标签:OLE 代码 group 排行榜 console etl set obj keyword
spark应用可以监听某一个目录,而web服务在这个目录上实时产生日志文件,这样对于spark应用来说,日志文件就是实时数据
Structured Streaming支持的文件类型有text,csv,json,parquet
●准备工作
在people.json文件输入如下数据:
{"name":"json","age":23,"hobby":"running"}
{"name":"charles","age":32,"hobby":"basketball"}
{"name":"tom","age":28,"hobby":"football"}
{"name":"lili","age":24,"hobby":"running"}
{"name":"bob","age":20,"hobby":"swimming"}
注意:文件必须是被移动到目录中的,且文件名不能有特殊字符
接下里使用Structured Streaming统计年龄小于25岁的人群的爱好排行榜
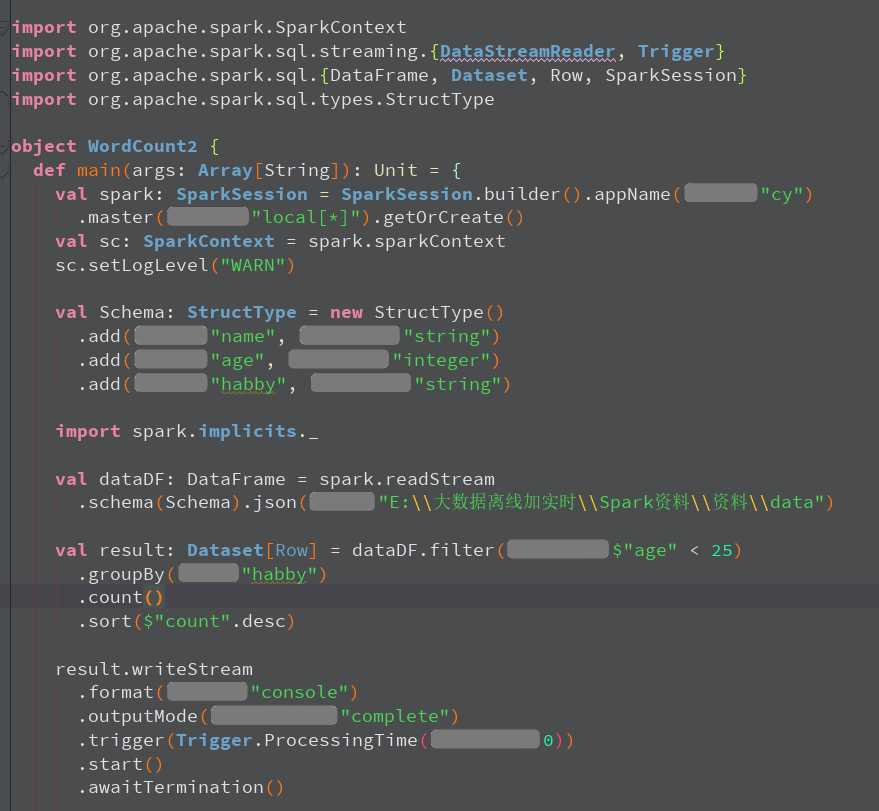
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* {"name":"json","age":23,"hobby":"running"}
* {"name":"charles","age":32,"hobby":"basketball"}
* {"name":"tom","age":28,"hobby":"football"}
* {"name":"lili","age":24,"hobby":"running"}
* {"name":"bob","age":20,"hobby":"swimming"}
* 统计年龄小于25岁的人群的爱好排行榜
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val Schema: StructType = new StructType()
.add("name","string")
.add("age","integer")
.add("hobby","string")
//2.接收数据
import spark.implicits._
// Schema must be specified when creating a streaming source DataFrame.
val dataDF: DataFrame = spark.readStream.schema(Schema).json("D:\\data\\spark\\data")
//3.处理数据
val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
//4.输出结果
result.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
}import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* {"name":"json","age":23,"hobby":"running"}
* {"name":"charles","age":32,"hobby":"basketball"}
* {"name":"tom","age":28,"hobby":"football"}
* {"name":"lili","age":24,"hobby":"running"}
* {"name":"bob","age":20,"hobby":"swimming"}
* 统计年龄小于25岁的人群的爱好排行榜
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val Schema: StructType = new StructType()
.add("name","string")
.add("age","integer")
.add("hobby","string")
//2.接收数据
import spark.implicits._
// Schema must be specified when creating a streaming source DataFrame.
val dataDF: DataFrame = spark.readStream.schema(Schema).json("D:\\data\\spark\\data")
//3.处理数据
val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc)
//4.输出结果
result.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
}
Structured Streaming 实战案例 读取文本数据
标签:OLE 代码 group 排行榜 console etl set obj keyword
原文地址:https://www.cnblogs.com/TiePiHeTao/p/e83029055db1b4a602e15785b2d079c1.html