标签:视觉 line 大致 语义 意义 org 效果 abs 质量
论文连接:https://arxiv.org/abs/1804.02958v1
一.简介
利用生成对抗网络进行图像压缩,其实就相当于用一个生成器代替了原来的decoder。decoder将编码后的图片恢复成原始图片,靠的是encoder生成的编码,所以生成图像的质量和码字的长度直接相关,这也就限制了编码率的进一步减小。本文的作者提出利用生成对抗网络作为decoder就是为了解决这个问题。编码过程中,不再对整个图像进行编码,而是只对其中的某一部分进行编码,然后恢复原始图像时,编码部分通过解码进行恢复,没有编码的部分则通过生成器G自动生成,这样就只需要对一部分图片进行编码,可以极大地提高压缩率。
二.网络结构
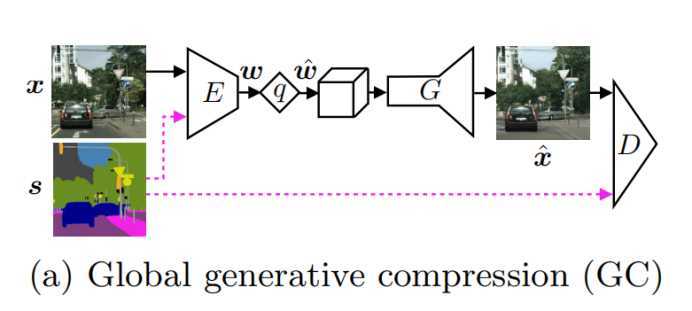
1.Global generative compression
具体的网络结构包括两种,第一种叫做Global generative compression(GC),这种方式适用于对整幅图像进行保存。其中哪一部分需要保存,哪一部分需要生成则由网络自己根据语义图以及优化目标自动选择。
这里的目标函数包含了三部分,前两个式子是GAN的目标函数,第三个式子是控制生成图片相对于原始图片的失真,最后一个式子是控制压缩率,可以通过调整β的大小来调整压缩率。
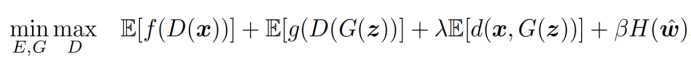
2.Selective generative compression
第二种结构叫做Selective generative compression(SC),这种结构一般用于某些特定场景下,比如在视频通话中,人们往往更注重的是视频中的人,而对于背景并不在意。所以只对人像部分进行编码,而背景部分则由生成器自动生成。对于哪一部分编码,哪一部分生成,则是通过一个二进制的图控制,需要生成的部分数值为0,需要保存的部分数值为1。
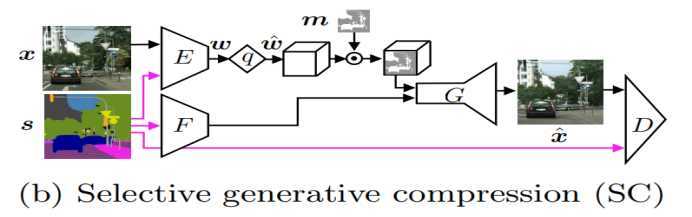
训练方式有两种,一种是随机选取每个训练图片中的25%进行保存,其余部分生成;另一种是设置一个固定尺寸的窗口,窗口内部保存,窗口外的部分生成。使用SC时的目标函数和GC大致相同,只不过在训练过程中,目标函数的第三部分,只对需要保存的区域进行计算,因为已经假定这一部分不重要。


三.评价标准
在当压缩率特别小的时候,用PSNR和SSIM来衡量图片质量已经没有意义。因为以PSNR为例,它更关心的是局部信息丢失了多少,而在压缩率趋近0的情况下,图像失真已经非常大,人们更关心的是图像的整体变化,而不再是局部的信息丢失,因此此时用PSNR来衡量图像质量意义不大。于是作者用mIoU来估计图片的质量,作者比较的是对压缩后的图像和原始图像进行语义分割后得到的图像的差异。
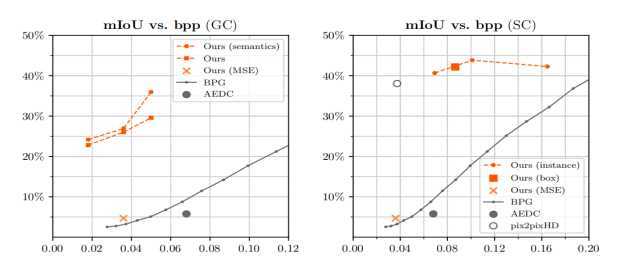
此外,作者还通过用户调查的方式来验证通过这种方式得到的压缩图像具有更好的视觉效果。

标签:视觉 line 大致 语义 意义 org 效果 abs 质量
原文地址:https://www.cnblogs.com/bupt213/p/11498033.html