标签:read 控制 深度 min node 没有 最大 code 搜索对象
3_2_XGBoost?应用
3_2_1_XGBoost参数
- 通用参数:控制整体功能;
- 提升器参数:在每一步控制单个提升器(tree、regression);
- 学习任务参数:控制最优化执行。
1.通用参数
booster [default=gbtree]
选择每次迭代的模型,有两个选择:
- gbtree:基于树的模型;
- gbliner:线性模型。
silent [default=0]
- 设置为1,静默模式被开启,不会显示运行信息;
- 通常设置为0,运行信息会更好的帮助理解模型。
nthread [default=最大可能的线程数]
- 该参数用以并行处理,应设置为系统内核数;
- 如果你希望使用所有内核,则不应设置该参数,算法会自动检测。
2.提升器参数
eta [default=0.3]
min_child_weight [default=1]
- 定义最小叶子节点样本权重和;
- 用于控制过拟合。较大的值可以避免模型学习到局部的特殊样本;
- 太大的值会导致欠拟合。
max_depth [default=6]
- 树的最大深度;
- 用于控制过拟合。较大的值模型会学到更具体更局部的样本;
- 典型值为3-10。
max_leaf_nodes
- 树中终端节点或叶子的最大数目;
- 可以代替max_depth参数。由于创建的是二叉树,一个深度为\(n\)的树最多生成\(2^n\)个叶子;
- 如果该参数被定义,max_depth参数将被忽略。
gamma [default=0]
- 只有在节点分裂后损失函数值下降,才会分裂该节点。gamma参数指定了节点分裂所需的最小损失函数下降值;
- 该参数的值越大,算法越保守。该参数的值和损失函数相关,所以是需要调整的。
max_delta_step [default=0]
- 该参数限制每棵树权重改变的最大步长。如果该参数为0,则表示没有约束。如果将其设置为正值,则使更新步骤更加保守;
- 通常该参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。
subsample [default=1]
- 该参数控制对于每棵树随机采样的比例;
- 减小该参数的值,算法会更加保守,避免过拟合。但是,如果该设置得过小,它可能会导致欠拟合;
- 典型值:0.5-1。
colsample_bytree [default=1]
- 该参数用来控制每棵随机采样的列数的占比(每一列是一个特征);
- 典型值:0.5-1。
colsample_bylevel [default=1]
- 该参数用来控制树的每一级的每一次分裂,对列数的采样的占比;
- 该参数和subsample参数可以起到相同的作用。
lambda [default=1]
alpha [default=0]
- 权重的L1正则化项。(类似于套索回归);
- 可以应用在很高维度的情况下,使得算法的速度更快。
scale_pos_weight [default=1]
- 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
3.学习任务参数
objective [default=reg:linear]
该参数定义需要被最小化的损失函数。常用值有:
- binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别);
- multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率)。在这种情况下,你还需要多设一个参数:num_class(类别数目);
- multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
eval_metric [ default according to objective ]
- 对于有效数据的度量方法;
- 对于回归问题,默认值是rmse,对于分类问题,默认值是error;
- 典型值:
- rmse 均方根误差
- mae 平均绝对误差
- logloss 负对数似然函数值
- error 二分类错误率(阈值为0.5)
- merror 多分类错误率
- mlogloss 多分类logloss损失函数
- auc 曲线下面积
seed [default=0]
- 随机数的种子
- 设置它可以复现随机数据的结果,也可以用于调整参数
3_2_2_XGBoost应用
导入XGBoost等相关包:
加载数据,提取特征集和标签:

将数据划分为训练集和测试集:


创建及训练模型:

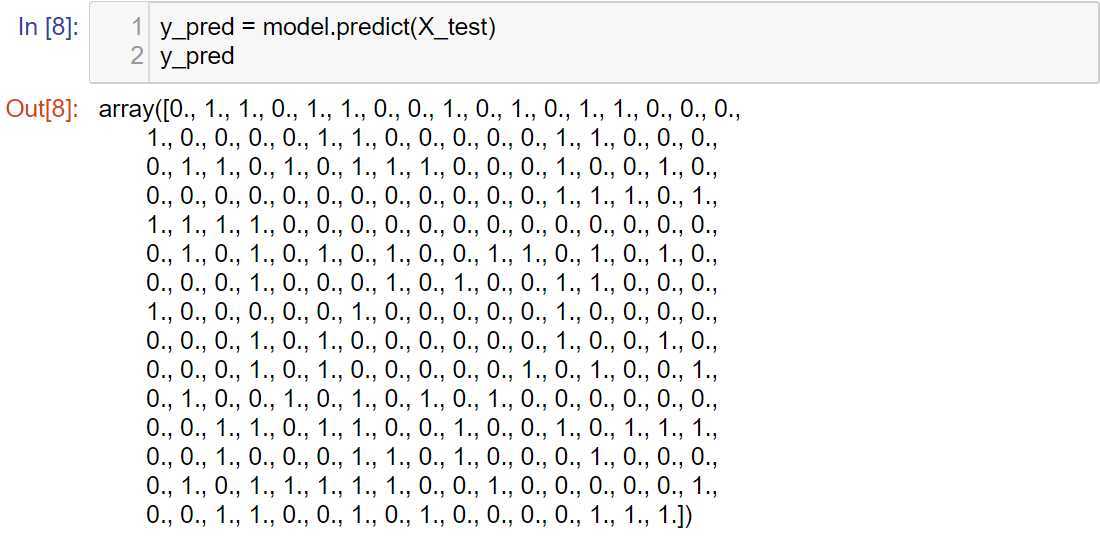
使用训练后的模型对测试集进行预测,并计算预测值与实际之间的acc值:

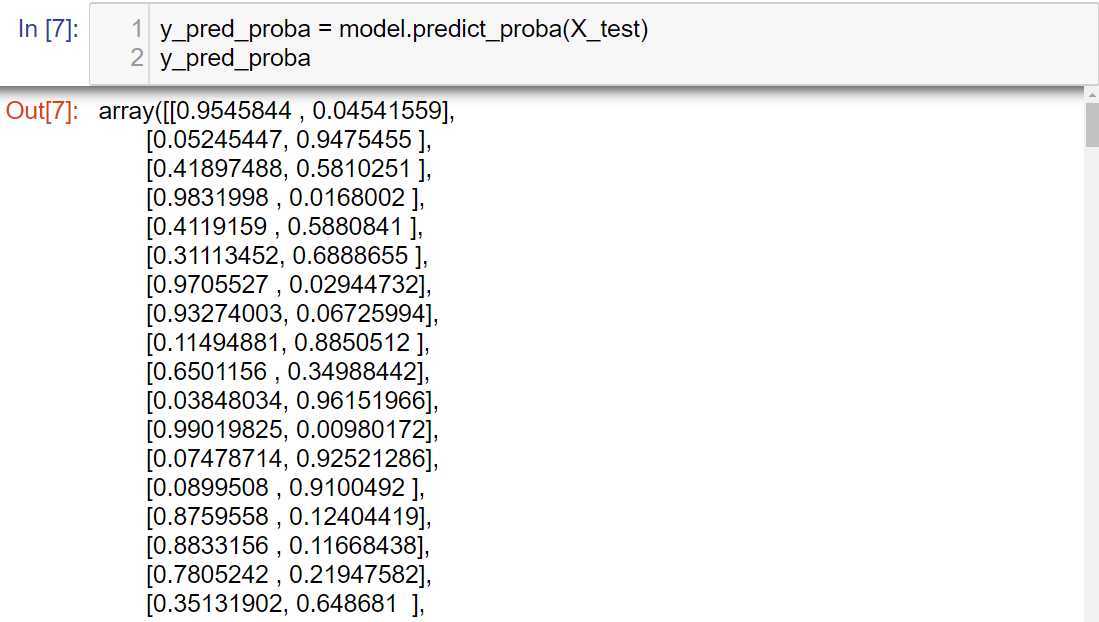
使用训练后的模型对测试集进行预测,得到每个类别的预测概率:
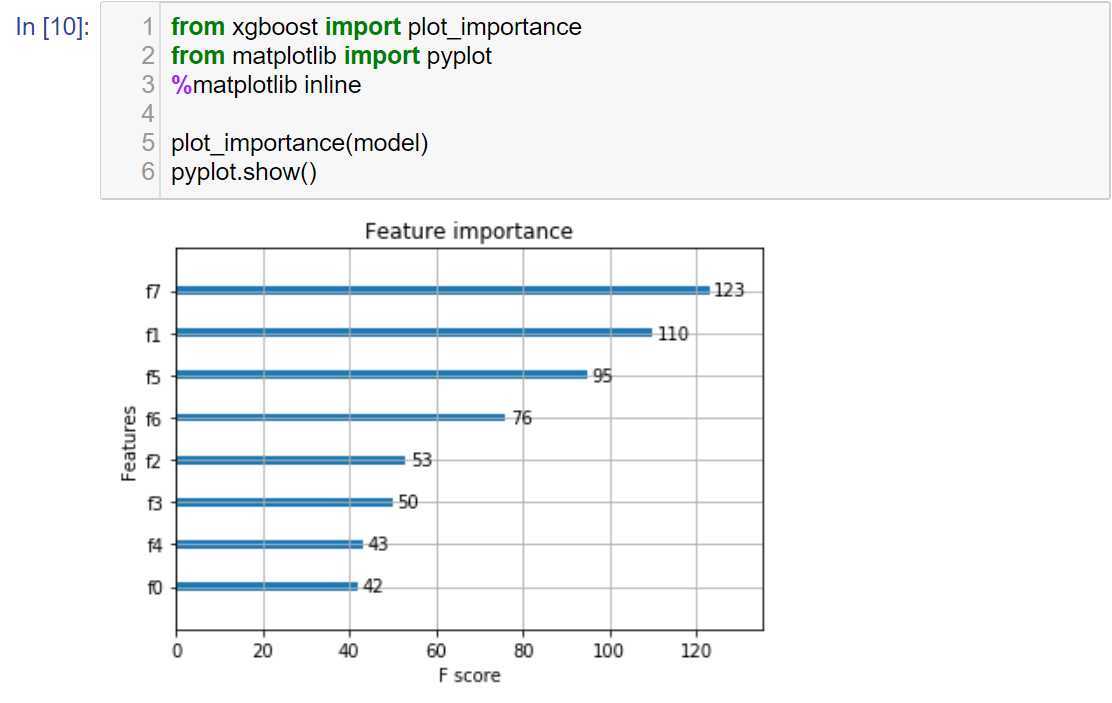
输出各特征重要程度:
导入调参相关包:

创建模型及参数搜索空间:

设置分层抽样验证及创建搜索对象:



参考:
七月在线集训营第八期课堂笔记
XGBoost应用
标签:read 控制 深度 min node 没有 最大 code 搜索对象
原文地址:https://www.cnblogs.com/WJZheng/p/11488493.html