒 / 饭店
• 和英文不同,中文词之间没有空格,所以实现中文搜索引擎,比英文多了一项分
词的任务。
• 如果没有中文分词会出现:
– 搜索“达内”,会出现“齐达内”相关的信息
• 要解决中文分词准确度的问题,是否可以提供一个免费版本的通用分词程序?
– 像分词这种自然语言处理领域的问题,很难彻底完全解决
– 每个行业或业务侧重不同,分词工具设计策略也是不一样的

• 切开的开始位置对应位是1,否则对应位是0,来表示“有/意见/分歧”的bit内容是:11010
• 还可以用一个分词节点序列来表示切分方案,例如“有/意见/分歧”的分词节点序列是{0,1,3,5}
• 最常见的分词方法是基于词典匹配
– 最大长度查找(前向查找,后向查找)
• 数据结构
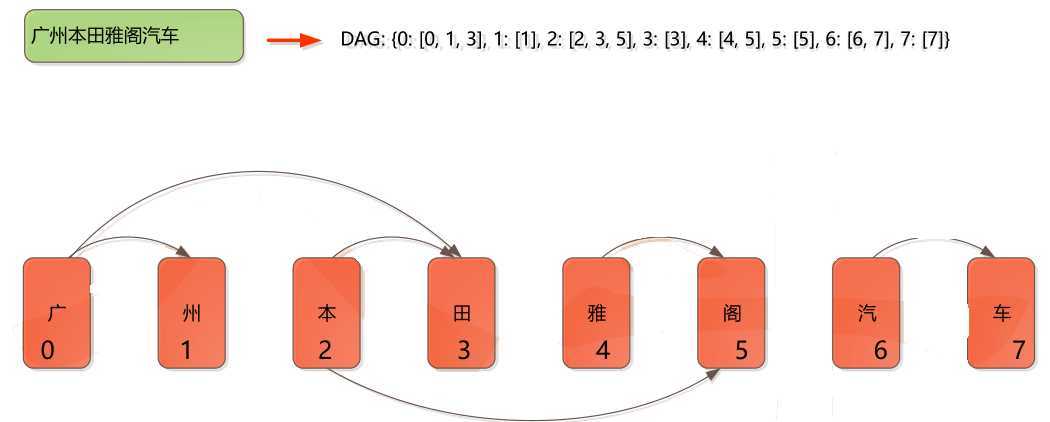
– 为了提高查找效率,不要逐个匹配词典中的词
– 查找词典所占的时间可能占总的分词时间的1/3左右,为了保证切分速度,需要选择一个好
的查找词典方法
– Trie树常用于加速分词查找词典问题
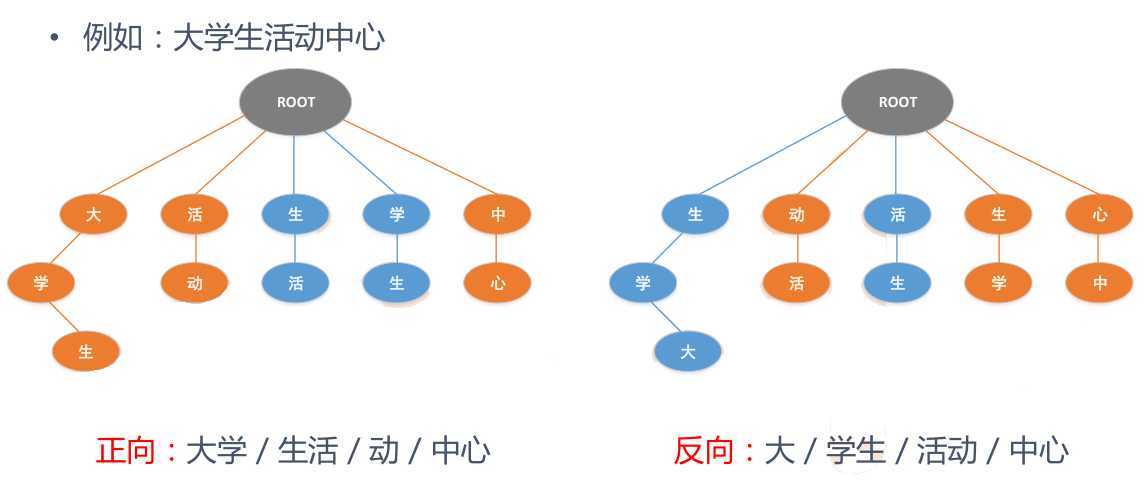
切分词图
• 假设需要分出来的词在语料库和词表中都存在,最简单的方法是按词计算概率,
而不是按字算概率。
• 从统计思想的角度来看,分词问题的输入是一个字串C=c1,c2……cn ,输出是一
个词串S=w1,w2……wm ,其中m<=n。对于一个特定的字符串C,会有多个切
分方案S对应,分词的任务就是在这些S中找出一个切分方案S,使得P(S|C)的值
最大。
• P(S|C)就是由字符串C产生切分S的概率,也就是对输入字符串切分出最有可能的
词序列
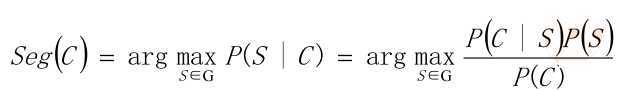
例子:
• 例如:对于输入字符串C“南京市长江大桥”,有下面两种切分可能:
– S1:南京市 / 长江 / 大桥
– S2:南京 / 市长 / 江大桥
• 这两种切分方法分别叫做S1和S2。计算条件概率P(S1|C)和P(S2|C),然后根据
P(S1|C)和P(S2|C)的值来决定选择S1还是S2。
• P(C)是字串在语料库中出现的概率。比如说语料库中有1万个句子,其中有一句
是 “南京市长江大桥”那么P(C)=P(“南京市长江大桥”)=万分之一。
• 因为P(C∩S) = P(S|C)*P(C) = P(C|S)*P(S),所以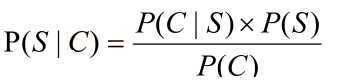
• 贝叶斯公式:
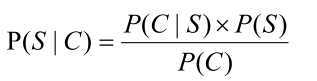
• P(C)只是一个用来归一化的固定值
• 另外:从词串恢复到汉字串的概率只有唯一的一种方式,所以P(C|S)=1。
• 所以:比较P(S1|C)和P(S2|C)的大小变成比较P(S1)和P(S2) 的大小
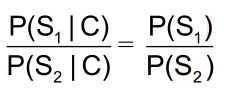
• 因为P(S1)=P(南京市,长江,大桥)=P(南京市)*P(长江)*P(大桥) > P(S2)=P(南京,市
长,江大桥),所以选择切分方案S1
例子三:
• 为了容易实现,假设每个词之间的概率是上下文无关的,则:
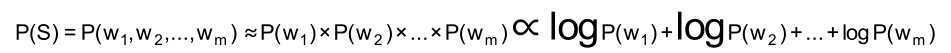
• 其中,P(w) 就是这个词出现在语料库中的概率。因为函数y=log(x),当x增大,
y也会增大,所以是单调递增函数。∝是正比符号。因为词的概率小于1,所以取
log后是负数。
• 最后算 logP(w)。取log是为了防止向下溢出,如果一个数太小,例如0.000000000000000000000000000001 可能会向下溢出。
• 如果这些对数值事前已经算出来了,则结果直接用加法就可以得到,而加法比乘法速度更快。
• 字符串X,长度为m,从1开始数;
• 字符串Y,长度为n,从1开始数;
• X i =<x 1 ,……,x i >即X序列的前i个字符(1<=i<=m)(X i 计作“字符串X的i前缀”)
• Y i =<y 1 ,……,y i >即Y序列的前i个字符(1<=j<=n)(Y j 计作“字符串Y的j前缀”)
• LCS(X,Y)为字符串X和Y的最长公共子序列,即为Z=<z 1 ,……,z k >
• 如果x m = y n (最后一个字符相同),则:X ? 与Y n 的最长公共子序列Z k 的最后一个字符必定为x m (= y n )
• Zk= x m = y n

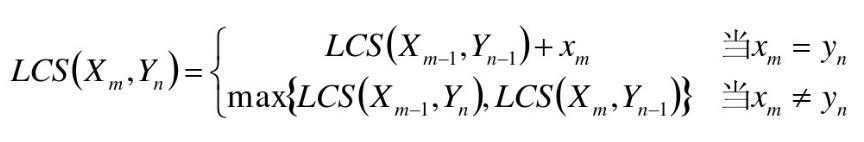
• 属于动态规划问题!
• 使用二维数组C[m,n]
• C[i,j]记录序列X i 和Y j 的最长公共子序列的长度
– 当i=0或j=0时,空虚了是X i 和Y j 的最长公共子序列,故C[i,j]=0
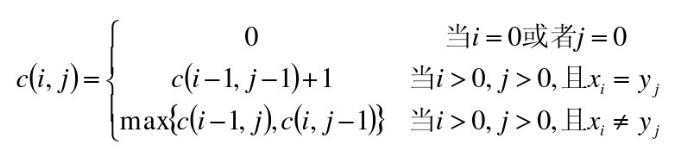
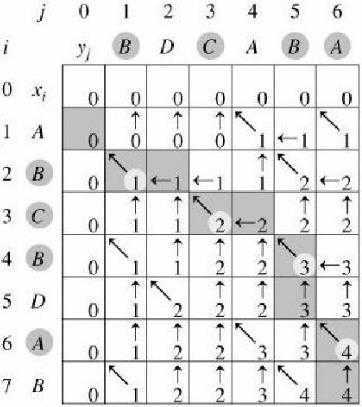
例子:
• X =<A, B, C, B, D, A, B>
• Y=<B, D, C, A, B, A>
mr_lcs mapreduce
##map.py
# -*- coding: utf-8 -*-
#!/usr/bin/python
import sys
def cal_lcs_sim(first_str, second_str):
len_vv = [[0] * 50] * 50
first_str = unicode(first_str, "utf-8", errors=‘ignore‘)
second_str = unicode(second_str, "utf-8", errors=‘ignore‘)
len_1 = len(first_str.strip())
len_2 = len(second_str.strip())
#for a in first_str:
#word = a.encode(‘utf-8‘)
for i in range(1, len_1 + 1):
for j in range(1, len_2 + 1):
if first_str[i - 1] == second_str[j - 1]:
len_vv[i][j] = 1 + len_vv[i - 1][j - 1]
else:
len_vv[i][j] = max(len_vv[i - 1][j], len_vv[i][j - 1])
return float(float(len_vv[len_1][len_2] * 2) / float(len_1 + len_2))
for line in sys.stdin:
ss = line.strip().split(‘\t‘)
if len(ss) != 2:
continue
first_str = ss[0].strip()
second_str = ss[1].strip()
sim_score = cal_lcs_sim(first_str, second_str)
print ‘\t‘.join([first_str, second_str, str(sim_score)])
#run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH_1="/lcs_input.data"
OUTPUT_PATH="/lcs_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_FILE_PATH_1 -output $OUTPUT_PATH -mapper "python map.py" -jobconf "mapred.reduce.tasks=0" -jobconf "mapred.job.name=mr_lcs" -file ./map.py
mr_tfidf mapreduce
##red.py
#!/usr/bin/python
import sys
import math
current_word = None
count_pool = []
sum = 0
docs_cnt = 508
for line in sys.stdin:
ss = line.strip().split(‘\t‘)
if len(ss) != 2:
continue
word, val = ss
if current_word == None:
current_word = word
if current_word != word:
for count in count_pool:
sum += count
idf_score = math.log(float(docs_cnt) / (float(sum) + 1))
print "%s\t%s" % (current_word, idf_score)
current_word = word
count_pool = []
sum = 0
count_pool.append(int(val))
for count in count_pool:
sum += count
idf_score = math.log(float(docs_cnt) / (float(sum) + 1))
print "%s\t%s" % (current_word, idf_score)
##run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH_1="/tfidf_input.data"
OUTPUT_PATH="/tfidf_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_FILE_PATH_1 -output $OUTPUT_PATH -mapper "python map.py" -reducer "python red.py" -file ./map.py -file ./red.py
标签:查找 二维 trie树 特定 com cond 技术 大小 title
原文地址:https://www.cnblogs.com/hackerer/p/11456681.html