标签:程序 浏览器 session interface head _id 拼接 sele tps
1 分析
抓取人民日报里面的新闻详情 https://wap.peopleapp.com/news/1先打开,然后查看网页源码,发现是一堆js,并没有具体的每个新闻的url详情,于是第一反应,肯定是js动态加载拼接的url。
然后接着按f12 查看,就看url,发现出来了好多url然后点击具体的某一个新闻详情页面,查看url,把这个url的 后面两个数字其中一个拿到访问主页的时候,f12 抓包结果里面去查找,发现一个url,点击这个url,发现preview里面有好多数据,我第一反应,肯定是每个新闻数据了。看到这些数据里面有两个ID,联想到刚刚访问具体新闻详情页面也有两个数字,肯定,具体新闻页面肯定是 https://wap.peopleapp.com/article 加上两个ID形成的。于是试了一下拼接一个url访问,果然是。于是乎只要抓到这个url,就能获取到每个新闻的详情页了。
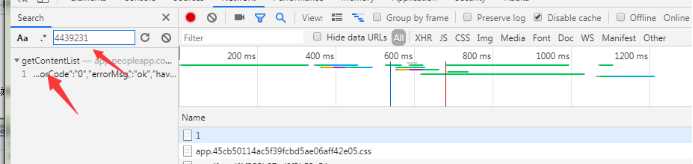
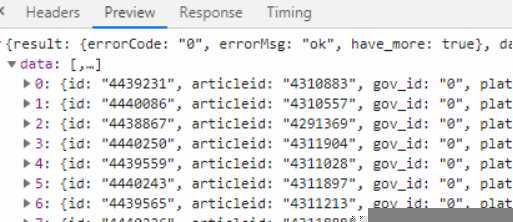
但这个抓到的url只加载了10条,我于是想改改里面的 show_num值,发现请求失败,仔细看这个url,有个securitykey 这个应该是js根据具体算法算出来的,看了一下那个拼接成url的js,发现看着有点头大,算了,只要我能一直抓这类url就就行了
发现只要我页面往下翻,就会新加载一条,于是我只要能解决两个问题:
1.往下翻页的问题,让这个数据url给加载出来
2.把这个url抓取到日志里面利用脚本访问,就能获取到数据了
查看了网上一些文档,最后决定用 python 的 selenium 这个模块,它是程序打开本地的浏览器进行操作,它里面有个方法execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) 就是下翻页的,利用这个就能一直把后面的 那个数据url给加载出来了。
第二个就是解决把这个数据url给抓出来,我就用fiddler来进行抓包(这里抓包工具,根据你们自己的选择,推荐一个:mitmproxy,这也是抓包神器,可以定制化抓包,比较方便,具体操作请百度、google)
我这里用fiddler,经常用这个,用着习惯。
二、使用fiddler进行抓包写入日志
1.fiddler 导出证书到浏览器
1.1.打开 tools-options
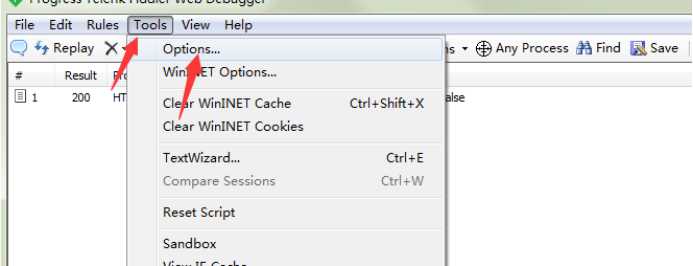
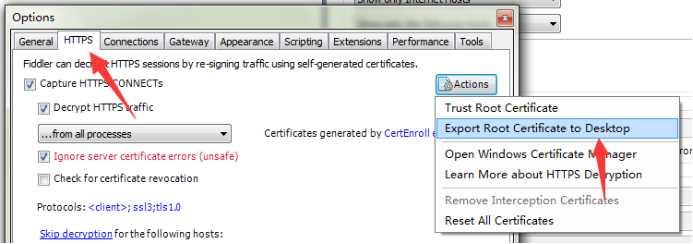
1.2.点击https-> actions -> export root certificate to desktop
1.3.打开浏览器(以火狐为例)
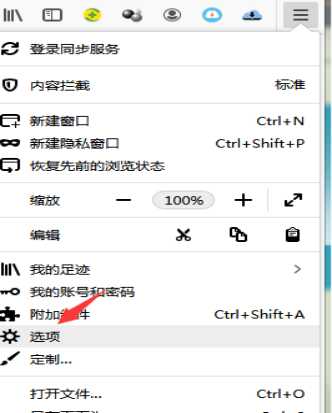
1.4.直接搜索”证书”,点击查看证书
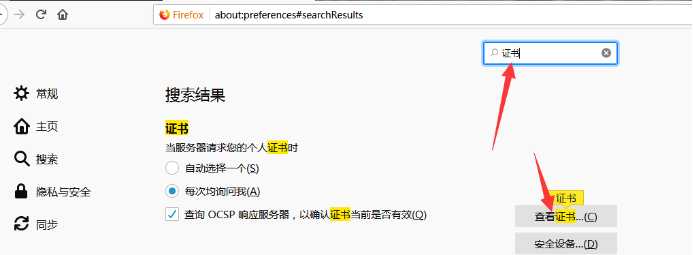
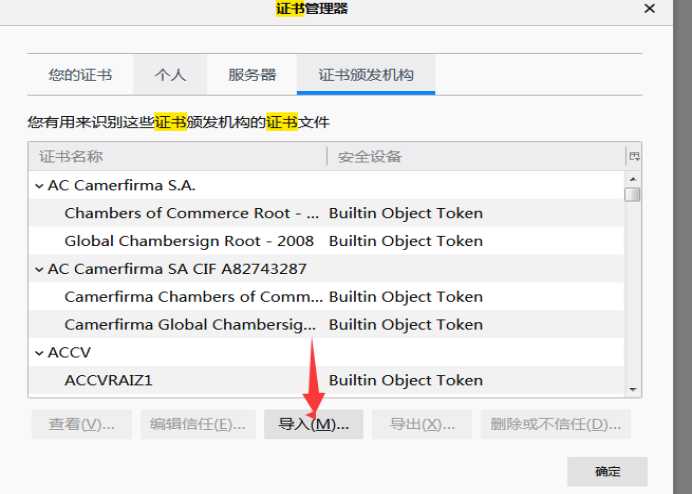
1.5.点击导入—选择刚才从fiddler导出的证书即可
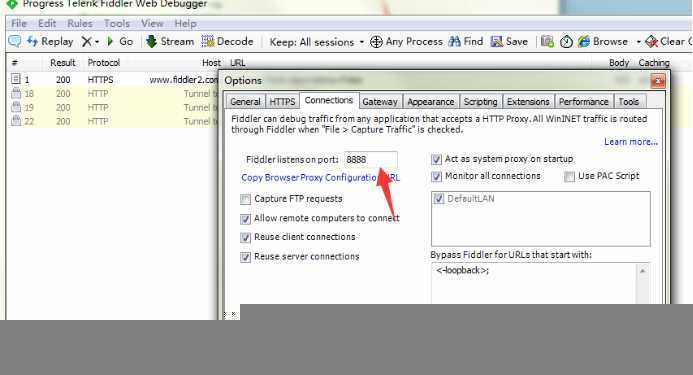
1.6.设置fiddler代理打开 tools-> options -> connections设置端口,默认8888
1.7.设置火狐浏览器去连接fiddler代理
找到网络设置,打开后,点击手动代理配置,填写ip,端口,勾选”为所有协议使用相同的代理服务器”

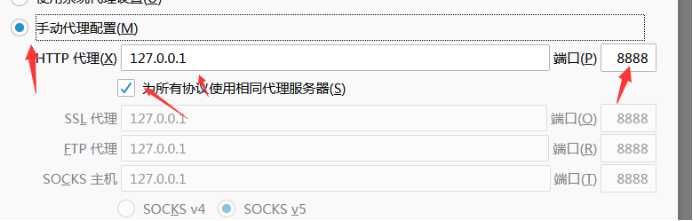
最后找一个https验证访问即可
fiddler 过滤(对动态抓取,可不设置,扩展学习)参考:https://www.cnblogs.com/sjl179947253/p/7627250.html
1.8. 打开 FiddlerScript,查找OnBeforeResponse 方法写入脚本
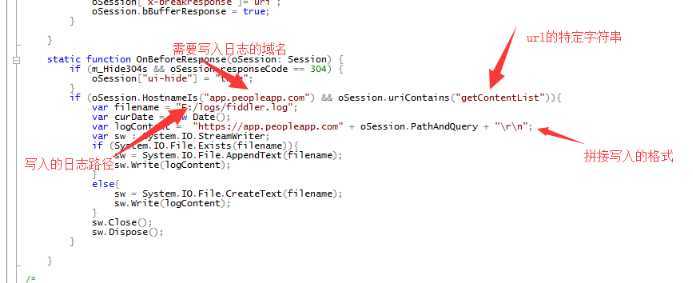
if (oSession.HostnameIs("app.peopleapp.com") && oSession.uriContains("getContentList")){
var filename = "F:/logs/fiddler.log";
var curDate = new Date();
var logContent = "https://app.peopleapp.com" + oSession.PathAndQuery + "\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}
三、 python 脚本读取fiddler日志,对最新的url进行获取内容,提取id拼接成新的新闻详情url
1.准备工作: 我这里用的是python3 先pip3 install selenium 安装模块 然后下载浏览器驱动,这下面有两个,google根据对应浏览器版本下载,firefox根据系统类型下载即可 #google 浏览器驱动下载地址 http://npm.taobao.org/mirrors/chromedriver/ #firefox 浏览器驱动下载地址 https://github.com/mozilla/geckodriver/releases/ 2.最后贴上脚本 3.from selenium import webdriver import time import requests as r import re import json #获取具体的新闻url,并写入文本 def get_news_url(search_time): #打开日志文件 file = open("F:/logs/fiddler.log","r") #最新一条url file_msg = file.readlines() #判断fiddler里面是否有url内容,若读取的内容列表等于0,则表示无内容 if len(file_msg) == 0: return "continue" #读取数组内容最后一位,即为最新的url url = file_msg[-1].strip("\n") print(url.strip("\n")) file.close() headers = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Cache-Control": "no-cache", "Connection": "keep-alive", "Cookie": "acw_tc=2760826c15644797526864019e11da63f32bf5b082a7da38667809b95819f3; SERVERID=f858eac9d6463aa503ba25948984ceb0|1564566072|1564566072", "Host": "app.peopleapp.com", "Pragma": "no-cache", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36" } #获取抓包的最新url数据 html = r.get(url,headers=headers).text #转换成json json_html = json.loads(html) #获取json的data数据 news_data_li = json_html["data"] #写入文件 news_file = open("F:/logs/news.log","a") #循环data数据,提取两个id,拼接成url,写入日志文件(这里可以根据实际情况,如对拼接成的url进行判断 分成具体的每个月进行写入日志等) for news in news_data_li: id = news["id"] articleid = news["articleid"] news_url = "https://wap.peopleapp.com/article/" + id + "/" + articleid print(news_url) news_file.write(news_url + "\n") news_file.close() #这一步只是用来控制的获取数据的时间,若传入的时间在数据内,则返回stop,停止,比如 只搜索 201904到现在的,就传入201904即可,这里根据具体需求改改就行 if re.search(search_time,html): return "continue" else: return "stop" #爬取动态页面url #google 浏览器驱动下载地址 http://npm.taobao.org/mirrors/chromedriver/ #firefox 浏览器驱动下载地址 https://github.com/mozilla/geckodriver/releases/ #browser = webdriver.Chrome(executable_path="D:\python37\chromedriver_win32\chromedriver.exe") #加载具体的浏览器驱动 browser = webdriver.Firefox(executable_path="D:\python37\geckodriver-v0.24.0-win64\geckodriver.exe") #设置浏览器需要访问的url browser.get("https://wap.peopleapp.com/news/1") #循环操作浏览器往下翻页 while True: #翻页脚本 browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) #翻页后,暂停1秒 time.sleep(1) #调用获取具体详情新闻页的url results = get_news_url("201907") #判断结果是否停止 if results == "stop": browser.quit() break
标签:程序 浏览器 session interface head _id 拼接 sele tps
原文地址:https://www.cnblogs.com/sailfan/p/11469922.html