标签:spi 调度 成都 一个 height 异步处理 核心 定义 nload
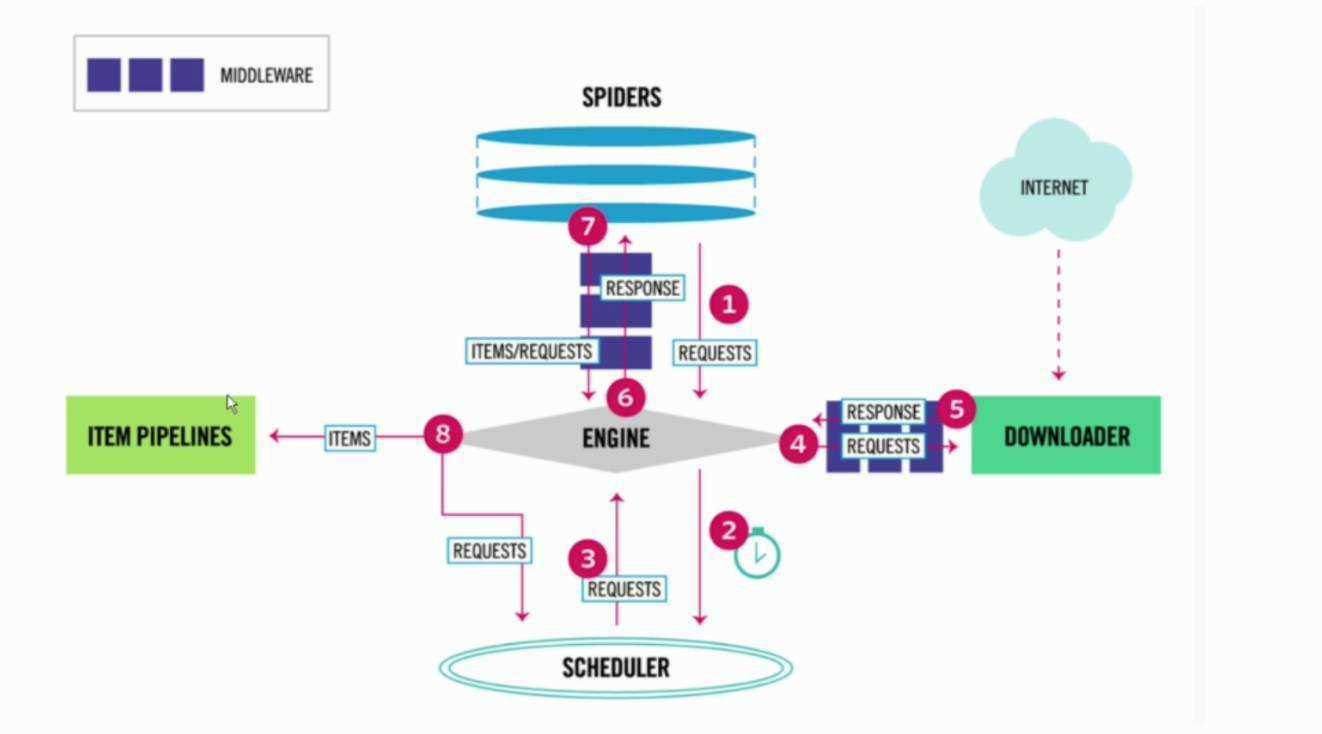
Scrapy 是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,其架构清晰模块之间的耦合成都低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
它可以分为如下几个部分。
Scrapy 框架的使用
原文地址:https://www.cnblogs.com/jeavy/p/11470455.html